
文章目录
1.Tensorboard 简介
Tensorboard是tensorflow内置的一个可视化工具,它通过将tensorflow程序输出的日志文件的信息可视化,使得tensorflow程序的理解、调试和优化更加简单高效。它可以帮助我们理解整个神经网络的学习过程、数据的分布、性能瓶颈等等。
官方网址:https://tensorflow.google.cn/tensorboard
TensorBoard 提供机器学习实验所需的可视化功能和工具:
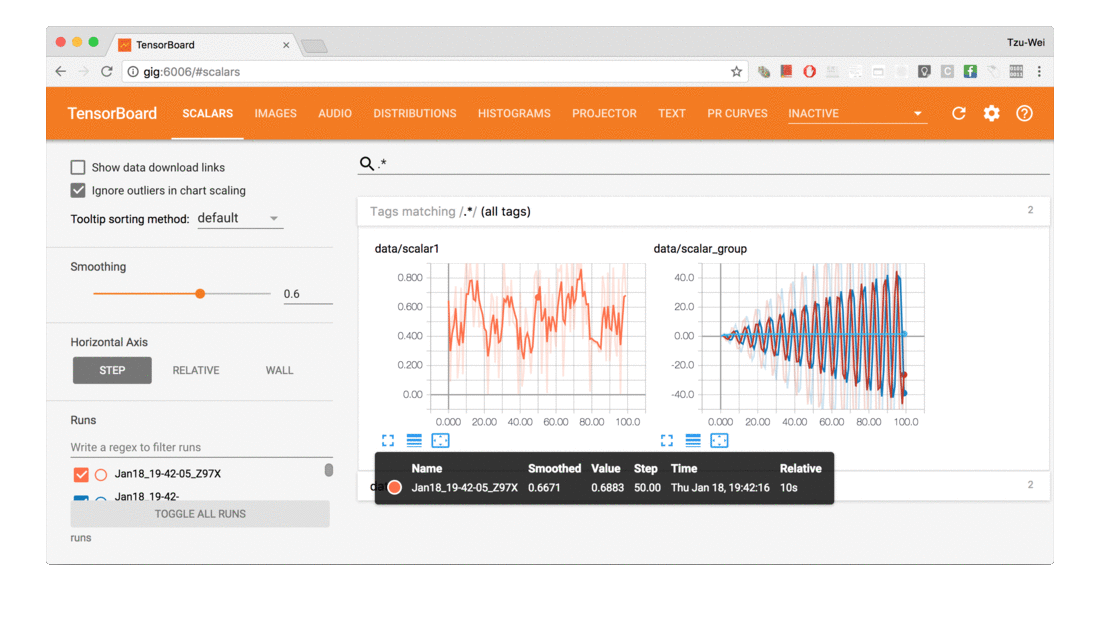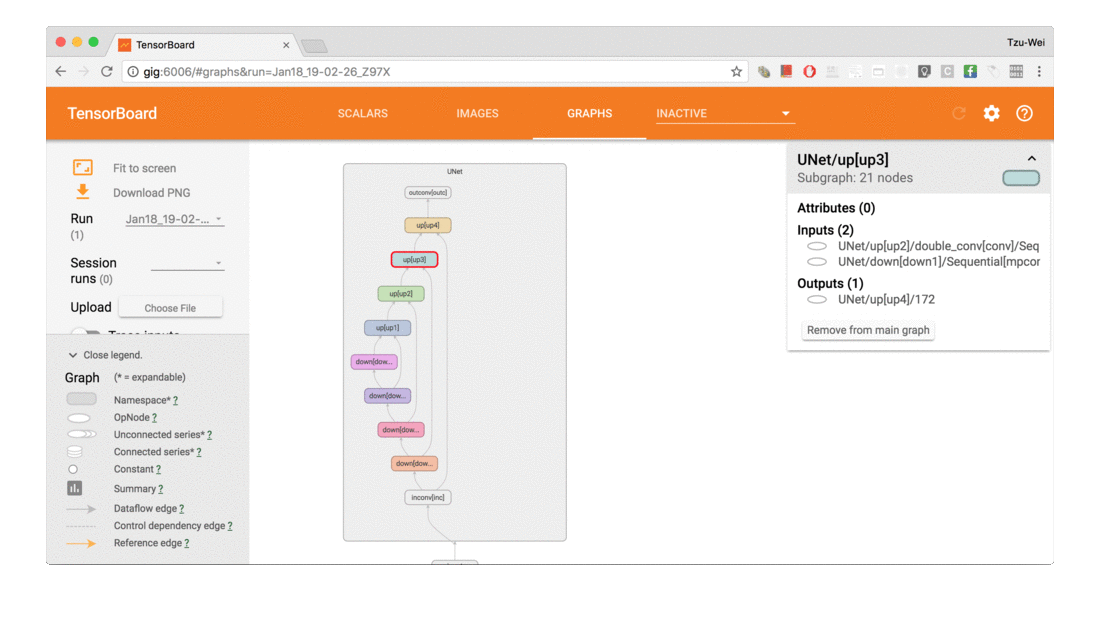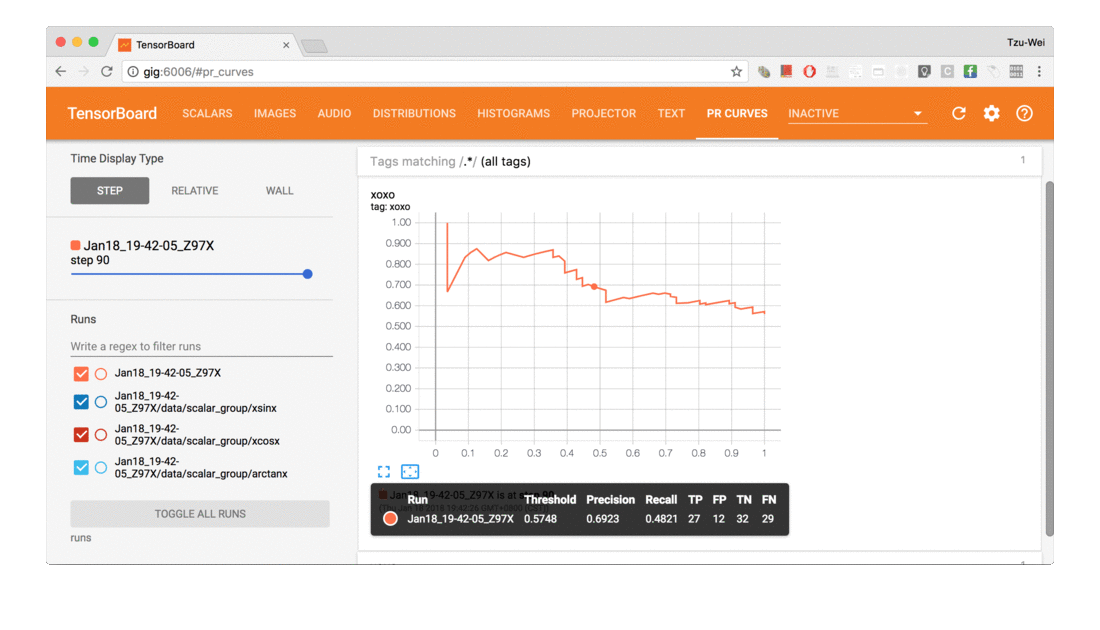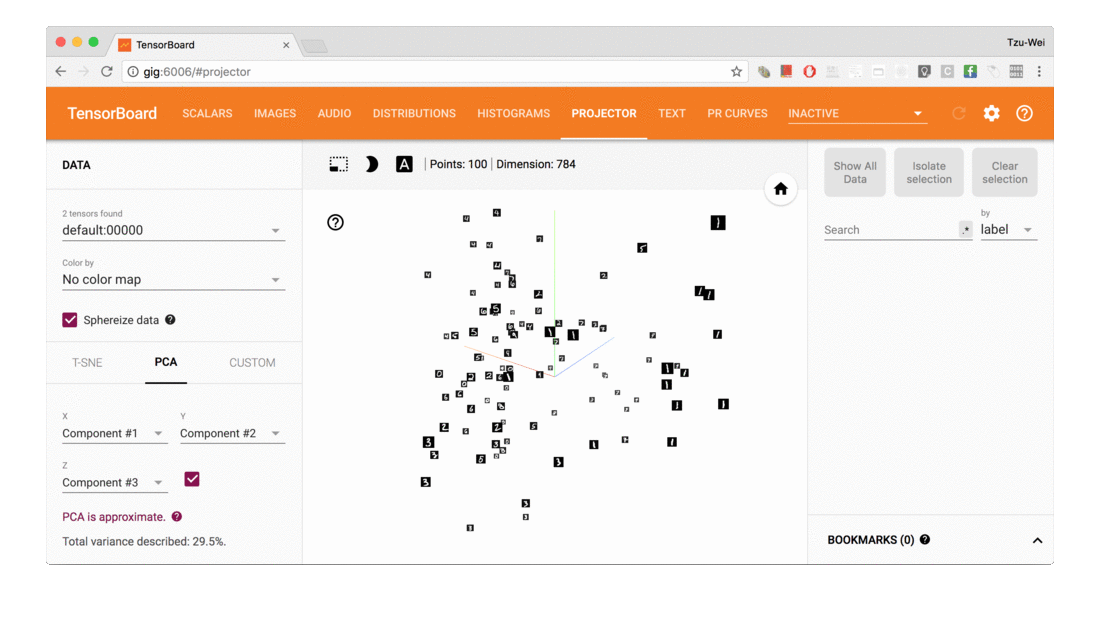
- 跟踪和可视化损失及准确率等指标
- 可视化模型图(操作和层)
- 查看权重、偏差或其他张量随时间变化的直方图
- 将嵌入投射到较低的维度空间
- 显示图片、文字和音频数据
- 剖析 TensorFlow 程序
- 以及更多功能
TensorBoardX 可视化的流程需要首先编写 Python 代码把需要可视化的数据保存到 event file 文件中,然后再使用 TensorBoardX 读取 event file 展示到网页中。TensorBoard目前支持7种可视化,Scalars、Images、Audio、Graphs、Distributions、Histograms和Embeddings。
github网址:https://github.com/lanpa/tensorboardX
2.Tensorboard 安装及使用
首先需要安装tensorboard
#安装tensorboard
pip install tensorboard
#安装tensorboardX
pip install tensorboardX
#安装crc32c加速
pip install crc32c
安装完成后与 visdom一样执行独立的命令 tensorboard --logdir logs 即可启动,默认的端口是 6006,在浏览器中打开 http://localhost:6006/ 即可看到web页面。最好使用chrome,其它浏览器可能会出现无法加载的情况。
这里运行GitHub官网的代码做示例:
下载代码:https://github.com/lanpa/tensorboardX
按这里步骤运行代码
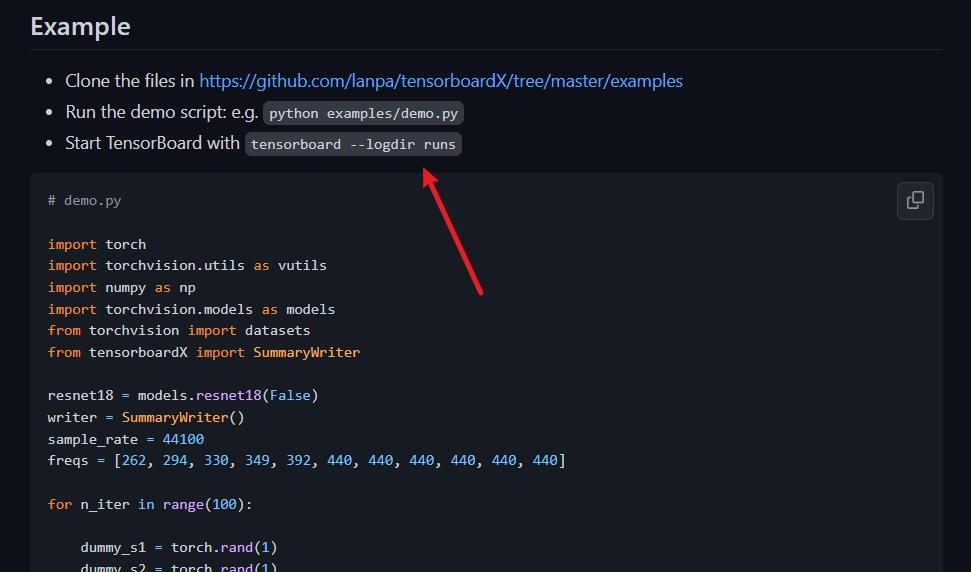
打开tensorboard,

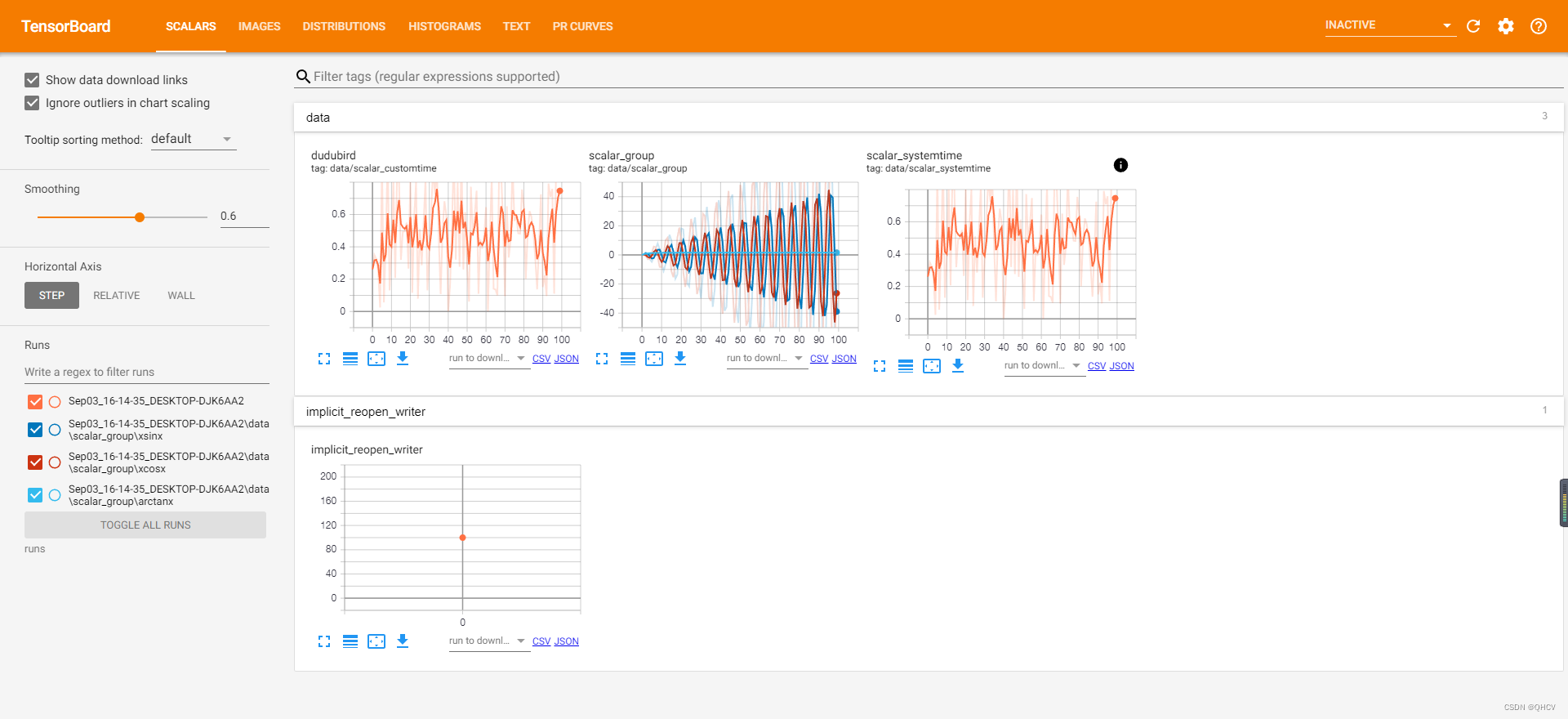
在浏览器中输入:
http://localhost:6006/
3. tensorboard中的页面介绍
| 页面 | 更多详细内容请参考官网 |
|---|---|
| SCALAR | 对标量数据进行汇总和记录,通常用来可视化训练过程中随着迭代次数准确率(val acc)、损失值(train/test loss)、学习率(learning rate)、每一层的权重和偏置的统计量(mean、std、max/min)等的变化曲线 |
| IMAGES | 可视化当前轮训练使用的训练/测试图片或者 feature maps |
| GRAPHS | 可视化计算图的结构及计算图上的信息,通常用来展示网络的结构以及训练在各个设备上消耗的内存和时间。 |
| HISTOGRAMS | 可视化张量的取值分布,记录变量的直方图(统计张量随着迭代轮数的变化情况) |
| Distributions | 展示训练过程中记录的数据的分部图。 |
| PROJECTOR | 全称Embedding Projector 高维向量进行可视化 |
| Audio | 展示训练过程中记录的音频。 |
| Embeddings | 展示词向量后的投影分部。 |

4.在 PyTorch 中进行可视化
4.1图像展示
add_image(tag, img_tensor, global_step=None, walltime=None, dataformats='CHW')
#tag:图像的标签名,图像的唯一标识
#img_tensor:图像数据,需要注意尺度
#global_step:记录这是第几个子图
#dataformats:数据形式,取值有'CHW','HWC','HW'。如果像素值在 [0, 1] 之间,那么默认会乘以 255,放大到 [0, 255] 范围之间。如果有大于 1 的像素值,认为已经是 [0, 255] 范围,那么就不会放大。
代码示例:
import torch
import numpy as np
import torch.nn as nn
import torch.nn.functional as F
from PIL import Image
from torchvision import transforms
from torchvision import models,datasets
from torch.utils.tensorboard import SummaryWriter
GZ_img = Image.open('G:\Desktop\关注我呀.jpg')
print(GZ_img.size)
#变成224x224的图片
transform_224 = transforms.Compose([
transforms.Resize(224),
transforms.CenterCrop(224),
transforms.ToTensor(),
])
GZ_img_224=transform_224(GZ_img )
writer = SummaryWriter(log_dir='./logs', comment='GZ image') # 这里的logs要与--logdir的参数一样
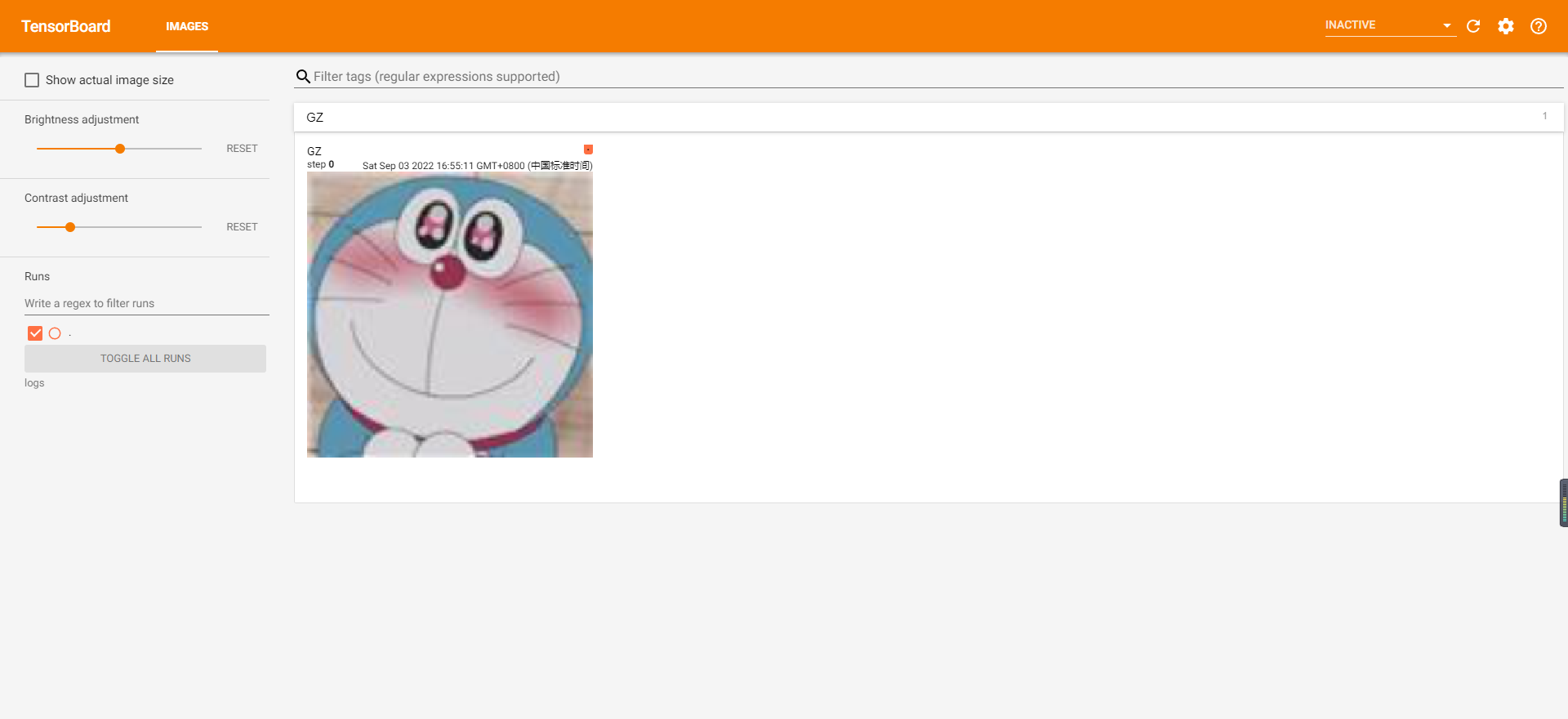
writer.add_image("GZ",cat_img_224)
writer.close()# 执行close立即刷新,否则将每120秒自动刷新
打开tensorboard:
tensorboard --logdir=runs
在浏览器中输入:
http://localhost:6006/
4.2 更新损失函数
x = torch.FloatTensor([100])
y = torch.FloatTensor([500])
for epoch in range(30):
x = x * 1.2
y = y / 1.1
loss = np.random.random()
with SummaryWriter(log_dir='./logs', comment='train') as writer: #可以直接使用python的with语法,自动调用close方法
#数据分布直方图
writer.add_histogram('his/x', x, epoch)
writer.add_histogram('his/y', y, epoch)
#绘制x,y随epoch变化图像
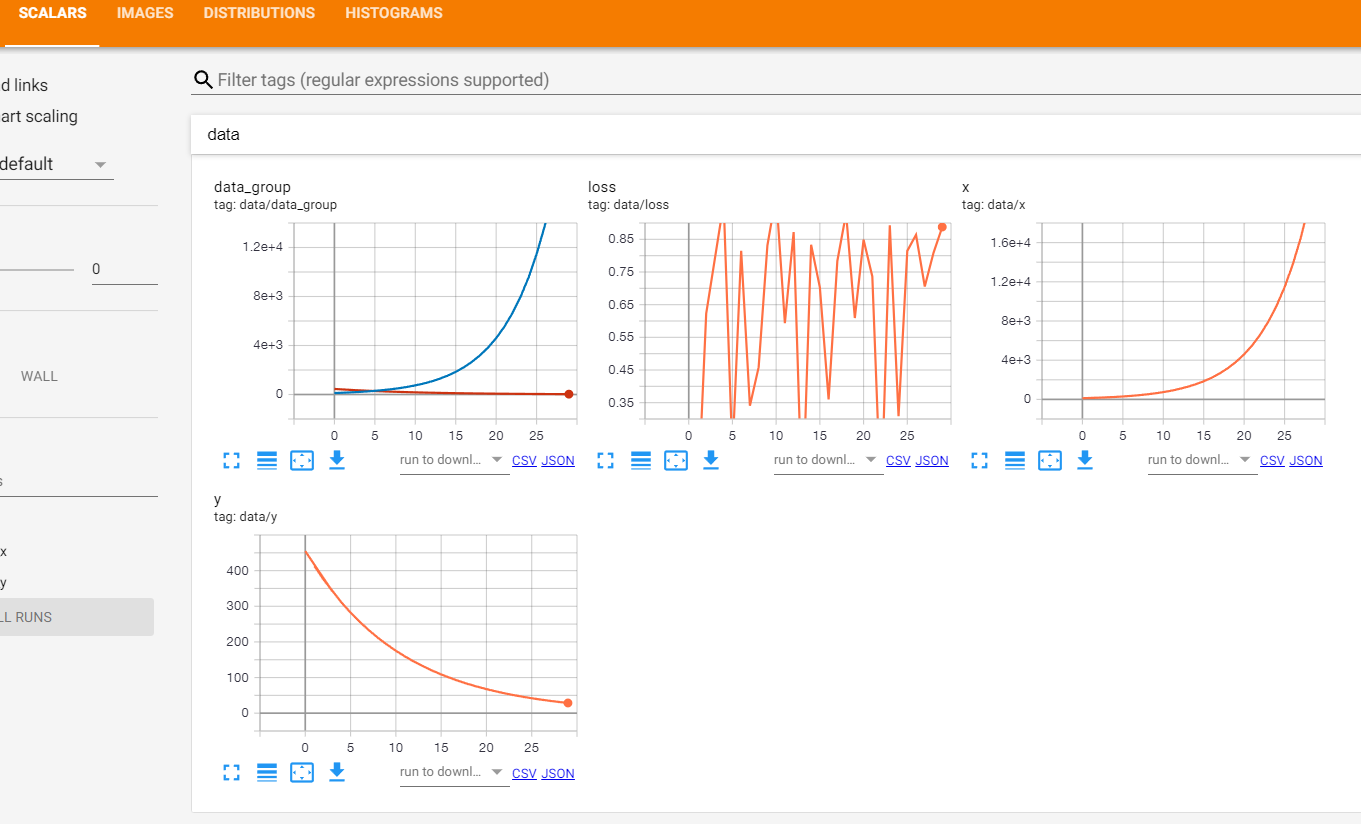
writer.add_scalar('data/x', x, epoch)
writer.add_scalar('data/y', y, epoch)
#损失函数图像
writer.add_scalar('data/loss', loss, epoch)
writer.add_scalars('data/data_group', {
'x': x,
'y': y}, epoch)
数据分布直方图: 图中的位置表示第七个epoch中234出现了1次
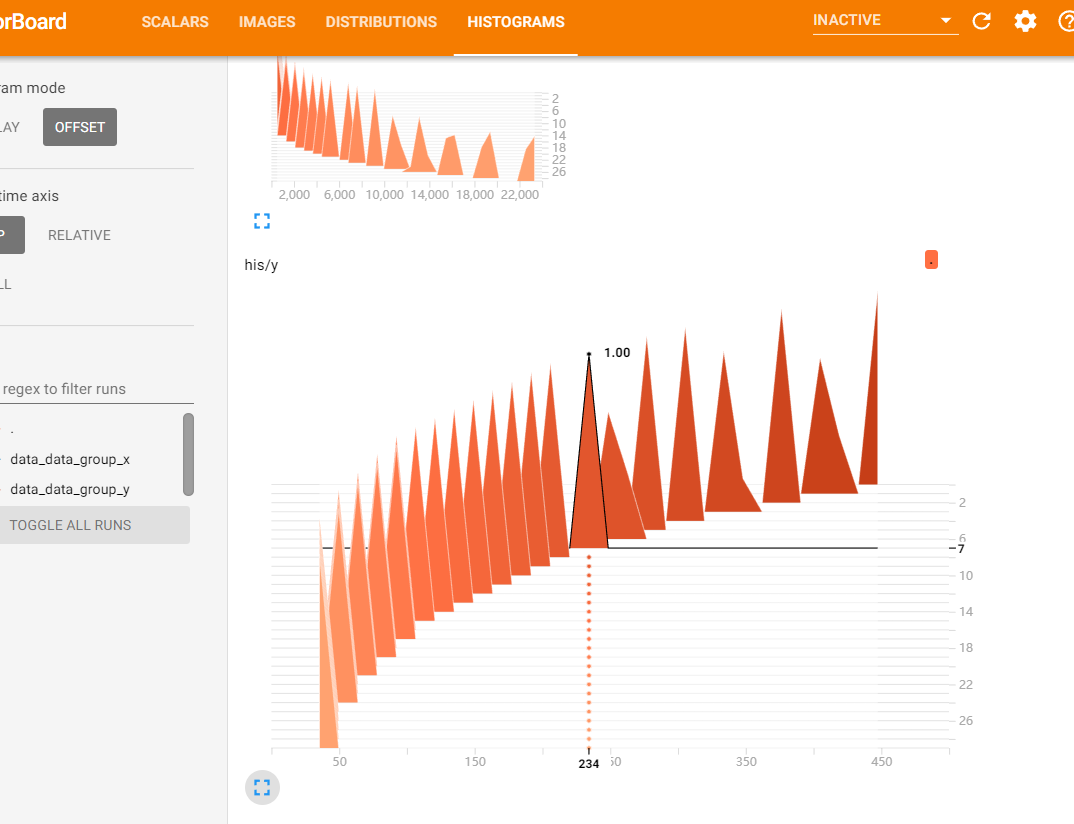
下面几个图是数据分布图
4.3使用PROJECTOR对高维向量可视化
add_embedding 记录embedding向量,支持2D/3D可视化分析,通过将高维特征降维至二维平面或三维空间显示,方便我们进行相关性分析。
add_embedding(mat, metadata=None, label_img=None, global_step=None, tag='default', metadata_header=None)
#add_embedding参数:mat (torch.Tensor or numpy.array):一个矩阵,每一行都是数据点的特征向量,要求形状(N, D),其中 N 是数据数量,D 是特征维度。
#metadata (list):标签列表,每个元素将被转换为字符串
#label_img (torch.Tensor):图像对应每个数据点,要求形状(N,C,H,W)。
#global_step (int):要记录的全局步长值
#tag (string):嵌入的名称
示例代码:
from torch.utils.tensorboard import SummaryWriter
import torchvision
writer = SummaryWriter('exp1')
num = 200#取MNIST训练集中的200个数据添加到Summary
mnist = torchvision.datasets.MNIST('mnist', download=True)
mat = mnist.train_data.reshape((-1, 28 * 28))[:num,:]#图像展开成一维向量
metadata = mnist.train_labels[:num]
label_img = mnist.train_data[:num,:,:].reshape((-1, 1, 28, 28)).float()/255#归一化
writer.add_embedding(mat,metadata=metadata,label_img = label_img,global_step=0)
writer.close()

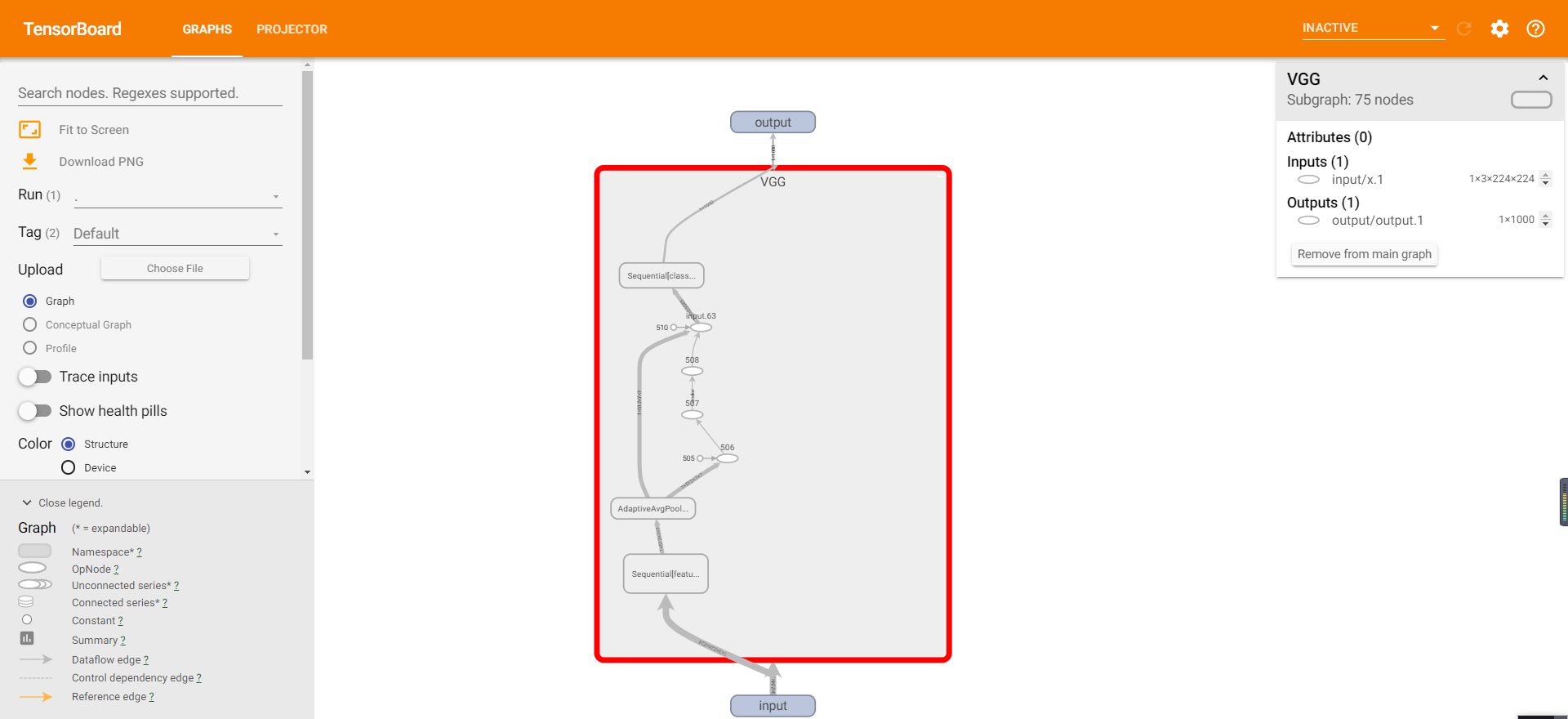
4.4 绘制网络结构
在pytorch中我们可以使用print直接打印出网络的结构,但是这种方法可视化效果不好。 由于pytorch使用的是动态图计算,所以我们这里要手动进行一次前向的传播。
使用vgg16作为展示:
vgg16 = models.vgg16(pretrained=True) # 这里下载预训练好的模型
print(vgg16) # 打印一下这个模型
结果:
VGG(
(features): Sequential(
(0): Conv2d(3, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): ReLU(inplace=True)
(2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(3): ReLU(inplace=True)
(4): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(5): Conv2d(64, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(6): ReLU(inplace=True)
(7): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(8): ReLU(inplace=True)
(9): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(10): Conv2d(128, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(11): ReLU(inplace=True)
(12): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(13): ReLU(inplace=True)
(14): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(15): ReLU(inplace=True)
(16): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(17): Conv2d(256, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(18): ReLU(inplace=True)
(19): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(20): ReLU(inplace=True)
(21): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(22): ReLU(inplace=True)
(23): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(24): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(25): ReLU(inplace=True)
(26): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(27): ReLU(inplace=True)
(28): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(29): ReLU(inplace=True)
(30): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
)
(avgpool): AdaptiveAvgPool2d(output_size=(7, 7))
(classifier): Sequential(
(0): Linear(in_features=25088, out_features=4096, bias=True)
(1): ReLU(inplace=True)
(2): Dropout(p=0.5, inplace=False)
(3): Linear(in_features=4096, out_features=4096, bias=True)
(4): ReLU(inplace=True)
(5): Dropout(p=0.5, inplace=False)
(6): Linear(in_features=4096, out_features=1000, bias=True)
)
)
使用tensorboard可视化:
add_graph(model, input_to_model=None, verbose=False)
#model:模型,必须继承自 nn.Module
#input_to_model:输入给模型的数据,形状为 BCHW
#verbose:是否打印图结构信息
代码示例:
transform_2 = transforms.Compose([
transforms.Resize(224),
transforms.CenterCrop((224,224)),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225])
])
#因为pytorch的是分批次进行的,所以我们这里建立一个批次为1的数据集
# np.newaxis,当作为第一个元素时对行增加一维,作为第二个元素时对列增加一个维度
vgg16_input=transform_2(cat_img)[np.newaxis]#
out = vgg16(vgg16_input)
_, preds = torch.max(out.data, 1)
label=preds.numpy()[0]
with SummaryWriter(log_dir='./exp1', comment='vgg161') as writer:
writer.add_graph(vgg16, vgg16_input)
参考资料:
https://zhuanlan.zhihu.com/p/414644289
https://handbook.pytorch.wiki/chapter4/4.2.2-tensorboardx.html
欢迎关注公众号【智能建造小硕】(分享计算机编程、人工智能、智能建造、日常学习和科研经验等,欢迎大家关注交流。)