1.引言
介绍CNN(Convolutional Neural Networks)概念。
详细介绍CNN所涉及到的数学公式以及如何理解这些数学公式。
CNN的实际应用与优缺点。
结合tensorflow快速实现CNN架构。
2.CNN架构与涉及到的概念
2.1卷积的概念
卷积在图像处理中用于平滑窗口,滤波去噪等操作。在CNN中是为了提取特征。将像素级别的特征用局部感受野收集。如下图:
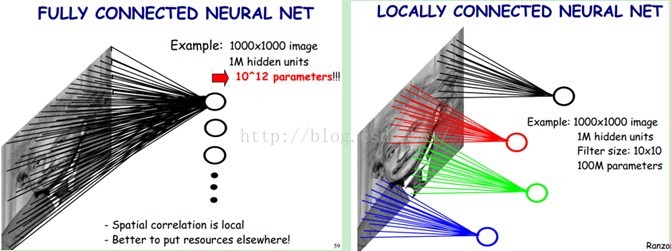
如左图,如果输入图片是1000*1000像素的图片,隐层有10^6个神经单元,那么如果采用像素级别的全连接模型,则会有1000*1000*10^6 = 10^12个连接,相当于在一次训练过程中就会有有10^12个参数需要学习,非常耗时,并且提取到的特征不具有具体的含义。
如右图,局部感受野:类似于卷积中的patch核,将10^6的隐层换成10*10的patch,即1000*1000的图片采用10*10的局部感受野,将像素级别的特征映射到这个局部感受野,那么 此时则有1000*1000×100=10^8个参数需要学习。此时,图像中的每一个像素点学习一个10*10的局部感受野。
2.1.1CNN的权值共享机制
上面提到了如果使用了patch(也就是局部感受野),则会将参数下降到10^8级别,但是这中规模的参数学习仍旧很多。那么是否可以让图片中的所有像素点公用这一个patch。答案是可以的,这就是CNN的权值共享机制。图片中的所有像素点使用同一个patch10*10个权值。因此,学习参数由原来的1000*1000*10^6降到了10*10,不过由于仅仅在图片中提取一个特征 是远远不够的,因此,可以对一张输入图片采用多个卷积核patch来提取多个特征,这样最终的结果是10*10×n(n表示使用卷积核的数量)。
2.1.2卷积的数学计算方式
如下图,一个6*6的图片I 使用卷积核F进行卷积,得到输出图片O。输入图片中在patch范围内的元素和卷积核中对应的元素相乘,最后乘积结果相加。
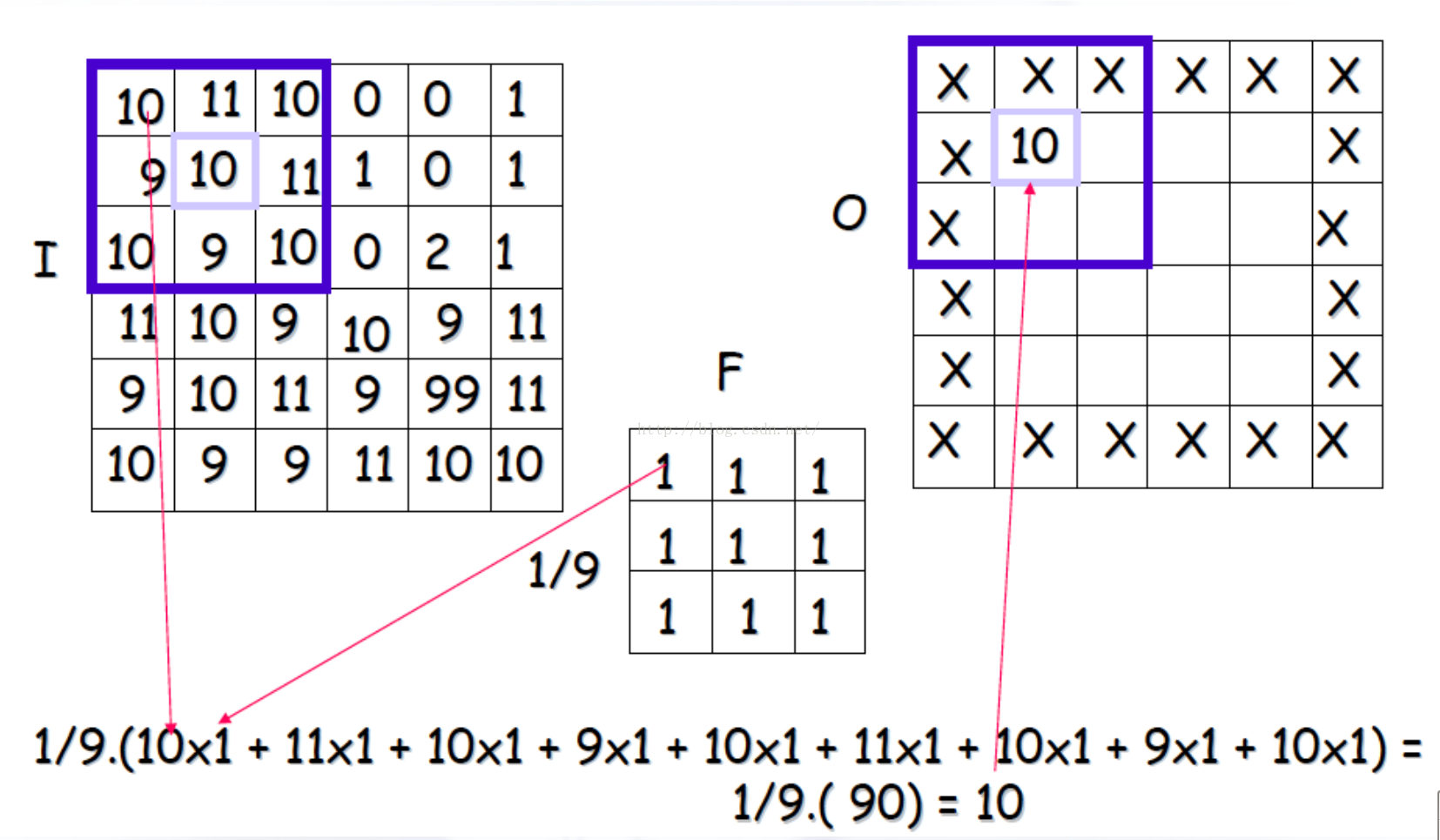
在卷积中,有两个重要的概念:
(1)stride(滑动步长):每一次patch向前滑动的距离。
(2)边界处理:SAME和VALID两种形式,VALID表示的是对边界不进行处理,就像上图一样,因此输出图片总是比输入图片小。
SAME表示的是对边界进行卷积处理,因此卷积后的图片和卷积前的图片的宽和高并没有改变。因为卷积核也会对原图片的边界进行卷积计算。
2.2池化的概念(pooling)
池化是卷积之后的特征聚合,对一个局部区域取一个最具有代表性的值来表示这个区域的特征,可以是特征图片进行降维。最常见的是2*2区域最大值池化。如下图:
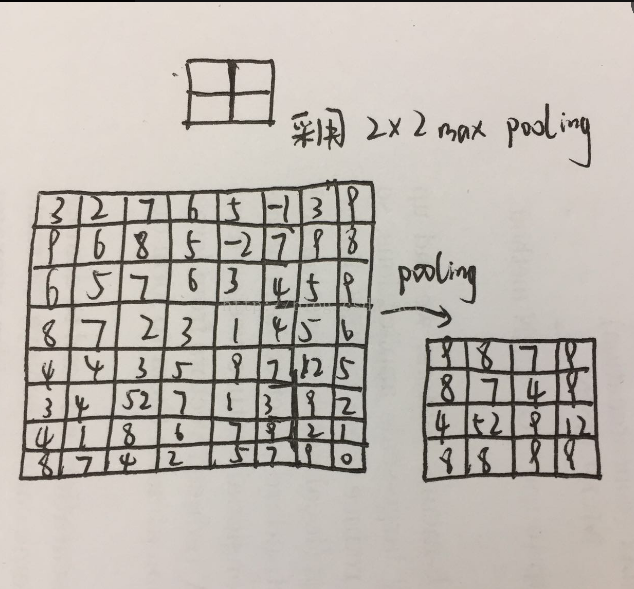
左边是8*8的输入图片,经过2*2maxpooling后生成4*4图片,其方法是在输入图片的每个2*2的区域取一个像素点的最大值,用这个值代替原图像2*2区域的值,并且进行降维。
此做法的目的:对特征进行聚合,并且在局部区域是特征具有了一定的invariance。(translation invariance,rotation invariance,scale invariance)
2.3CNN架构
有了卷积和池化的相关理解,现在可以初步的了解一下CNN架构:
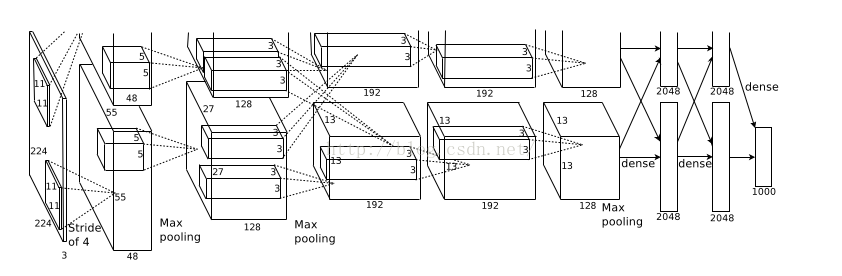
输入层是:224*224*3的图片,此时图片有三个维度:第一、二维是图片的像素值,第三个维度是原图片的RGB三通道。
第一层卷积核采用patch11*11*3,使用stride=4,边界采用VALID。生成96个feature maps,生成的图片55*55大小,计算方式是使用11*11的patch对224*224的图片进行卷积得到的图片大小。之后将这96个feature maps分别使用两个GPU进行计算,用RELU激活函数,之后进行归一化和池化,那么在每个GPU上存在48个feature maps,因此图片的第三个维度由3变成了48,相当于48个feature maps叠加在一起。
因此第二层的卷积核应该是n×n×48,48是第一层生成的特征维度,n的值自己定义,但是不能超过输入图片的大小。第二层生成256张feature maps。每个GPU承担128张。第二层卷积的输出图片是27*27大小的,是因为第二层卷积边界采用SAME,55*55的图片规模不变,但是55*55的图片在第一层卷积网之后进行池化,规模变成27*27的图片,作为第三层卷积的输入。
如下图:卷积1层输入224*224*3个参数,卷积1层输出55*55*96的特征图,后面的池化层输出27*27*96的特征图;卷积2层的输入是27*27*96的特征图,输出是27*27*384的特征图,经过卷积2层的池化层后得到13*13*384的输出。
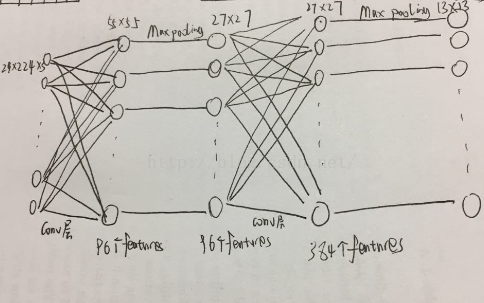
第三、四、五层卷积层的原理与前一层类似。
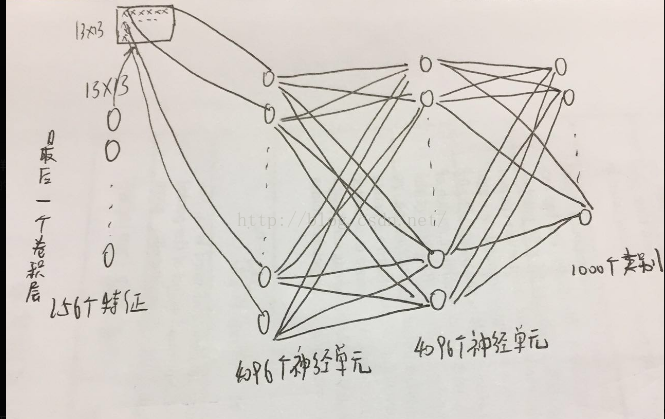
全连接层:与卷积层不同的是,全连接层的每一个输入节点都完全连接到输出节点。
如下图:在最后一个卷积层生成的13*13*256的图片中的每一个像素点都需要和4096个神经元建立连接,之后每个神经元都需要与下一层神经元建立连接。这种方式会导致overfitting,因此在每一个全连接层的神经激活函数之后需要采用dropout的方式进行降拟合。
tensorflow实现是:
#采用3×3*384的patch对上一层的特征图进行卷积。
W_conv5 = weight_variable([3
,3
, 384
,256
])
b_conv5 = bias_variable([256
])
#卷积后采用relu神经激活函数加入非饱和非线性因素,其中h_conv4是上一层的3*3*384的特征图。
h_conv5 = tf.nn.relu(conv2d(h_conv4, W_conv5) + b_conv5)
#将13*13*256特征图片中的每个像素点与4096个神经单元相连接。
W_fc1 = weight_variable([13
*13
* 256
,4096
])
b_fc1 = bias_variable([4096
])
#将卷积5层的输出转为1*13*13*256的矩阵。
h_conv5_flat = tf.reshape(h_conv5, [-1, 13
*13
*256
])
#使用relu神经单元进行激活。
h_fc1 = tf.nn.relu(tf.matmul(h_conv5_flat, W_fc1) + b_fc1)
keep_prob = tf.placeholder("float")
#对全连接层造成的过拟合问题去拟合。
h_fc1_drop = tf.nn.dropout(h_fc1, keep_prob)
h_fc1_drop = tf.nn.dropout(h_fc1, keep_prob)
3.CNN架构的优缺点
优点:(1)由于maxpooling层的存在,因此CNN在小范围内具有几何不变性,但是对于大范围就不具备这种几何不变性。
(2)特征的分类:
下图是通过deconvnet方法(包括反池化,反激活,反卷积方式)得到的每一个卷基层特征图的可视化表达。
可以看到layer1卷积层提取到的是颜色特征。
layer2提取到的是边缘特征。
layer3提取到的就是一些纹理特征。
从layer4开始就具备一些结构性的特征。

(3)收敛速度快
缺点:(1)卷积网络层次太深,使用BP传播来修改参数会使得靠近输入层的layer改动较慢。
(2)使用gradient descent方法的收敛速度与选取的w和b的初始值有关。
(3)使用gradient descent方法很容易使得训练的效果收敛到局部最小值而不是全局最小值。
4.CNN中没有提到的技术点
(1)CNN提取到的特征是否能够支持几何不变性(平移,旋转,缩放)
参考资料
[1] ImageNet Classification with Deep Convolutional Neural Networks CNN的开山作
[2] http://www.36dsj.com/archives/24006 CNN的技术简述