深度学习经典工作
常用CNN Backbone:
ResNet: 引入残差结构和BN层的概念,有效解决了梯度消失/爆炸和网络退化的问题
Inception Net: Inception Block将不同尺度的卷积层、池化层横向堆叠,并将得到的特征进行拼接。通过增加网络宽度来提升网络性能,其中采用1×1的卷积降维来减小计算量。
Mobile Net: 提出深度可分离卷积,把卷积分解成depthwise和pointwise两个步骤,depthwise种每个2维的filter只负责1个channel(这一步不改变通道数,num_filters = num_channels),pointwise由多个1×1的filters来完成(可以改变通道数)。

Object Detection:
RCNN系列: 经历了RCNN, Fast RCNN, Faster RCNN的改进,核心思想是先得到Region Proposal再输入分类网络得到类别分数和边框回归。1.0 将Selective Search得到的Region Proposal分别输入网络提取特征,有大量的重复计算,2.0 先对整张图片进行特征提取,再将SS得到的区域映射到特征图上,3.0 将传统的SS方法改为RPN网络,由Bounding Box Regressor层学习到对Anchor Box的回归参数从而得到Region Proposal。
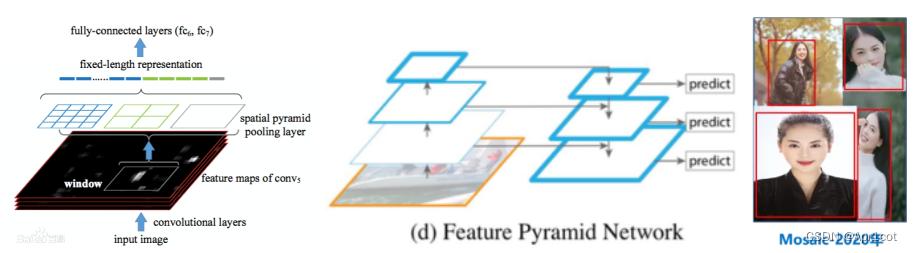
YOLO系列: YOLO借用了Faster RCNN中Anchor Box的思想,直接通过对Anchor Box的分类和回归得到目标检测结果。并提出了一系列的优化方法,如SPP结构,FPN结构,Mosaic数据增强等。
SPP: Spatial Pyramid Pooling, 对不同大小的输入能输出固定大小特征,在图像变形的情况下表现稳定。
FPN: Feature Pyramid Network,构造一系列不同尺度的特征进行模型的训练和推理。
SSD:
经典视觉Transformer:
ViT: 最早将Transformer引入视觉领域,引入Attention机制,更擅长于对特征的全局运算、大数据运算,同时面临着计算量大模型复杂的问题。将输入分为多个Token并加上位置编码(可训练参数)。
Mobile ViT: 网络浅层由MoblieNet V2 block组成,拥有局部感受野,深层由ViT block组成拥有全局感受野。
SwinT: Swin Transformer相较于ViT引入了Shift Window模块,将特征图划分为多个windows,并在每个windows内部进行Attention的计算,大大减小了计算量,同时引入Shift-Window 实现了不同windows中的信息交互工作。
并且引入相对位置编码的概念,使得Attention Map进一步有所偏重,取得了比绝对位置编码更好的效果。在具体的代码实现过程中文章着重提到了Shift+Mask的方法简单高效地实现Shift后的Window Attention计算。
DeTr: Detection Transformer没有class token,通过encoder和decoder的方法,由初始化的object queries与编码得到的特征Key和Value进行解码查询,获取class和box信息。

新工作
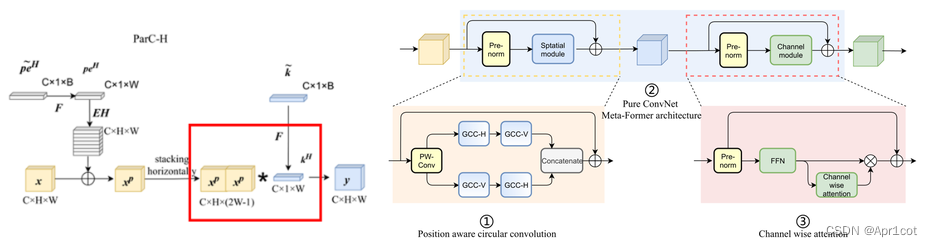
ParC Net:Position Aware Circular Convolution对比了CNN和Transformer各自的优点分析其原因,从三方面构建了一个不含注意力机制的CNN,但具有Transformer的优点。 首先通过提出的循环卷积实现了全局特征的提取,其次用循环卷积构造了类Transformer的MetaFormer Block,最后引入SE Network中的channel wise attention机制,增强模型的data driven性能。构建完成的ParC Block后,将ParC Block 替换Mobile ViT中的ViT block,保留浅层的MobileNet V2 Block。
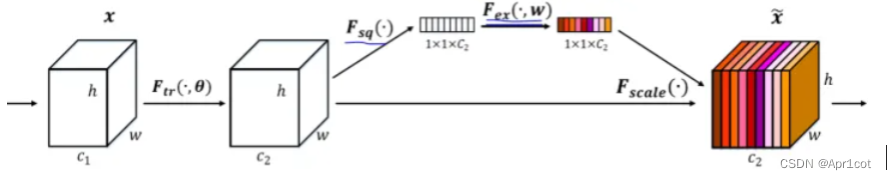
SE Net: Squeeze-and-Excitation Net, 主要创新点在于其显示地对特征图的各channel之间的关系进行建模,以增强表征信息更多的通道,抑制次要通道(data driven)。网络的核心结构是SE Block,squeeze将特征进行global averaging pooling,Excitation为两个全连接层,先降维再恢复,降低复杂性提升泛化能力,scale将Excitation得到的权重作用于原特征图。
MetaFormer:MetaFormer将Transformer的结构抽象成Token Mixer和Channel MLP,传统的Transformer中Attention起到的就是Token Mixer的作用。在MetaFormer中,将Attention结构换成简单的Pooling层,同样能提升网络性能。
ConvNeXt:ConvNeXt是对标Swin Transformer构建的纯卷积结构,其认为Swin T在具有和CNN相似的固有偏差的情况仍具有较好的效果,因此并不能说明Transformer因为没有inductive bias而优于CNN,而是得益于其先进的训练手段。
ConvNeXt以Swin T为标准对ResNet网络结构做了相似的调整并运用了相同的训练手段,使其在相同网络量级的性能上超过了Transformer的表现。
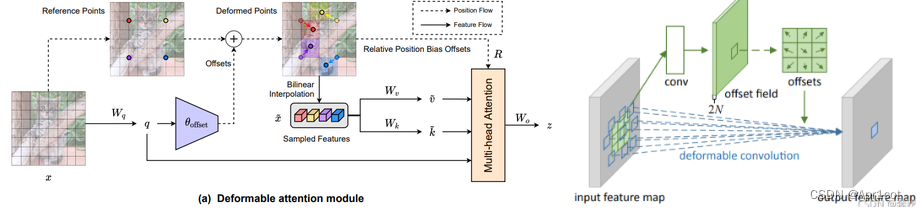
DAT:Transformer with Deformable Attention, ViT的全局注意力计算量庞大,Swin T 的手工设计注意力模式则与数据无关,可能没有最佳表现,DAT提出可变注意力机制,先通过一个Offset网络得到参考点的偏移参数,再对参考区域内部进行注意力计算。
DCN: Deformable Convolution, 通过一个Offset网络学习了特征图每个位置的偏移参数,能有效地对几何图形的变化进行建模。
Action方向知识
2D卷积网络:
2-Stream:引入光流输入,最常见的是利用RGB+Optical Flow的形式,在对准确率提升上往往有不小帮助,但在光流的提取运算,存储以及最终网络计算量方面存在较大的问题。
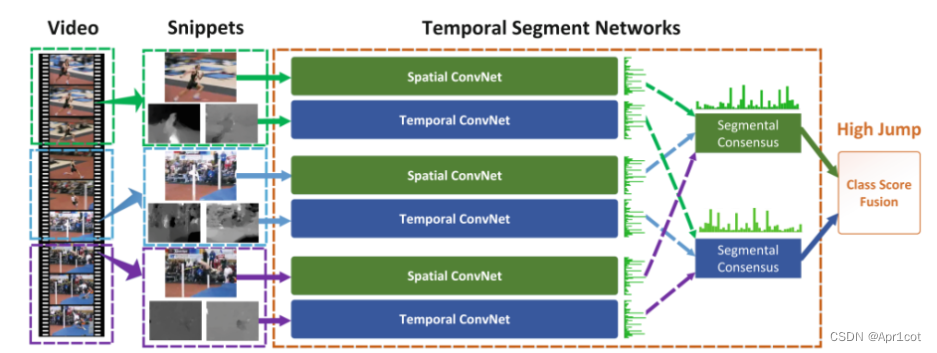
TSN:将视频分段,在每个切片中抽取RGB和光流输入2-Stream网络(参数共享),将RGB流结果做一个aggregation,光流结果做一个aggregation,最后将两种流的得分fusion得到最终得分。
其中aggregation使用的方法是取平均(evenly averaging), fusion方法和2-Stream相同,可选择取平均或SVM。
TRN: Temporal Relation Network整体框架和TSN网络类似,但在对于各片段的aggregation(Segmental Consensus)过程中,提出了时间关系推理,将不同的片段的RGB按顺序输入TRN结构,得到
TSM: Temporal Shift Module,提出将卷积操作解耦成平移和乘算两步,因此将各通道的特征(实际上取1/8的网络卷积)在时间维度上Shift再进行二维卷积(2D Conv的Kernel实际上有CHW三个维度),以二维卷积的计算成本,取得了三维卷积的效果。
Non-local Neural Networks : 一种高效的长距离依赖的卷积模块,很容易插入其他网络,其作用效果和Attention机制类似。
3D卷积网络:
R(2+1)D: 类似Mobile Net 的思想,将3D卷积进行深度分离,分解为2D卷积+1×1卷积,大大减小了网络计算量。
I3D: Inflated 3D 主要贡献是提出了将二维网络通过膨胀的方法直接运用于视频理解,能利用现有的优秀网络结构以及预训练权重(直接将权重在时间维度上复制再乘1/T),并且文章贡献了Kinetic数据集。
X3D:eXpand 3D将维度的扩展从固有思维上解放,不再着眼于时间维度或者图片的输入尺寸(THW),X3D在更多的维度上包括时间间隔,帧率,空间分辨率,网络宽度,Bottleneck宽度、深度方面进行超参数的调整,以获取最佳的精度计算比。
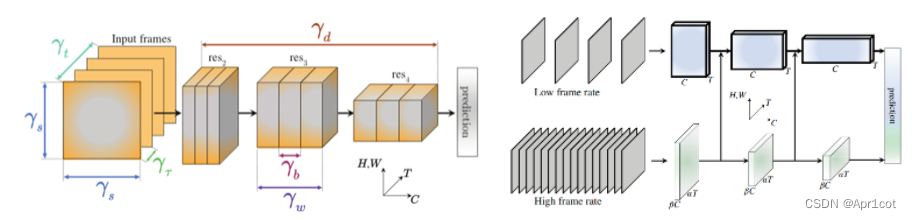
SlowFast: SlowFast设计了两条路径,一条在低帧率下用于捕捉图像或稀疏帧所提供的语义信息,另一条在高帧率下负责捕捉快速变化的运动。两条通路由不同的时间速度驱动,并通过侧向连接融合信息。
Transformer:
ViViT: 直接将ViT运用于视频任务,提出了两种输入形式,一种直接先将所有帧分别转为token然后输入ViT(Uniform frame sampling),另一种则将多帧组合,获取时具有空信息的token(Tubelet embedding)。
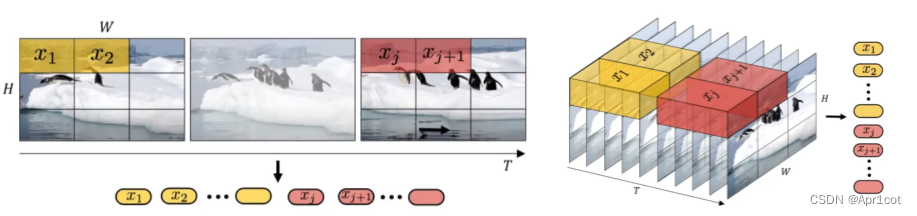
Vide Swin: 类似图像任务的Swin T,将Windows改为3D形式。
TimeSformer: TimeSformer探寻了多种注意力计算模式,包含Space Attention,Joint Space-Time, Divided Space-Time, Sparse Local Global, Axial Attention。其中表现较好的有Joint S-T和Divided S-T。文章出发点简单,训练推理开销小,并在数据量大的时候表现良好。

Uniformer: 高效地统一了3D卷积和时空自注意力机制,克服了视频冗余和依赖性。高分论文!UniFormer:高效时-空表征学习的统一Transformer - 知乎
Motion Former:在TimeSformer等工作中,时间维度的信息以空间位置相同处进行处理,但在物体发生运动的场景中,该方法建模效果不佳,为了对动态场景的进一步理解,需要对这些时间进行建模,Motion Former提出一个插入Block,轨迹注意力模块,能沿着隐式确定的运动路径聚合信息。
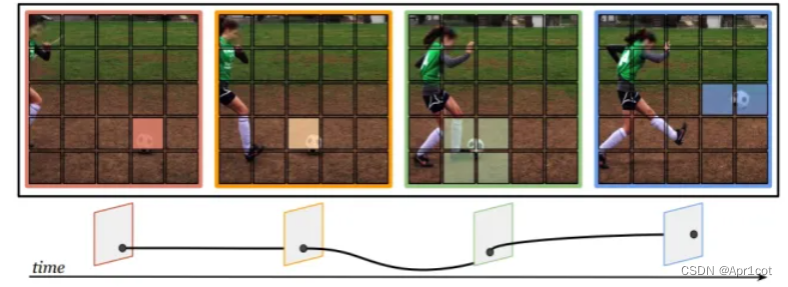
时空(间)动作定位:
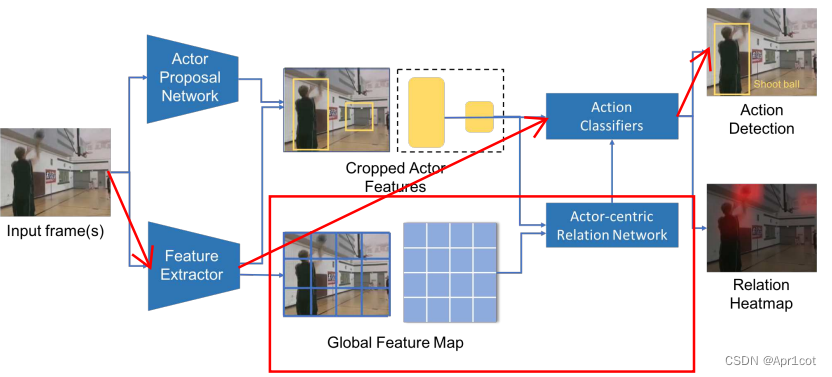
Actor-centric Relation Network : 很多时空动作定位网络都是先生成Region Proposal再直接将其输入分类网络完成,这种方法忽略了背景对于动作检测的影响,文章提出以动作主体为中心所构建的关系网络对动作和背景联合建模以提高动作检测性能。
S-CNN: 时间动作定位网络,将输入帧分为不同尺度的片段,利用16、32、64帧等尺度的滑窗实现,将这些片段分别输入S-CNN网络,对动作/Background进行判断分类,得到在长时间视频中的时间片段定位。
SSN: 在滑窗的基础上SSN,将Windows向两侧延伸,以预测动作的开始和结束时间节点。
BMN:Boundary-Matching Network时间动作定位网络,相较于S-CNN只能对固定的大小的片段进行判断,BMN对视频帧进行动作开始点、动作结束点的可能性预测,BM置信图每个点都代表了一段独有的视频片段,得到Action Proposal。

Pytorch
Out of Memory:在复现论文结果时,大的Batch Size容易出现GPU out of memory的情况,常用解决方案如下。
修改学习率:最简单的方法是直接对网络学习率修改,往往Batch Size大小和学习率成正比。
多GPU训练:利用多个GPU共同完成一个Batch Size 的训练,需要考虑各GPU之间的信息传递。
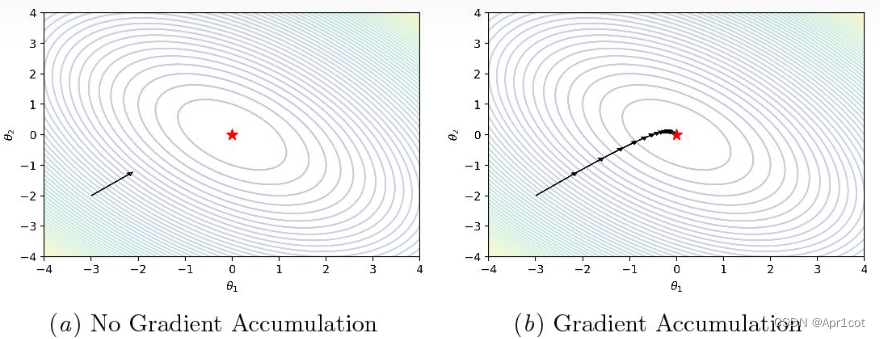
梯度累加:在完成一个Batch的训练后,不立即更新参数清空梯度,而是保留梯度,累计多个Batch的梯度后再更新梯度以等效N×Batch Size的大Batch效果。
预训练:是否进行预训练往往对结果有非常大的影响,尤其是小数据集若不预先在大集上预训练,极易发生过拟合,网络中大部分参数还未被‘’利用‘’模型就已经在小数据集上过拟合,最终结果可能会相差十几甚至几十个点,因此模型的预训练权重是必要的。
过拟合:由于深度往往具有大量的参数,在复杂模型中下小的数据集极易发生过拟合。
图像任务:分类任务在Imagenet上预训练,目标检测任务在COCO上的预训练
视频任务:2D网络往往选择在Kinetics 400上预训练,3D网络往往选择Imagenet上的膨胀权重
权重冻结:在使用预训练权重时,可以选择在训练初期不稳定的时候冻结浅层的特征提取权重,仅训练深层的分类器,在训练后期稳定后再释放浅层权重参与训练。
Autimatic Mixed Precision: 深度学习模型大部分都是使用FP32来进行模型训练(loss和梯度的乘加计算与更新),由于模型越来越大,参数越来越多,那么训练成本愈来愈高。
为了更好地利用GPU显存以及加速矩阵的乘法运算,混合精度训练在尽可能减少精度损失的情况下利用半精度浮点数加速训练。
模型训练时,前向和反向传播过程中,使用FP16。也就是说训练时,将模型的权重从FP32转换成FP16,然后进行前向传播(FP16),计算得到loss(FP32),然后反向传播(FP16),计算得到梯度(FP16),然后转换成FP32,更新模型权重(FP32)。
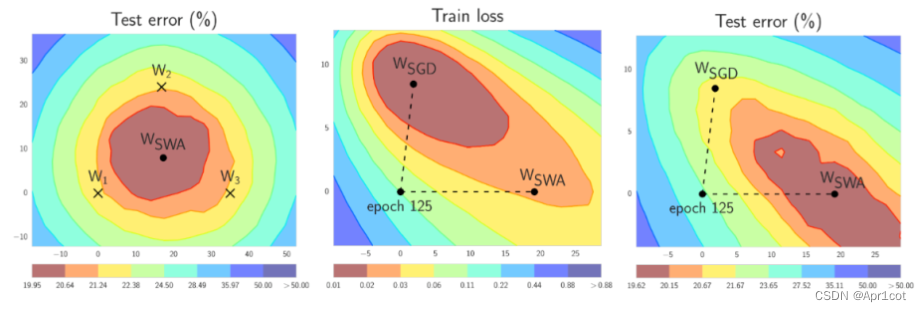
Stochastic Weight Averaging: 通过平均多个SGD的权重参数,使其能够达到平稳区域的中心。