简介:
注意力机制(attention)最早应用应该是在机器翻译上,近年来又在计算机视觉(CV)任务中火了起来。CV中的注意力机制的主要是想让神经网络着重学习感兴趣的地方。
前言:
注意力有两种,一种是软注意力(soft attention),另一种则是强注意力(hard attention)。
1、软注意力更关注区域或者通道,而且软注意力是确定性的注意力,学习完成后直接可以通过网络生成,最关键的地方是软注意力是可微的,这是一个非常重要的地方。可以微分的注意力就可以通过神经网络算出梯度并且前向传播和后向反馈来学习得到注意力的权重。
2、强注意力是更加关注点,也就是图像中的每个点都有可能延伸出注意力,同时强注意力是一个随机的预测过程,更强调动态变化。当然,最关键是强注意力是一个不可微的注意力,训练过程往往是通过强化学习(RL)来完成的。
空间域Attention:
将图片中的的空间域信息做对应的空间变换,从而能将关键的信息提取出来。对空间进行掩码的生成,进行打分,代表是 Spatial Attention Module。
1、如下是Google DeepMind提出的STN网络:
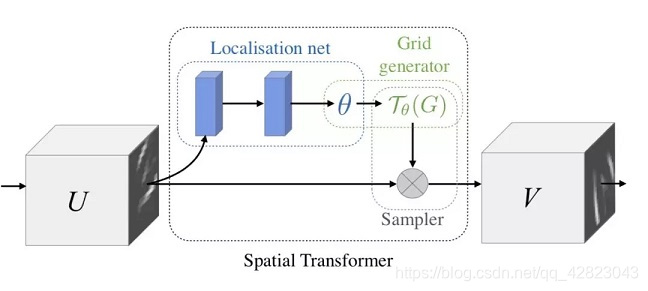
这里的Localization Net用于生成仿射变换系数,输入是C×H×W维的图像,输出是一个空间变换系数,它的大小根据要学习的变换类型而定,如果是仿射变换,则是一个6维向量。即定位到目标的位置,然后进行旋转等操作,使得输入样本更加容易学习。
2、而Dynamic Capacity Networks则采用了两个子网络,分别是低性能的子网络(coarse model)和高性能的子网络(fine model)。
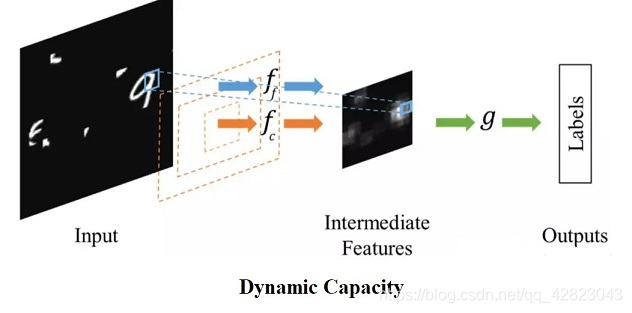
低性能的子网络用于对全图进行处理,定位感兴趣区域,如下图中的操作fc。高性能的子网络则对感兴趣区域进行精细化处理,如下图的操作ff。两者共同使用,可以获得更低的计算代价和更高的精度。
通道域Attention——SENet:
类似于给每个通道上的信号都增加一个权重,来代表该通道与关键信息的相关度的话,这个权重越大,则表示相关度越高。对通道生成掩码 mask,进行打分,代表是 SENet, Channel Attention Module。
1、SENet是2017年的世界冠军,SE全称Squeeze-and-Excitation是一个模块,将现有的网络嵌入SE模块的话,那么该网络就是SENet,它几乎可以嵌入当前流行的任何网络。
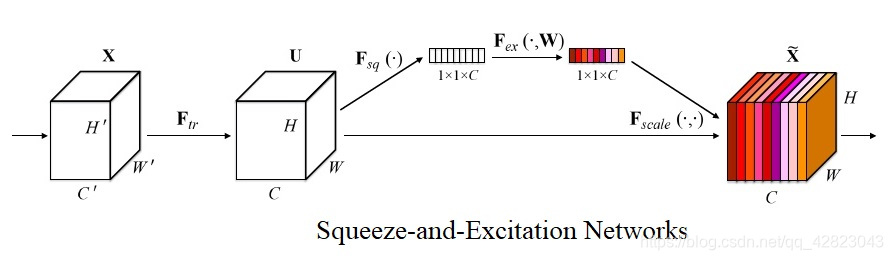
上图是 SENet 的 Block 单元,图中的 Ftr 是传统的卷积结构,X 和 U 是 Ftr 的输入 (C’×H’×W’) 和输出 (C×H×W),这些都是以往结构中已存在的。SENet 增加的部分是 U 后的结构:对 U 先做一个 Global Average Pooling(图中的Fsq(.),作者称为 Squeeze 过程),输出的 1×1×C 数据再经过两级全连接(图中的Fex(.),作者称为 Excitation 过程),最后用 sigmoid(论文中的 self-gating mechanism)限制到 [0, 1] 的范围,把这个值作为 scale 乘到 U 的 C 个通道上, 作为下一级的输入数据。这种结构的原理是想通过控制 scale 的大小,把重要的特征增强,不重要的特征减弱,从而让提取的特征指向性更强。
通俗的说就是:通过对卷积的到的 feature map 进行处理,得到一个和通道数一样的一维向量作为每个通道的重要性评分,然后每个通道的重要性评分乘以每个通道原来的值,就是我们求的真正feature map,这个feature map中不同的通道其重要性不一样。
下面给出的一个嵌入Inception结构和Resnet结构的例子:
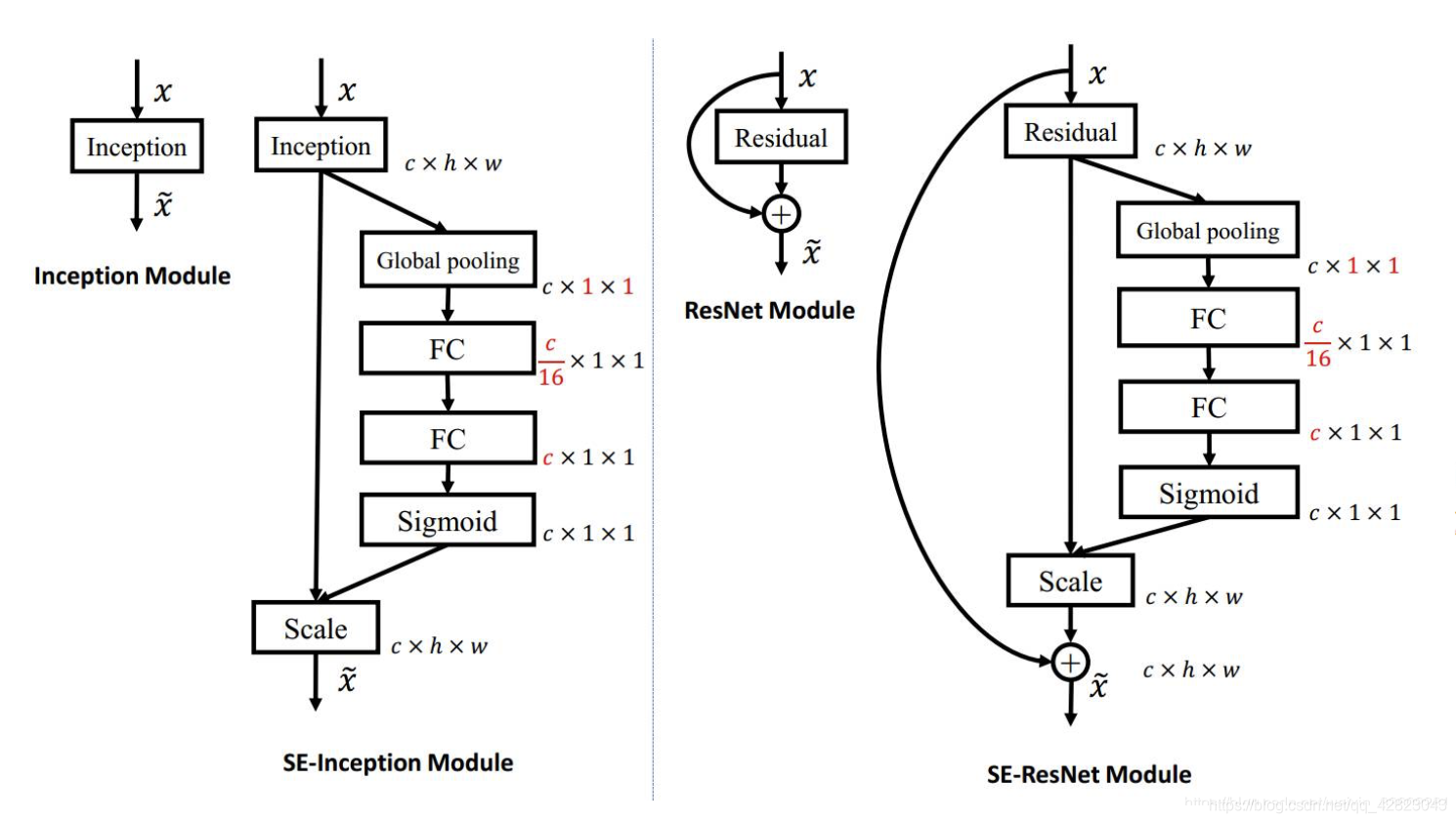
pytorch代码实现:
class SELayer(nn.Module):
def __init__(self, channel, reduction=16):
super(SELayer, self).__init__()
self.avg_pool = nn.AdaptiveAvgPool2d(1)
self.fc = nn.Sequential(
nn.Linear(channel, channel // reduction, bias=False),
nn.ReLU(inplace=True),
nn.Linear(channel // reduction, channel, bias=False),
nn.Sigmoid()
)
def forward(self, x):
b, c, _, _ = x.size()
y = self.avg_pool(x).view(b, c)
y = self.fc(y).view(b, c, 1, 1)
return x * y.expand_as(x)