介绍
快餐分类已成为自动化送餐系统中的一项重要任务。随着快餐连锁店的发展以及对准确高效的食品识别系统的需求,机器学习变得流行起来。
在这篇博客中,我们将探索使用 PyTorch 将迁移学习用于快餐分类。迁移学习是一种利用预训练模型用有限数据解决新任务的技术。

我们将讨论如何微调用于快餐分类的预训练模型以及从该方法获得的结果。
学习目标
了解用于深度学习的 PyTorch
如何在 PyTorch 中使用迁移学习?
数据扩充
可视化模型
目录
什么是迁移学习?
数据说明
编码实现
什么是迁移学习?
迁移学习是一种利用深度学习模型的预训练权重在有限数据下执行新任务的技术。
在ResNet18(我将在本项目中使用)的上下文中,迁移学习将涉及采用预训练的 ResNet18 模型并针对特定的快餐分类任务微调其权重。这种方法旨在利用预训练模型在大型数据集上学到的知识,以更少的数据和计算资源来解决新任务。微调过程通常涉及重新训练 ResNet18 模型的最后几层以使其适应新任务。
下面是resnet18模型图。
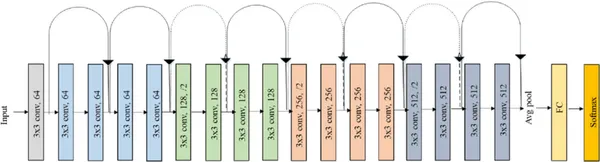
你可以看到该模型由 17 层带有 3 * 3 过滤器的卷积层和一层全连接层组成。最后是用于多类图像分类的 Softmax 函数。
数据说明
数据集:https://www.kaggle.com/datasets/utkarshsaxenadn/fast-food-classification-dataset
有 10 个类别的快餐图像。
Burger
Donut
Hot Dog
Pizza
Sandwich
Baked Potato
Crispy Chicken
Fries
Taco
Taquito
编码实现
第 1 步:导入所有必要的库
from __future__ import print_function, division
import torch
import torch.nn as nn
import torch.optim as optim
from torch.optim import lr_scheduler
import torch.backends.cudnn as cudnn
import numpy as np
import torchvision
from torchvision import datasets, models, transforms
import matplotlib.pyplot as plt
import time
import os
import copy第 2 步:设置数据集和设备的路径
PATH = "../data/Fast Food Classification V2/"
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
# make sure my GPU is detected.
print(device)第 3 步:数据扩充和归一化
数据增强是深度学习中用于增加训练数据集大小并防止过度拟合的关键技术。它可以帮助提高深度学习模型的性能和鲁棒性,尤其是在数据有限的场景中。
data_transforms = {
'Train': transforms.Compose([
transforms.RandomResizedCrop(224),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
]),
'Valid': transforms.Compose([
transforms.Resize(256),
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
]),
}第 4 步:加载Dataset并创建Dataloader对象
image_datasets = {
x: datasets.ImageFolder(os.path.join(PATH, x),
data_transforms[x]) for x in ['Train', 'Valid']
}
dataloaders = {
x: torch.utils.data.DataLoader(image_datasets[x],
batch_size=32,
shuffle=True,
) for x in ['Train', 'Valid']
}
dataset_sizes = {x: len(image_datasets[x]) for x in ['Train', 'Valid']}
class_names = image_datasets['Train'].classes
print(classes)
>>>
['Baked Potato',
'Burger',
'Crispy Chicken',
'Donut',
'Fries',
'Hot Dog',
'Pizza',
'Sandwich',
'Taco',
'Taquito']让我们看一些训练数据。
# create a function image show
def imshow(inp, title=None):
inp = inp.numpy().transpose((1, 2, 0))
mean = np.array([0.485, 0.456, 0.406])
std = np.array([0.229, 0.224, 0.225])
inp = std * inp + mean
inp = np.clip(inp, 0, 1)
plt.imshow(inp)
if title is not None:
plt.title(title)
plt.pause(0.001)
# Get a batch of training data
inputs, classes = next(iter(dataloaders['Train']))
# Make a grid from batch
out = torchvision.utils.make_grid(inputs)
imshow(out)
第 5 步:创建训练函数
该函数采用以下输入:
Model:要训练的深度学习模型。
Criterion:用于评估模型性能的损失函数。
Optimizer:优化算法在训练期间更新模型的参数。
Scheduler:学习率调度器,用于在训练期间调整学习率。
num_epochs:训练时期的数量(默认值 = 25)。
该函数训练模型num_epochs个时期,在训练和验证阶段之间交替。在每个时期,模型的参数都使用优化器和计算损失的标准进行更新。
在训练阶段,使用backward()计算梯度,并使用 optimizer.step() 更新参数。在不更新参数的情况下,在验证阶段评估模型的性能。
在每个时期之后,打印性能指标(损失和准确性)。使用copy.deepcopy() 保存最佳模型权重(具有最高验证精度)。
在训练结束时,打印经过的时间和最佳验证准确度,并使用 model.load_state_dict () 加载最佳模型权重。最后返回训练好的模型。
def train_model(model, criterion, optimizer, scheduler, num_epochs=25):
since = time.time()
best_model_wts = copy.deepcopy(model.state_dict())
best_acc = 0.0
for epoch in range(num_epochs):
print(f'Epoch {epoch}/{num_epochs - 1}')
print('-' * 10)
# Each epoch has a training and validation phase
for phase in ['Train', 'Valid']:
if phase == 'Train':
model.train() # Set model to training mode
else:
model.eval() # Set model to evaluate mode
running_loss = 0.0
running_corrects = 0
# Iterate over data.
for inputs, labels in dataloaders[phase]:
inputs = inputs.to(device)
labels = labels.to(device)
# zero the parameter gradients
optimizer.zero_grad()
# forward
# track history if only in train
with torch.set_grad_enabled(phase == 'Train'):
outputs = model(inputs)
_, preds = torch.max(outputs, 1)
loss = criterion(outputs, labels)
# backward + optimize only if in training phase
if phase == 'Train':
loss.backward()
optimizer.step()
# statistics
running_loss += loss.item() * inputs.size(0)
running_corrects += torch.sum(preds == labels.data)
if phase == 'Train':
scheduler.step()
epoch_loss = running_loss / dataset_sizes[phase]
epoch_acc = running_corrects.double() / dataset_sizes[phase]
print(f'{phase} Loss: {epoch_loss:.4f} Acc: {epoch_acc:.4f}')
# deep copy the model
if phase == 'Valid' and epoch_acc > best_acc:
best_acc = epoch_acc
best_model_wts = copy.deepcopy(model.state_dict())
print()
time_elapsed = time.time() - since
print(f'Training complete in {time_elapsed // 60:.0f}m {time_elapsed % 60:.0f}s')
print(f'Best Valid Acc: {best_acc:4f}')
# load best model weights
model.load_state_dict(best_model_wts)
return model第 6 步:开始使用 Resnet18 权重训练模型
model_1 = models.resnet18(pretrained=True)
num_ftrs = model_1.fc.in_features
# Here the size of each output sample is set to 2.
# Alternatively, it can be generalized to nn.Linear(num_ftrs, len(class_names)).
model_1.fc = nn.Linear(num_ftrs, len(class_names))
model_1 = model_1.to(device)
criterion = nn.CrossEntropyLoss()
# Observe that all parameters are being optimized
optimizer_sgd = optim.SGD(model_1.parameters(), lr=0.001, momentum=0.9)
optimizer_adam = optim.Adam(model_1.parameters(), lr=0.001)
# Decay LR by a factor of 0.1 every 7 epochs
exp_lr_scheduler = lr_scheduler.StepLR(optimizer_adam, step_size=7, gamma=0.1)
model_resnetft = train_model(model_1, criterion, optimizer_adam, exp_lr_scheduler,
num_epochs=15)
output >>>
Epoch 0/14
----------
Train Loss: 1.3397 Acc: 0.5660
Valid Loss: 1.0503 Acc: 0.6691
.
.
.
continues
.
.
.
Epoch 14/14
----------
Train Loss: 0.4054 Acc: 0.8709
Valid Loss: 0.4723 Acc: 0.8600
Training complete in 27m 23s
Best Valid Acc: 0.867714因此,你可以看到在 Nvidia Tesla P100 的 GPU 中完成训练需要将近 28 分钟。最佳验证准确度得分为 86.77%。
第 7 步:现在看一些结果
该代码首先将模型设置为评估模式 ( model.eval() ) 并初始化一个计数器images_so_far,以跟踪到目前为止可视化的图像数量。还使用plt.figure()创建了一个图形。
然后该函数使用 enumerate( dataloaders['Valid'] )迭代验证数据。对于每次迭代,将输入图像和标签移动到指定设备(使用inputs.to(device)和labels.to(device)) ,并使用model(inputs)计算模型的预测。使用 _, preds = torch.max(outputs, 1) 获得每个图像的预测类别。
对于每个输入图像,代码使用imshow(inputs.cpu().data[j])绘制图像并将标题设置为预测类。该代码使用计数器images_so_far跟踪到目前为止可视化的图像数量,如果可视化的图像数量等于指定数量,则函数返回。
最后,代码使用model.train(mode=was_training)将模型设置回其原始训练模式。
def visualize_model(model, num_images=6):
was_training = model.training
model.eval()
images_so_far = 0
fig = plt.figure()
with torch.no_grad():
for i, (inputs, labels) in enumerate(dataloaders['Valid']):
inputs = inputs.to(device)
labels = labels.to(device)
outputs = model(inputs)
_, preds = torch.max(outputs, 1)
for j in range(inputs.size()[0]):
images_so_far += 1
ax = plt.subplot(num_images//2, 2, images_so_far)
ax.axis('off')
ax.set_title(f'predicted: {class_names[preds[j]]}')
imshow(inputs.cpu().data[j])
if images_so_far == num_images:
model.train(mode=was_training)
return
model.train(mode=was_training)
# Visualize model
visualize_model(model_1)




结论
本文演示了如何使用迁移学习使用 ResNet18 架构和 PyTorch 执行快餐分类。该实施展示了如何微调食品数据集上的预训练模型并评估模型在验证集上的性能。
结果表明,迁移学习可以有效地利用从大规模数据集中学习到的知识来提高食品分类任务的性能。总的来说,迁移学习是解决计算机视觉问题的有力工具,并有可能彻底改变该领域。
以下是从这个项目中学到的一些关键知识:
ResNet18 是计算机视觉任务中常用的深度学习架构,可用作迁移学习中的特征提取器。
迁移学习是深度学习中的一种技术,它针对特定任务对预训练模型进行微调。
代码实现展示了如何在食物数据集上微调预训练的 ResNet18 模型并评估模型在验证集上的性能。
数据增强技术增加了训练数据集的大小并提高了模型的性能。
结果表明,使用 ResNet18 和 PyTorch 的迁移学习可以有效地对快餐图像进行分类并获得较高的准确率。
迁移学习是解决计算机视觉问题的强大工具,有可能彻底改变该领域。
☆ END ☆
如果看到这里,说明你喜欢这篇文章,请转发、点赞。微信搜索「uncle_pn」,欢迎添加小编微信「 woshicver」,每日朋友圈更新一篇高质量博文。
↓扫描二维码添加小编↓
