目录
1.ResNet残差网络
1.1 ResNet定义
深度学习在图像分类、目标检测、语音识别等领域取得了重大突破,但是随着网络层数的增加,梯度消失和梯度爆炸问题逐渐凸显。随着层数的增加,梯度信息在反向传播过程中逐渐变小,导致网络难以收敛。同时,梯度爆炸问题也会导致网络的参数更新过大,无法正常收敛。
为了解决这些问题,ResNet提出了一个创新的思路:引入残差块(Residual Block)。残差块的设计允许网络学习残差映射,从而减轻了梯度消失问题,使得网络更容易训练。
下图是一个基本残差块。它的操作是把某层输入跳跃连接到下一层乃至更深层的激活层之前,同本层输出一起经过激活函数输出。
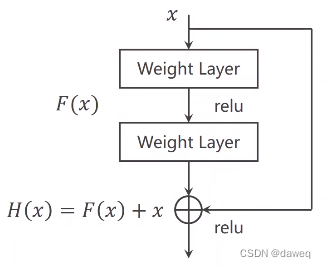
1.2 ResNet 几种网络配置
如下图:

1.3 ResNet50网络结构
ResNet-50是一个具有50个卷积层的深度残差网络。它的网络结构非常复杂,但我们可以将其分为以下几个模块:
1.3.1 前几层卷积和池化
import torch
import torch.nn as nn
class ResNet50(nn.Module):
def __init__(self, num_classes=1000):
super(ResNet50, self).__init__()
self.conv1 = nn.Conv2d(in_channels=3, out_channels=64, kernel_size=7, stride=2, padding=3, bias=False)
self.bn1 = nn.BatchNorm2d(64)
self.relu = nn.ReLU(inplace=True)
self.maxpool = nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
1.3.2 残差块:构建深度残差网络
class ResidualBlock(nn.Module):
def __init__(self, in_channels, out_channels, stride=1, downsample=None):
super(ResidualBlock, self).__init__()
self.conv1 = nn.Conv2d(in_channels, out_channels, kernel_size=1, stride=stride, bias=False)
self.bn1 = nn.BatchNorm2d(out_channels)
self.conv2 = nn.Conv2d(out_channels, out_channels, kernel_size=3, stride=1, padding=1, bias=False)
self.bn2 = nn.BatchNorm2d(out_channels)
self.conv3 = nn.Conv2d(out_channels, out_channels * 4, kernel_size=1, stride=1, bias=False)
self.bn3 = nn.BatchNorm2d(out_channels * 4)
self.relu = nn.ReLU(inplace=True)
self.downsample = downsample
def forward(self, x):
identity = x
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
out = self.conv2(out)
out = self.bn2(out)
out = self.relu(out)
out = self.conv3(out)
out = self.bn3(out)
if self.downsample is not None:
identity = self.downsample(x)
out += identity
out = self.relu(out)
return out
1.3.3 ResNet主体:堆叠多个残差块
在ResNet-50中,我们堆叠了多个残差块来构建整个网络。每个残差块会将输入的特征图进行处理,并输出更加丰富的特征图。堆叠多个残差块允许网络在深度方向上进行信息的层层提取,从而获得更高级的语义信息。代码如下:
class ResNet50(nn.Module):
def __init__(self, num_classes=1000):
# ... 前几层代码 ...
# 4个残差块的block1
self.layer1 = self._make_layer(ResidualBlock, 64, 3, stride=1)
# 4个残差块的block2
self.layer2 = self._make_layer(ResidualBlock, 128, 4, stride=2)
# 4个残差块的block3
self.layer3 = self._make_layer(ResidualBlock, 256, 6, stride=2)
# 4个残差块的block4
self.layer4 = self._make_layer(ResidualBlock, 512, 3, stride=2)
利用make_layer函数实现对基本残差块Bottleneck的堆叠。代码如下:
def _make_layer(self, block, channel, block_num, stride=1):
"""
block: 堆叠的基本模块
channel: 每个stage中堆叠模块的第一个卷积的卷积核个数,对resnet50分别是:64,128,256,512
block_num: 当期stage堆叠block个数
stride: 默认卷积步长
"""
downsample = None # 用于控制shorcut路的
if stride != 1 or self.in_channel != channel*block.expansion: # 对resnet50:conv2中特征图尺寸H,W不需要下采样/2,但是通道数x4,因此shortcut通道数也需要x4。对其余conv3,4,5,既要特征图尺寸H,W/2,又要shortcut维度x4
downsample = nn.Sequential(
nn.Conv2d(in_channels=self.in_channel, out_channels=channel*block.expansion, kernel_size=1, stride=stride, bias=False), # out_channels决定输出通道数x4,stride决定特征图尺寸H,W/2
nn.BatchNorm2d(num_features=channel*block.expansion))
layers = [] # 每一个convi_x的结构保存在一个layers列表中,i={2,3,4,5}
layers.append(block(in_channel=self.in_channel, out_channel=channel, downsample=downsample, stride=stride)) # 定义convi_x中的第一个残差块,只有第一个需要设置downsample和stride
self.in_channel = channel*block.expansion # 在下一次调用_make_layer函数的时候,self.in_channel已经x4
for _ in range(1, block_num): # 通过循环堆叠其余残差块(堆叠了剩余的block_num-1个)
layers.append(block(in_channel=self.in_channel, out_channel=channel))
return nn.Sequential(*layers) # '*'的作用是将list转换为非关键字参数传入
1.4 迁移学习猫狗二分类实战
1.4.1 迁移学习
迁移学习(Transfer Learning)是一种机器学习和深度学习技术,它允许我们将一个任务学到的知识或特征迁移到另一个相关的任务中,从而加速模型的训练和提高性能。在迁移学习中,我们通常利用已经在大规模数据集上预训练好的模型(称为源任务模型),将其权重用于新的任务(称为目标任务),而不是从头开始训练一个全新的模型。
迁移学习的核心思想是:在解决一个新任务之前,我们可以先从已经学习过的任务中获取一些通用的特征或知识,并将这些特征或知识迁移到新任务中。这样做的好处在于,源任务模型已经在大规模数据集上进行了充分训练,学到了很多通用的特征,例如边缘检测、纹理等,这些特征对于许多任务都是有用的。
1.4.2 模型训练
首先,我们需要准备用于猫狗二分类的数据集。数据集可以从Kaggle上下载,其中包含了大量的猫和狗的图片。
在下载数据集后,我们需要将数据集划分为训练集和测试集。训练集文件夹命名为train,其中建立两个文件夹分别为cat和dog,每个文件夹里存放相应类别的图片。测试集命名为test,同理。然后我们使用ResNet50网络模型,在我们的计算机上使用GPU进行训练并保存我们的模型,训练完成后在测试集上验证模型预测的正确率。
import torch
import torch.nn as nn
import torch.optim as optim
import torchvision.transforms as transforms
from torch.utils.data import DataLoader, Dataset
from torchvision.datasets import ImageFolder
from torchvision.models import resnet50
# 设置随机种子
torch.manual_seed(42)
# 定义超参数
batch_size = 32
learning_rate = 0.001
num_epochs = 10
# 定义数据转换
transform = transforms.Compose([
transforms.Resize((224, 224)),
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))
])
# 加载数据集
train_dataset = ImageFolder("train", transform=transform)
test_dataset = ImageFolder("test", transform=transform)
train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True)
test_loader = DataLoader(test_dataset, batch_size=batch_size)
# 加载预训练的ResNet-50模型
model = resnet50(pretrained=True)
num_ftrs = model.fc.in_features
model.fc = nn.Linear(num_ftrs, 2) # 替换最后一层全连接层,以适应二分类问题
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model.to(device)
# 定义损失函数和优化器
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(model.parameters(), lr=learning_rate, momentum=0.9)
# 训练模型
total_step = len(train_loader)
for epoch in range(num_epochs):
for i, (images, labels) in enumerate(train_loader):
images = images.to(device)
labels = labels.to(device)
# 前向传播
outputs = model(images)
loss = criterion(outputs, labels)
# 反向传播和优化
optimizer.zero_grad()
loss.backward()
optimizer.step()
if (i + 1) % 100 == 0:
print(f"Epoch [{epoch+1}/{num_epochs}], Step [{i+1}/{total_step}], Loss: {loss.item()}")
torch.save(model,'model/c.pth')
# 测试模型
model.eval()
with torch.no_grad():
correct = 0
total = 0
for images, labels in test_loader:
images = images.to(device)
labels = labels.to(device)
outputs = model(images)
print(outputs)
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
break
print(f"Accuracy on test images: {(correct / total) * 100}%")
1.4.3 模型预测
首先加载我们保存的模型,这里我们进行单张图片的预测,并把预测结果打印日志。
import cv2 as cv
import matplotlib.pyplot as plt
import matplotlib.image as mpimg
import torchvision.transforms as transforms
import torch
from PIL import Image
import os
os.environ['KMP_DUPLICATE_LIB_OK'] = 'TRUE'
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model=torch.load('model/c.pth')
print(model)
model.to(device)
test_image_path = 'test/dogs/dog.4001.jpg' # Replace with your test image path
image = Image.open(test_image_path)
transform = transforms.Compose([
transforms.Resize((224, 224)),
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))
])
input_tensor = transform(image).unsqueeze(0).to(device) # Add a batch dimension and move to GPU
# Set the model to evaluation mode
model.eval()
with torch.no_grad():
outputs = model(input_tensor)
_, predicted = torch.max(outputs, 1)
predicted_label = predicted.item()
label=['猫','狗']
print(label[predicted_label])
plt.axis('off')
plt.imshow(image)
plt.show()
运行截图
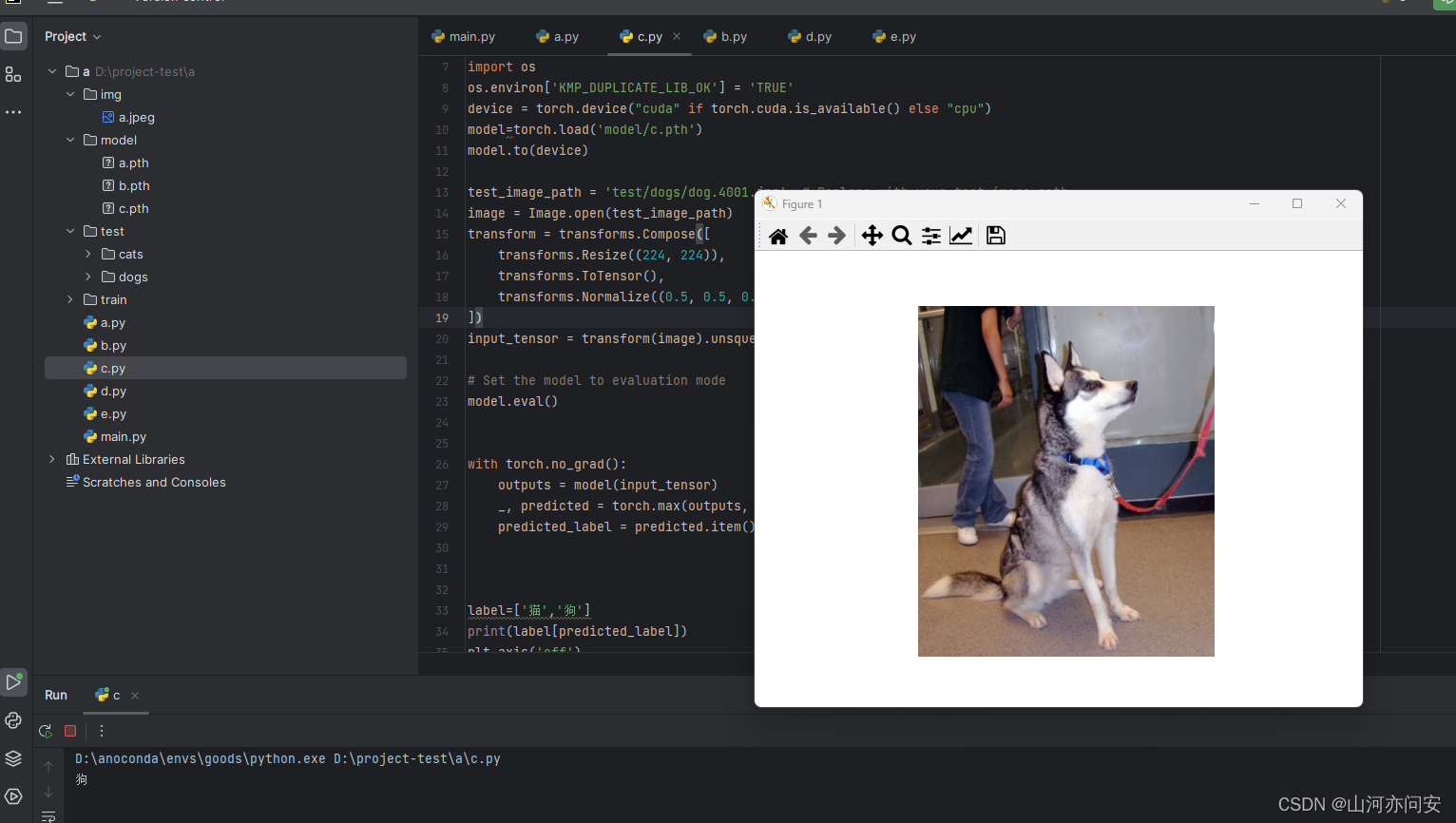
至此这篇文章到此结束。