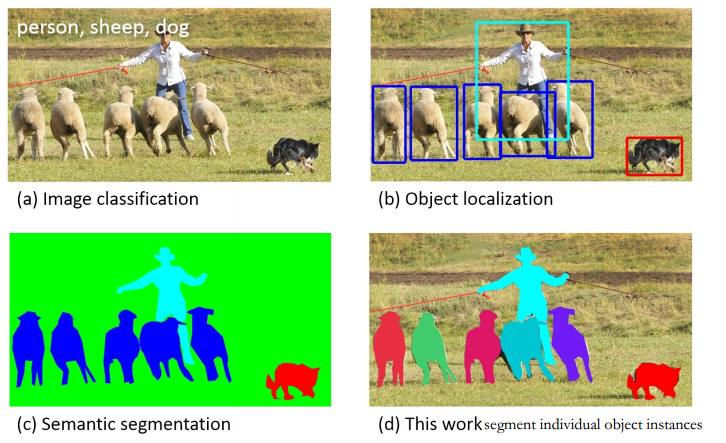
“Object Segment”,即物体分割。这属于图像理解范畴。图像理解包含众多,如图像分类、物体检测、物体分割、实例分割等若干具体问题。每个问题研究的范畴是什么?或者说每个问题中,对于某幅图像的处理结果是什么?整理如下。
Image Classification
The task of object classification requires binary labels indicating whether objects are present in an image.[1] 图像分类,该任务需要我们对出现在某幅图像中的物体做标注。比如一共有1000个物体类,对一幅图中所有物体来说,某个物体要么有,要么没有。可实现:输入一幅测试图片,输出该图片中物体类别的候选集。
Detecting an object entails both stating that an object belonging to a specified class is present, and localizing it in the image. The location of an object is typically represented by a bounding box. 物体检测,包含两个问题,一是判断属于某个特定类的物体是否出现在图中;二是对该物体定位,定位常用表征就是物体的边界框。可实现:输入测试图片,输出检测到的物体类别和位置。
The task of labeling semantic objects in a scene requires that each pixel of an image be labeled as belonging to a category, such as sky, chair, floor, street, etc. In contrast to the detection task, individual instances of objects do not need to be segmented. 语义标注/分割:该任务需要将图中每一点像素标注为某个物体类别。同一物体的不同实例不需要单独分割出来。对下图,标注为人,羊,狗,草地。而不需要羊1,羊2,羊3,羊4,羊5.
实例分割是物体检测+语义分割的综合体。相对物体检测的边界框,实例分割可精确到物体的边缘;相对语义分割,实例分割可以标注出图上同一物体的不同个体(羊1,羊2,羊3...)