参考:https://zhuanlan.zhihu.com/p/29367273
https://blog.csdn.net/gwplovekimi/article/details/89890510?ops_request_misc=%257B%2522request%255Fid%2522%253A%2522164050890016780264068817%2522%252C%2522scm%2522%253A%252220140713.130102334…%2522%257D&request_id=164050890016780264068817&biz_id=0&utm_medium=distribute.pc_search_result.none-task-blog-2 alltop_positive~default-1-89890510.first_rank_v2_pc_rank_v29&utm_term=%E6%B7%B1%E5%BA%A6%E5%8F%AF%E5%88%86%E7%A6%BB%E5%8D%B7%E7%A7%AF&spm=1018.2226.3001.4187
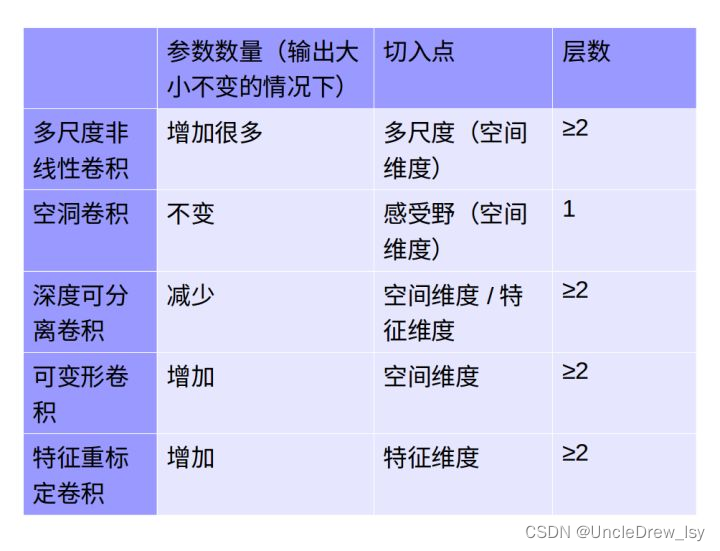
一、2D
单通道版本和多通道版本。
初始版本:
LeNet:最早使用stack单卷积+单池化结构的方式,卷积层来做特征提取,池化来做空间下采样
AlexNet:后来发现单卷积提取到的特征不是很丰富,于是开始stack多卷积+单池化的结构
VGG:结构没怎么变,网络深度增加。
Inception:先用1*1的卷积映射到隐空间,再在隐空间做卷积的结构。同时考虑了多尺度,在单层卷积层中用多个不同大小的卷积核来卷积,再把结果concat起来
二、3D
在 3D 卷积中,过滤器的深度要比输入层的深度更小(卷积核大小<通道大小),结果是,3D 过滤器可以沿着所有 3 个方向移动(高、宽以及图像的通道)。每个位置经过元素级别的乘法和算法都得出一个数值。由于过滤器滑动通过 3D 空间,输出的数值同样也以 3D 空间的形式呈现,最终输出一个 3D 数据。
三、空洞卷积(Dilation卷积)
扩张卷积引入另一个卷积层的参数被称为扩张率。这定义了内核中值之间的间距。扩张速率为2的3x3内核将具有与5x5内核相同的视野,而只使用9个参数。也可以看作使用5x5内核并删除每个间隔的行和列。(如下图所示)层数layer成线性关系,而空洞卷积的感受野是指数级的增长

系统能以相同的计算成本,提供更大的感受野。扩张卷积在实时分割领域特别受欢迎。 在需要更大的观察范围,且无法承受多个卷积或更大的内核,可以才用它。
pooling下采样操作导致的信息丢失是不可逆的,通常的分类识别模型,只需要预测每一类的概率,所以我们不需要考虑pooling会导致损失图像细节信息的问题,但是做像素级的预测时(譬如语义分割),就要考虑到这个问题了
所以就要有一种卷积代替pooling的作用(成倍的增加感受野),而空洞卷积就是为了做这个的。通过卷积核插“0”的方式,它可以比普通的卷积获得更大的感受野。
四、深度可分离卷积(MobileNet和Xception)
把标准卷积分解成深度卷积(depthwise convolution)和逐点卷积(pointwise convolution)。这么做的好处就是可以再损失精度不多的情况下大幅度降低参数量和计算量。
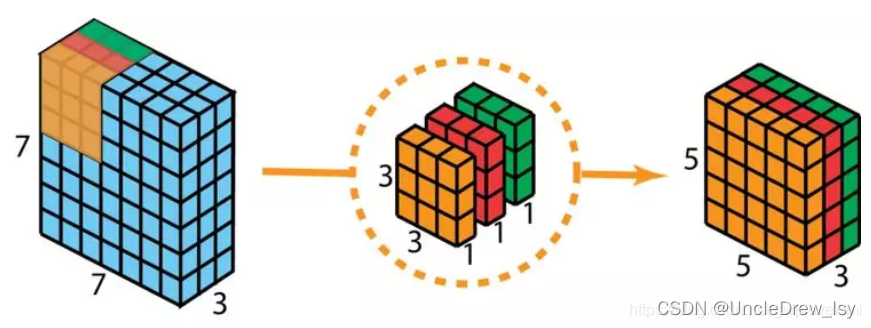
第一步:在 2D 卷积中分别使用 3 个卷积核(每个过滤器的大小为 3 x 3 x 1),而不使用大小为 3 x 3 x 3 的单个过滤器。每个卷积核仅对输入层的 1 个通道做卷积,这样的卷积每次都得出大小为 5 x 5 x 1 的映射,之后再将这些映射堆叠在一起创建一个 5 x 5 x 3 的图像,最终得出一个大小为 5 x 5 x 3 的输出图像。
第二步:扩大深度,用大小为 1x1x3 的卷积核做 1x1 卷积。每个 1x1x3 卷积核对 5 x 5 x 3 输入图像做卷积后都得出一个大小为 5 x 5 x1 的映射。做 128 次 1x1 卷积后,就可以得出一个大小为 5 x 5 x 128。
深度可分离卷积完成这两步后,同样可以将一个 7 x 7 x 3 的输入层转换为 5 x 5 x 128 的输出层。
从本质上说,深度可分离卷积就是3D卷积kernel的分解(在深度channel上的分解)。
优点:高效;
相比于 2D 卷积,深度可分离卷积的执行次数要少得多。
让我们回忆一下 2D 卷积案例中的计算成本:128 个 3x3x3 的卷积核移动 5x5 次,总共需要进行的乘法运算总数为 128 x 3 x 3 x 3 x 5 x 5 = 86,400 次。
那可分离卷积呢?在深度卷积这一步,有 3 个 3x3x3 的卷积核移动 5x5 次,总共需要进行的乘法运算次数为 3x3x3x1x5x5 = 675 次;在第二步的 1x1 卷积中,有 128 个 3x3x3 的卷积核移动 5x5 次,总共需要进行的乘法运算次数为 128 x 1 x 1 x 3 x 5 x 5 = 9,600 次。因此,深度可分离卷积共需要进行的乘法运算总数为 675 + 9600 = 10,275 次,花费的计算成本仅为 2D 卷积的 12%。
深度可分离卷积与 2D 卷积之间的乘法运算次数之比为:1/kernel_size的平方 + 1/c_out.(不加偏置的情况)
总结:深度可分离卷积也就是将一个(K_h , K_w , C_in ,C_out)的卷积拆分成了先用一个
(K_h , K_w , 1 ,C_in)和一个(1 ,1 , C_in ,C_out)的卷积,在大大减少参数量的情况下精度也没有下降多少。
五、空间可分离卷积
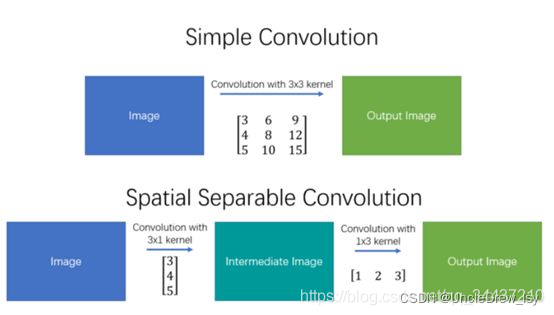
它主要处理图像和卷积核(kernel)的空间维度:宽度和高度。将kk的卷积核分解成k1k2,我们可以通过对k1和k2做2个一维卷积来取得。不是用9次乘法进行一次卷积,而是进行两次卷积,每次3次乘法(总共6次),以达到相同的效果。 乘法较少,计算复杂性下降,网络运行速度更快。但并不是所有的卷积核都可分。
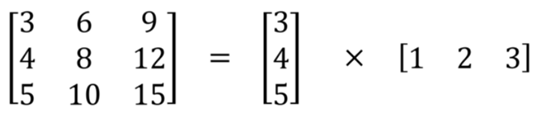
五、可变形卷积
可形变卷积的思想很巧妙:它认为规则形状的卷积核(比如一般用的正方形3*3卷积)可能会限制特征的提取,如果赋予卷积核形变的特性,让网络根据label反传下来的误差自动的调整卷积核的形状,适应网络重点关注的感兴趣的区域,就可以提取更好的特征。
如下图:网络会根据原位置,学习一个offset偏移量,得到新的卷积核,那么一些特殊情况就会成为这个更泛化的模型的特例,例如可以应用在旋转物体的识别。
六、反卷积
反卷积又称转秩卷积(Transposed Convolution),上采样(Upsampled )。1.当我们用神经网络生成图片的时候,经常需要将一些低分辨率的图片转换为高分辨率的图片。 2.在语义分割中,会使用卷积层在编码器中进行特征提取,然后在解码层中进行恢复为原先的尺寸,这样才可以对原来图像的每个像素都进行分类。这个过程同样需要用到转置卷积。反过来操作。我们想要将输入矩阵中的一个值映射到输出矩阵的9个值,这将是一个一对多(one-to-many)的映射关系。
从本质来说,转置卷积不是一个卷积,但是我们可以将其看成卷积,并且当成卷积这样去用。我们通过在输入矩阵中的元素之间插入0进行补充,从而实现尺寸上采样,然后通过普通的卷积操作就可以产生和转置卷积相同的效果了。你在一些文章中将会发现他们都是这样解释转置卷积的,但是这个因为在卷积操作之前需要通过添加0进行上采样,因此是比较低效率的。
总结