之前一直觉得自己学的杂而不专,在之后的学习和干活历程中也不断发现自己确实需要静下心来钻研,让自己像身边的师兄一样能有一技之长,能在社会上有自己的立足之地。
讲真在计算机这个庞大的体系下挑选出一个方向来确实蛮难,自己挑来挑去,有种乱花渐欲迷人眼的感觉,不过就目前自己的兴趣、性格和学习能力,远景规划来看,计算机视觉这个方向目前来看对我自己来说确实是一个十分不错的选择。
通过这篇文章希望可以在整理自己搜集的信息的同时,理清自己的思路,搞清楚计算机视觉大致是个什么东西,入坑后要学,要做些什么东西,它的前(钱)景怎么样?(这个说明一下啊,做任何事没有钱是万万不能的,钱代表了它的价值,如果研究出来的东西一文不值,那.....)
目录:
一、计算机视觉是什么
二、计算机视觉里的一些应用方向现在认识有限以后遇到了再添加
2-1. 物体识别和检测
2-2. 语义分割
2-3. 运动和跟踪
2-4. 视觉问答
2-5. 三维重建
三、图像处理和计算机视觉的分类
四、图像处理与计算机视觉涉及的知识和相关的书籍太深入的就不说了这里只浅显的介绍一下欢迎批评指正
4-1. 数学知识
4-2. 信号处理
4-3. 模式识别
4-4. 图像处理与计算机视觉的书籍推荐
4-5. 小结
五、图像处理绕不开的工具--OpenCV
六、结语
一、计算机视觉是什么:
计算机视觉(Computer Vision)又称为机器视觉(Machine Vision),顾名思义是一门“教”会计算机如何去“看”世界的学科。在机器学习大热的前景之下,计算机视觉与自然语言处理(Natural Language Process, NLP)及语音识别(Speech Recognition)并列为机器学习方向的三大热点方向。而计算机视觉也由诸如梯度方向直方图(Histogram of Gradient, HOG)以及尺度不变特征变换(Scale-Invariant Feature Transform, SIFT)等传统的手办特征(Hand-Crafted Feature)与浅层模型的组合逐渐转向了以卷积神经网络(Convolutional Neural Network, CNN)为代表的深度学习模型。计算机视觉的理念其实与很多概念有部分重叠,包括:人工智能、数字图像处理、机器学习、深度学习、模式识别、概率图模型、科学计算以及一系列的数学计算等。
![]()
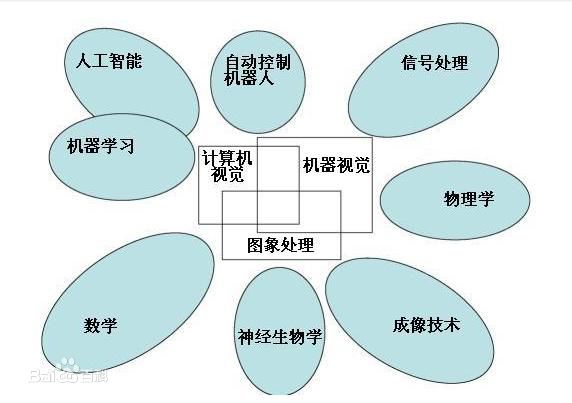
二、计算机视觉里的一些应用方向(现在认识有限,以后遇到了再添加):
(一)、物体识别和检测:
物体检测一直是计算机视觉中非常基础且重要的一个研究方向,物体识别和检测,顾名思义,即给定一张输入图片,算法能够自动找出图片中的常见物体,并将其所属类别及位置输出出来。当然也就衍生出了诸如人脸检测(Face Detection),车辆检测(Viechle Detection)等细分类的检测算法。

(二)语义分割:
图像语义分割(semantic segmentation),从字面意思上理解就是让计算机根据图像的语义来进行分割,语义在语音识别中指的是语音的意思,在图像领域,语义指的是图像的内容,对图片意思的理解。
![]()

目前语义分割的应用领域主要有:地理信息系统、无人车驾驶、医疗影像分析、机器人等领域,详细见:计算机视觉之语义分割
(三)运动和跟踪:
跟踪也属于计算机视觉领域内的基础问题之一,在近年来也得到了非常充足的发展,方法也由过去的非深度算法跨越向了深度学习算法,精度也越来越高,不过实时的深度学习跟踪算法精度一直难以提升,而精度非常高的跟踪算法的速度又十分之慢,因此在实际应用中也很难派上用场。 视觉跟踪是指对图像序列中的运动目标进行检测、提取、识别和跟踪,获得运动目标的运动参数,如位置、速度、加速度和运动轨迹等,从而进行下一步的处理与分析,实现对运动目标的行为理解,以完成更高一级的检测任务。跟踪算法需要从视频中去寻找到被跟踪物体的位置,并适应各类光照变换,运动模糊以及表观的变化等。但实际上跟踪是一个不适定问题(ill posed problem),比如跟踪一辆车,如果从车的尾部开始跟踪,若是车辆在行进过程中表观发生了非常大的变化,如旋转了180度变成了侧面,那么现有的跟踪算法很大的可能性是跟踪不到的,因为它们的模型大多基于第一帧的学习,虽然在随后的跟踪过程中也会更新,但受限于训练样本过少,所以难以得到一个良好的跟踪模型,在被跟踪物体的表观发生巨大变化时,就难以适应了。所以,就目前而言,跟踪算不上是计算机视觉内特别热门的一个研究方向,很多算法都改进自检测或识别算法。
![]()
(四)视觉问答:
视觉问答也简称VQA(Visual Question Answering),是近年来非常热门的一个方向,一般来说,VQA系统需要将图片和问题作为输入,结合这两部分信息,产生一条人类语言作为输出。针对一张特定的图片,如果想要机器以自然语言处理(NLP)来回答关于该图片的某一个特定问题,我们需要让机器对图片的内容、问题的含义和意图以及相关的常识有一定的理解。就其本性而言,这是一个多学科研究问题。

(五)三维重建:
基于视觉的三维重建,指的是通过摄像机获取场景物体的数据图像,并对此图像进行分析处理,再结合计算机视觉知识推导出现实环境中物体的三维信息。三维重建技术的重点在于如何获取目标场景或物体的深度信息。在景物深度信息已知的条件下,只需要经过点云数据[4]的配准及融合,即可实现景物的三维重建。基于三维重建模型的深层次应用研究也可以随即展开。学习图像处理的人会接触到更广泛更多元的技术,而三维重建背景的会非常专注于细分的算法,因为三维重建本身还有更细分的技术,所以在做研究生阶段的学习的时候,会有很具体的专业方向,比如说就是做航拍地形的三维重建,或者是佛像的三维重建,这里面因为场景的区别运用到的拍摄技术和重建技术都是不一样的,而且有一些不同技术之间也没有关系(当然三维重建本身的概念是相同的)。关于三维重建未来的热点和难度,这个领域可以做的很专,场景也有很多,每个场景都有不同的挑战,深入的我也不懂就不说了。
![]()

三、图像处理和计算机视觉的分类:
按照当前流行的分类方法,可以分为以下三部分:
- A.图像处理:对输入的图像做某种变换,输出仍然是图像,基本不涉及或者很少涉及图像内容的分析。比较典型的有图像变换,图像增强,图像去噪,图像压 缩,图像恢复,二值图像处理等等。基于阈值的图像分割也属于图像处理的范畴。一般处理的是单幅图像。
- B.图像分析:对图像的内容进行分析,提取有意义的特征,以便于后续的处理。处理的仍然是单幅图像。
- C.计算机视觉:对图像分析得到的特征进行分析,提取场景的语义表示,让计算机具有人眼和人脑的能力。这时处理的是多幅图像或者序列图像,当然也包括部分单幅图像。
关于图像处理,图像分析和计算机视觉的划分并没有一个很统一的标准。一般的来说,图像处理的书籍总会或多或少的介绍一些图像分析和计算机视觉的知识,比如冈萨雷斯的数字图像处理。而计算机视觉的书籍基本上都会包括图像处理和图像分析,只是不会介绍的太详细。其实图像处理,图像分析和计算机视觉都可以纳入到计算机视觉的范畴:图像处理->低层视觉(low level vision),图像分析->中间层视觉(middle level vision),计算机视觉->高层视觉(high level vision)。这是一般的计算机视觉或者机器视觉的划分方法。在本文中,仍然按照传统的方法把这个领域划分为图像处理,图像分析和计算机视觉。
四、图像处理与计算机视觉涉及的知识和相关的书籍(太深入的就不说了,这里只浅显的介绍一下(欢迎批评指正~)):
(一)、数学知识:
我们所说的图像处理实际上就是数字图像处理,是把真实世界中的连续三维随机信号投影到传感器的二维平面上,采样并量化后得到二维矩阵。数字图像处理就是二维矩阵的处理,而从二维图像中恢复出三维场景就是计算机视觉的主要任务之一。这里面就涉及到了图像处理所涉及到的三个重要属性:连续性,二维矩阵,随机性。所对应的数学知识是高等数学(微积分),线性代数(矩阵论),概率论和随机过程。这三门课也是考研数学的三个组成部分,构成了图像处理和计算机视觉最基础的数学基础。如果想要更进一步,就要到网上搜搜林达华推荐的数学书目了。
CV是一个涉及面非常广的学科,目前主流的依据视觉的学习,涉及到概率统计,各类优化方法,图论;一些研究方向(比如涉及到物体运动的)还会涉及拓扑学,群论,矩阵优化;一些图像分割算法,比如level-set,会涉及到微分方程等等。这些也都不是绝对区分的,现在的state-of-art的问题各方面可能都会有所涉及,依据问题本身而已。涉及面太广但是计算机的研究大多只是涉及,并不一定需要像数学系那样严密的推导。
(二)、信号处理
图像处理其实就是二维和三维信号处理,而处理的信号又有一定的随机性,因此经典信号处理和随机信号处理都是图像处理和计算机视觉中必备的理论基础。
2.1经典信号处理
信号与系统(第2版) Alan V.Oppenheim等著 刘树棠译
离散时间信号处理(第2版) A.V.奥本海姆等著 刘树棠译
数字信号处理:理论算法与实现 胡广书 (编者)
2.2随机信号处理
现代信号处理 张贤达著
统计信号处理基础:估计与检测理论 Steven M.Kay等著 罗鹏飞等译
自适应滤波器原理(第4版) Simon Haykin著 郑宝玉等译
2.3 小波变换
信号处理的小波导引:稀疏方法(原书第3版) tephane Malla著, 戴道清等译
2.4 信息论
信息论基础(原书第2版) Thomas M.Cover等著 阮吉寿等译
(三)、模式识别
Pattern Recognition and Machine Learning Bishop, Christopher M. Springer
模式识别(英文版)(第4版) 西奥多里德斯著
Pattern Classification (2nd Edition) Richard O. Duda等著
Statistical Pattern Recognition, 3rd Edition Andrew R. Webb等著
模式识别(第3版) 张学工著
(四)、 图像处理与计算机视觉的书籍推荐
图像处理,分析与机器视觉 第三版 Sonka等著 艾海舟等译
Image Processing, Analysis and Machine Vision
( 附:这本书是图像处理与计算机视觉里面比较全的一本书了,几乎涵盖了图像视觉领域的各个方面。中文版的个人感觉也还可以,值得一看。)
数字图像处理 第三版 冈萨雷斯等著
Digital Image Processing
(附:数字图像处理永远的经典,现在已经出到了第三版,相当给力。我的导师曾经说过,这本书写的很优美,对写英文论文也很有帮助,建议购买英文版的。)
计算机视觉:理论与算法 Richard Szeliski著
Computer Vision: Theory and Algorithm
(附:微软的Szeliski写的一本最新的计算机视觉著作。内容非常丰富,尤其包括了作者的研究兴趣,比如一般的书里面都没有的Image Stitching和 Image Matting等。这也从另一个侧面说明这本书的通用性不如Sonka的那本。不过作者开放了这本书的电子版,可以有选择性的阅读。
http://szeliski.org/Book/
Multiple View Geometry in Computer Vision 第二版Harley等著
引用达一万多次的经典书籍了。第二版到处都有电子版的。第一版曾出过中文版的,后来绝版了。网上也可以找到中英文版的电子版。)
计算机视觉:一种现代方法 DA Forsyth等著
Computer Vision: A Modern Approach
MIT的经典教材。虽然已经过去十年了,还是值得一读。期待第二版
Machine vision: theory, algorithms, practicalities 第三版 Davies著
(附:为数不多的英国人写的书,偏向于工业应用。)
数字图像处理 第四版 Pratt著
Digital Image Processing
(附:写作风格独树一帜,也是图像处理领域很不错的一本书。网上也可以找到非常清晰的电子版。)
(五)、小结
罗嗦了这么多,实际上就是几个建议:
(1)基础书千万不可以扔,也不能低价处理给同学或者师弟师妹。不然到时候还得一本本从书店再买回来的。钱是一方面的问题,对着全新的书看完全没有看自己当年上过的课本有感觉。
(2)遇到有相关的课,果断选修或者蹭之,比如随机过程,小波分析,模式识别,机器学习,数据挖掘,现代信号处理甚至泛函。多一些理论积累对将来科研和工作都有好处。
(3)资金允许的话可以多囤一些经典的书,有的时候从牙缝里面省一点都可以买一本好书。不过千万不要像我一样只囤不看。
五、图像处理绕不开的工具--OpenCV:
OpenCV的全称,是Open source Computer Vision Library,开放源代码计算机视觉库。也就是说,它是一套关于计算机视觉的开放源代码的API函数库。这也就意味着,(1)不管是科学研究,还是商业应用,都可以利用它来作开发;(2)所有API函数的源代码都是公开的,你可以看到其内部实现的程序步骤;(3)你可以修改OpenCV的源代码,编译生成你需要的特定API函数。但是,作为一个库,它所提供的,仅仅是一些常用的,经典的,大众化的算法的API。一个典型的计算机视觉算法,应该包含以下一些步骤:(1)数据获取(对OpenCV来说,就是图片);(2)预处理;(3)特征提取;(4)特征选择;(5)分类器设计与训练;(6)分类判别;而OpenCV对这六个部分,分别(记住这个词)提供了API。
你可以将它理解为幼儿园小朋友过家家玩的积木,而OpenCV中的函数,则可以理解为一个一个的积木块,利用所有或者部分积木块,你可以快速的搭建起来具体的计算机视觉方面的应用(比如,字符识别,车牌识别,遗留物检测)。想必你也已经发现,在利用OpenCV这个积木来搭建具体的计算机视觉应用的时候,真正核心的,应该是这些积木块,如果你明白了积木块的工作原理,那么,是不是就可以不用这些积木块了呢?完全正确!不过,一般部分情况下,我们不需要这么做,因为,OpenCV已经帮你做好了一些工作(已经帮你做好了一些积木块,直接拿来用就是了)。但是,诸如前面提到的特征提取模块,很多情况下,OpenCV就无能为力了。这个时候,你就需要翻阅计算机视觉、模式识别、机器学习领域顶级会议、期刊、杂志上面发表的文章了。然后,根据这些文章中阐述的原理和方法,来编程实现你要的东西。实际上,也就等于搭建一个属于你私有的积木块。其实,OpenCV中的每一个API函数,也就是这么来的。
如今,来自世界各地的各大公司、科研机构的研究人员,共同维护支持着opencv的开源库开发。这些公司和机构包括:微软,IBM,索尼、西门子、google、intel、斯坦福、MIT、CMU、剑桥........
六、结语:
随着深度学习的大举侵入,现在几乎所有人工智能方向的研究论文几乎都被深度学习占领了,传统方法已经很难见到了。有时候在深度网络上改进一个非常小的地方,就可以发一篇还不错的论文。并且,随着深度学习的发展,很多领域的现有数据集内的记录都在不断刷新,已经向人类记录步步紧逼,有的方面甚至已经超越了人类的识别能力。
目前来看计算机视觉的研究处在一个非常好的时期,有很多我们原来解不了的问题现在能够解得比较好了,像人脸识别,尽管我们其实还没有从真正意义上达到人类视觉系统对人脸识别的鲁棒程度。但我们离真正让计算机能够像人看和感知这个世界还有很远的距离。在我们达到这个目标之前,深度学习的方法可能是这个过程中一个重要的垫脚石,同时我们还要将更多的新的方法和工具带入这个领域来进一步推动这个领域的发展。
人的精力是有限的,这就意味着我们不可能把很多事情同时做好,所以在你选好方向之后,就要把我们的精力集中在你感兴趣的一个问题上, 努力成为这个方面的专家。研究是一项长跑,很多时候,我们在一个方向上比别人坚持久一点, 就有机会超越他而成为某个方面的专家。
图像处理就是一个典型的门槛低、厅堂深的领域。不需要太多基础,学过线性代数,会一点编程就够了;但是那些算法却深不可测,是个消耗功夫的活儿。不仅仅针对图像处理,对于其他新技术的入门学习也是一样,尽快迈出第一步,尽快去建立自信和成就感,让自己有勇气走下去,然后缺什么补什么就行了。我觉得真正让人望而却步的往往不是技术本身,而是我们对自身的不自信。唯有果断开工,才能战胜心魔。(https://blog.csdn.net/u013088062/article/details/50425018)
参考文档:
https://www.zhihu.com/question/26836846
https://blog.csdn.net/carson2005/article/details/6979806
https://blog.csdn.net/wangss9566/article/details/54618507
https://blog.csdn.net/qq_26499769/article/details/78989088
http://blog.csdn.net/dcraw