计算机视觉算法在图像识别方面的一些难点:
1)视角变化:同一物体,摄像头可以从多个角度来展现;
2)大小变化:物体可视的大小通常是会变化的(不仅是在图片中,在真实世界中大小也是由变化的);
3)形变:很多东西的形状并非一成不变,会有很大变化;
4)遮挡:目标物体可能被遮挡。有时候只有物体的一部分(可以小到几个像素)是可见的; 5)光照条件:在像素层面上,光照的影响非常大;
6)背景干扰:物体可能混入背景之中,使之难以被辨认;
7)类内差异:一类物体的个体之间的外形差异很大,如椅子。这一类物体有许多不同的对象,每个都有自己的外形
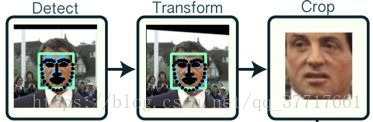
人脸识别算法主要包含三个模块:
-
人脸检测(Face Detection):确定人脸在图像中的大小和位置,也就是在图像中预测anchor;
-
人脸对齐(Face Alignment):它的原理是找到人脸的若干个关键点(基准点,如眼角,鼻尖,嘴角等),然后利用这些对应的关键点通过相似变换(Similarity Transform,旋转、缩放和平移)将人脸尽可能变换到标准人脸;
-
人脸特征表征(Feature Representation):它接受的输入是标准化的人脸图像,通过特征建模得到向量化的人脸特征,最后通过分类器判别得到识别的结果。关键点是怎样得到不同人脸的有区分度的特征,比如:鼻子、嘴巴、眼睛等。
早期算法:
-
子空间(线性降维)
PCA(主成成分分析) :尽量多地保留原始数据的保留主要信息,降低冗余信息;
LDA(线性判别分析):增大类间差距,减小类内差距。 -
非线性降维: 流形学习、加入核函数。
-
ICA(独立成分分析):比PCA效果好,比较依赖于训练测试场景,且对光照、人脸的表情、姿态敏感,泛化能力不足。
-
HMM(隐马尔科夫) : 和前面这些算法相比,它对光照变化、表情和姿态的变化更鲁棒。
早期:数据和模型结构;
后期:loss,从而得到不同人脸的有区分度的特征。
常用算法总结
- 特征提取(找到若干个关键点)
(1) SIFT (尺度不变特征变换) 具有尺度不变性,可在图像中检测出关键点。
(2) SURF(加速稳健特征,SIFT加速版)
核心:构建Hessian矩阵,判别当前点是否为比邻域更亮或更暗的点,由此来确定关键点的位置。
优:特征稳定;
缺:对于边缘光滑的目标提取能力较弱。
(3) ORB
- 结合Fast与Brief算法,并给Fast特征点增加了方向性,使得特征点具有旋转不变性,并提出了构造金字塔方法,解决尺度不变性.
- ORB算法的速度是sift的100倍,是surf的10倍。
经显示观察到,ORB算法在特征点标记时数量较少,如图:

(4) FAST角点检测
FAST的方法主要是考虑像素点附近的圆形窗口上的16个像素
如果要提高检测速度的话,只需要检测四个点就可以了,首先比较第1和第9个像素,如果两个点像素强度都在中心像素强度t变化范围内(及都同中心点相似),则说明这不是角点,如果接下来检测第5和13点时,发现上述四点中至少有三个点同中心点不相似,则可以说明这是个角点。

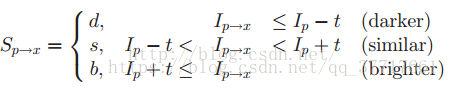
非极大值抑制:如果存在多个关键点,则删除角响应度较小的特征点。
(5) HOG (方向梯度直方图)
(6) LBP(局部二值特征)论述了高维特征和验证性能存在着正相关的关系,即人脸维度越高,验证的准确度就越高。
(7)Haar