一、基本流程


二、logisticRegression的常用方法
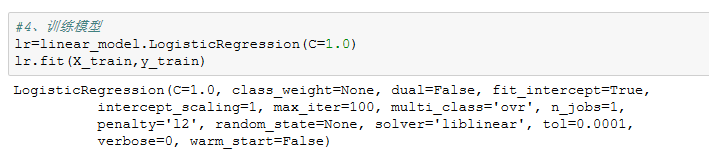
1、fit(X_train,y_train,sample_weight=None)
拟合模型,用来训练LR分类器,返回值是self
2、fit_transform(X,y=None)
先fit后transform,返回X_new,nump矩阵
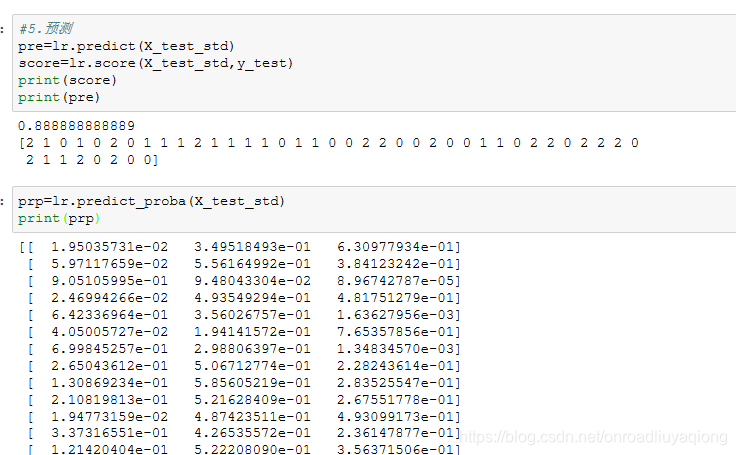
3、predict(X_test)
用来预测样本,返回array
4、predict_proba(X)
输出分类的概率,返回每种类别的概率,按照分类类别一次给出。如果是多分类问题,multi_class=‘multinormail’,给出样本对应每种类别的概率,返回array_like。
5、score(X,y,sample_weight=None)
返回给定测试集合的平均准确率,浮点型数值。
对于多个分类返回,返回每个类别的准确率组成的哈希矩阵
三、LogisticRegression中的参数
class sklearn.linear_model.LogisticRegression(penalty=‘l2’,
dual=False, tol=0.0001, C=1.0, fit_intercept=True,
intercept_scaling=1, class_weight=None,
random_state=None, solver=‘liblinear’, max_iter=100,
multi_class=‘ovr’, verbose=0, warm_start=False, n_jobs=1)
1、penalty:惩罚项,可以为L1或L2, netton-cg、sag与lbfgs只支持L2。
L1正则化的损失函数不是连续可导的,而netton-cg,sag,lbfgs这三种算法需要损失函数的一阶或二阶连续可导。
调参主要是为了解决过拟合问题,选择L2就够了,若L2还是过拟合,可以选择L1
若模型特征非常多,希望一些不重要的特征系数为0,可以选择L1
2、dual:选择目标函数是原始形式还是对偶形式
将原始函数转化为一个新函数,新函数称为对偶函数,对偶函数更易于优化。
Dual只适用于正则化相为l2的‘liblinear’的情况,通常样本数大于特征数的情况下,默认为False。
3、tol:优化算法停止时的条件,
当迭代前后的函数差值小于等于tol时就停止
4、C:为正则化系数λ的倒数,必须为正数,默认为1。值越小,正则化越强
5、fit_intercept:选择逻辑回归模型中是否带有常数项b
6、Intercept_scaling=1:仅在正则化项为liblinear,且fit_intercept=True时有用。
7、class_weight:用于标识分类模型中各种类型的权重,‘class_label:weight’ or ‘balanced’
balanced根据训练样本量来计算权重,某种类型的样本量越多,则权重越低
若误分类代价很高,如对合法用户与非法用户分类,可适当提高非法用户权重
样本高度失衡的,可用balanced,自动提高类别的权重
8、random_state:随机种子数
9、solver:损失函数的优化方法
liblinear:使用坐标轴下降法来迭代优化算是函数
lbfgs:拟牛顿法的一种,利用损失函数二阶导数矩阵即海森矩阵来迭代优化损失函数
newton-cg:牛顿法的一种,同上。
sag:随机平均梯度下降,每次迭代仅仅用一部分的样本来计算梯度,适合于样本数据多的时候。
多元逻辑回归有Ovr(one-vs-rest)和Mvm(many-vs-many),而Mvm比Ovr更准确一点,但liblinear只支持Ovr
10、max_iter:优化算法的迭代次数
11、multi_class:‘Ovr’ or ‘multinomail’,'multinomail’即Mvm
若是二元回归,两者差异不大。
对于Mvm,若模型有T类,每次在所有的T类样本里面选择两类样本出来,把所有输出为该两类的样本放在一起,进行二元回归,得到模型参数,一共需要T(T-1)/2次分类。
Ovr相对简单,但分类效果略差,Mvm分类相对精确但分类速度没有Ovr快。
如果选择了ovr,则4种损失函数的优化方法liblinear,newton-cg,lbfgs和sag都可以选择。但是如果选择了multinomial,则只能选择newton-cg, lbfgs和sag了。
12、verbose:控制是否print训练过程。日志冗长度int,0,不输出训练过程;1,偶尔输出,>1,对每个子模型都输出。
13、warm-start:是否热启动,如果是,下一次训练是以追加树的形式进行(重新使用上一次的调用作为初始化),布尔型,默认FALSE。
14、n_jobs:cpu的几个核来跑这个模型,并行数,int:个数;-1:跟CPU核数一致;1:默认值。
参考文章:
https://www.cnblogs.com/sddai/p/9571305.html