概述
深度学习中CNN网络是核心,对CNN网络来说卷积层与池化层的计算至关重要,不同的步长、填充方式、卷积核大小、池化层策略等都会对最终输出模型与参数、计算复杂度产生重要影响,本文将从卷积层与池化层计算这些相关参数出发,演示一下不同步长、填充方式、卷积核大小计算结果差异。
一:卷积层
卷积神经网络(CNN)第一次提出是在1997年,杨乐春(LeNet)大神的一篇关于数字OCR识别的论文,在2012年的ImageNet竞赛中CNN网络成功击败其它非DNN模型算法,从此获得学术界的关注与工业界的兴趣。毫无疑问学习深度学习必须要学习CNN网络,学习CNN就必须明白卷积层,池化层等这些基础各层,以及它们的参数意义,从本质上来说,图像卷积都是离散卷积,图像数据一般都是多维度数据(至少两维),离散卷积本质上是线性变换、具有稀疏与参数重用特征即相同参数可以应用输入图像的不同小分块,假设有3x3离散卷积核如下: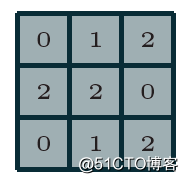
假设有
- 5x5的图像输入块
- 步长为1(strides=1)
- 填充方式为VALID(Padding=VALID)
- 卷积核大小filter size=3x3
则它们的计算过程与输出如下
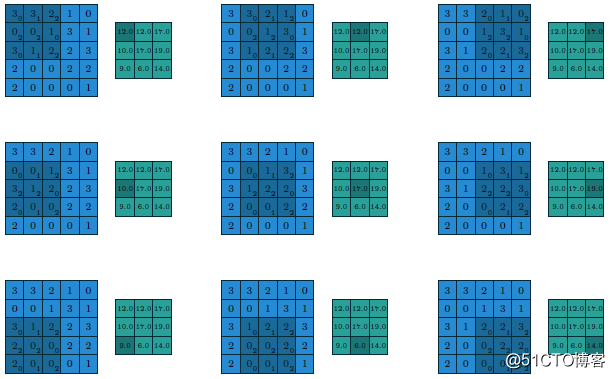
假设这个时候我们修改步长为2、填充方式为SAME,卷积核大小不变(strides=2 Padding=SAME filter size=3x3),则计算过程与输出变为如下:
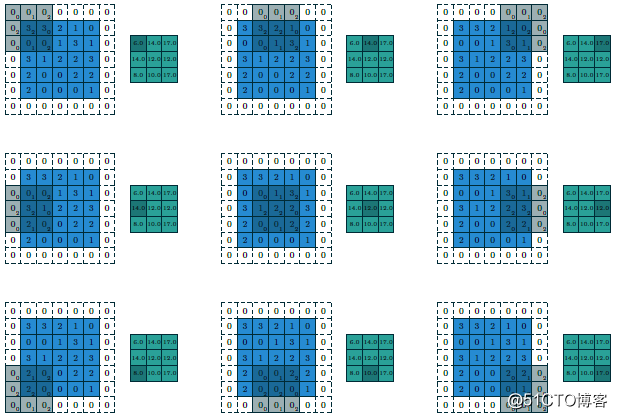
最终输出得到的结果我们可以称为featuremap,CNN的深度多数时候是指featuremap的个数,对多维度的输入图像计算多个卷积核,得到多个featuremap输出叠加,显示如下: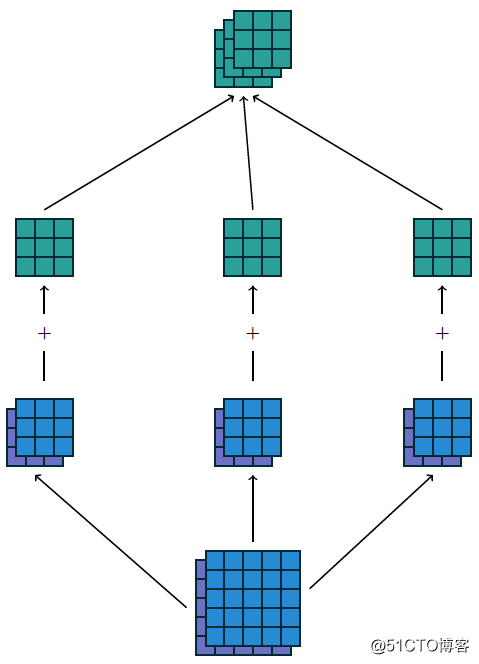
上述输入为5x5x2,使用卷积核3x3,输出3x3x3,填充方式为VALID,计算如果填充方式改为SAME则输出为5x5x3。可以看出填充方式对输出结果的影响。
二:小卷积核VS大卷积核
在AlexNet中有有11x11的卷积核与5x5的卷积核,但是在VGG网络中因为层数增加,卷积核都变成3x3与1x1的大小啦,这样的好处是可以减少训练时候的计算量,有利于降低总的参数数目。关于如何把大卷积核替换为小卷积核,本质上有两种方法。
1.将二维卷积差分为两个连续一维卷积
二维卷积都可以拆分为两个一维的卷积,这个是有数学依据的,所以11x11的卷积可以转换为1x11与11x1两个连续的卷积核计算,总的运算次数:
- 11x11 = 121次
- 1x11+ 11x1 = 22次
2.将大二维卷积用多个连续小二维卷积替代
可见把大的二维卷积核在计算环节改成两个连续的小卷积核可以极大降低计算次数、减少计算复杂度。同样大的二维卷积核还可以通过几个小的二维卷积核替代得到。比如:5x5的卷积,我们可以通过两个连续的3x3的卷积替代,比较计算次数
- 5x5= 25次
- 3x3+ 3x3=18次
三:池化层
在CNN网络中卷积池之后会跟上一个池化层,池化层的作用是提取局部均值与最大值,根据计算出来的值不一样就分为均值池化层与最大值池化层,一般常见的多为最大值池化层。池化的时候同样需要提供filter的大小、步长、下面就是3x3步长为1的filter在5x5的输入图像上均值池化计算过程与输出结果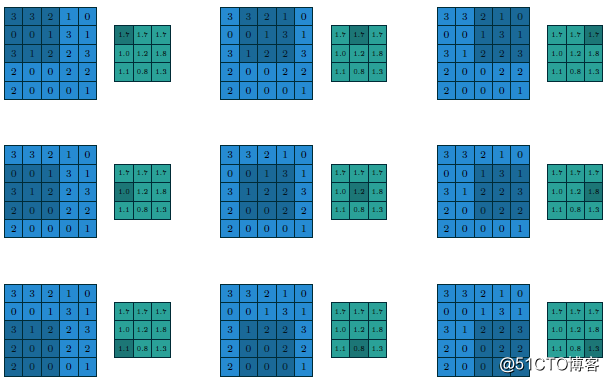
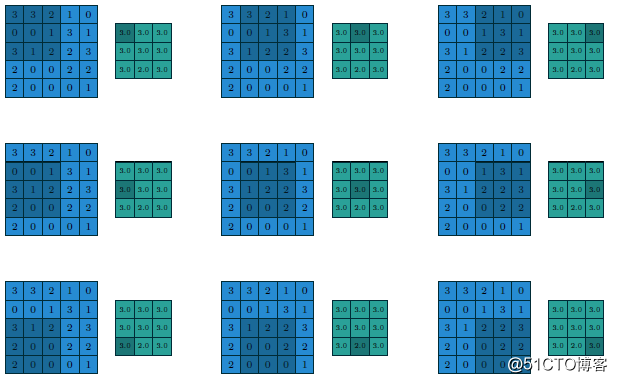
改用最大值做池化的过程与结果如下:
CNN一般是由输入层、卷积层、激活函数、池化层、全连接层
卷积层:用来进行特征的提取:
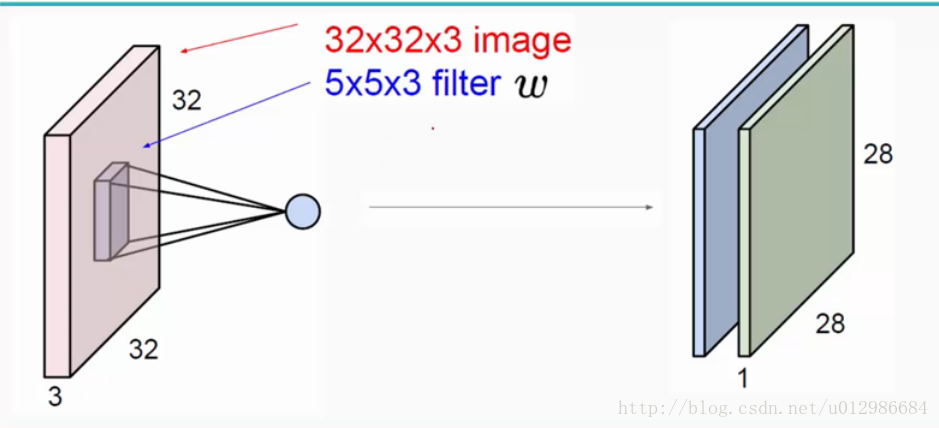
其中input image 32x32x3 其中3为他的通道数或者可以理解成深度(R、G、B),卷积层是一个5x5x3的filter w。filter (滤波或者成为感受野),其中filter同输入的image的通道数是相同的。
如上图,image(32x32x3)与filter W 做卷积生成得到28x28x1的特征图(feature map).
通常会使用多层卷积层来得到更加深层次的特征图,如下:

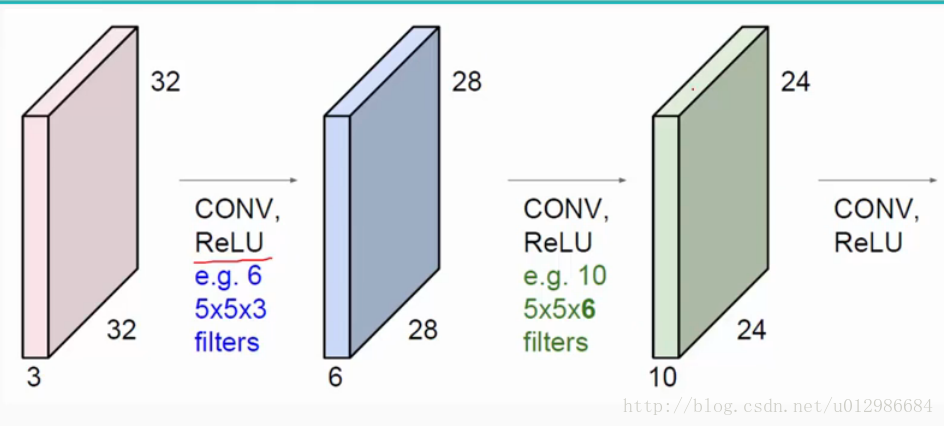
其中ReLU 为激活函数,一般是做卷积之后使用ReLU。
说下卷积的过程,如下所示:
连续:
一维卷积:s(t)=(x∗w)(t)=∫x(a)w(t−a)dt
二维卷积:S(t)=(K∗I)(i,j)=∫∫I(i,j)K(i−m,j−n)dmdn
离散:
一维卷积:s(t)=(x∗w)(t)=∑ax(a)w(t−a)
二维卷积:S(i,j)=(K∗I)(i,j)=∑m∑nI(i,j)K(i−m,j−n)
卷积具有交换性,即
(K∗I)(i,j)=(I∗K)(i,j)
∑m∑nI(i,j)K(i−m,j−n)=∑m∑nI(i−m,j−n)K(i,j)
编程实现中:
二维卷积:S(t)=(K∗I)(i,j)=∑m∑nI(i+m,j+n)K(i,j)
这个定义就不具有交换性
上面的w,K称为核,s(t),S(i,j)有时候称为特征映射。

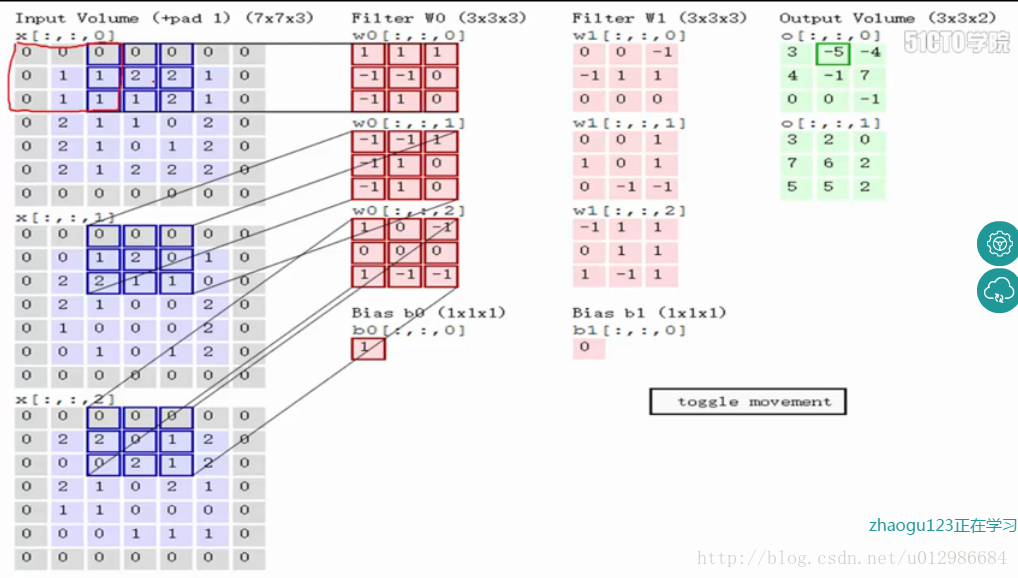
输入image 经过一次填充(pad=1),与感受野(filter)对应元素相乘再相加,最后加上Bias,得到feature map 。如图中所示,filter w0的第一层深度和输入图像的蓝色方框中对应元素相乘再求和得到0,其他两个深度得到2,0,则有0+2+0+1=3即图中右边特征图的第一个元素3.,卷积过后输入图像的蓝色方框再滑动,stride=2,如下:
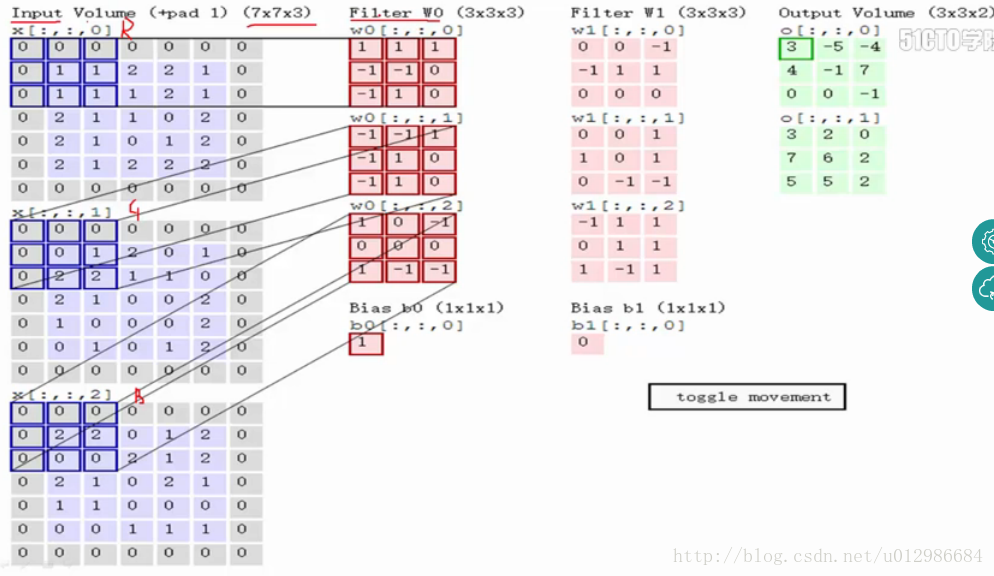
如上图,完成卷积,得到一个3*3*1的特征图;在这里还要注意一点,即zero pad项,即为图像加上一个边界,边界元素均为0.(对原输入无影响)一般有
F=3 => zero pad with 1
F=5 => zero pad with 2
F=7=> zero pad with 3,边界宽度是一个经验值,加上zero pad这一项是为了使输入图像和卷积后的特征图具有相同的维度,如:
输入为5*5*3,filter为3*3*3,在zero pad 为1,则加上zero pad后的输入图像为7*7*3,则卷积后的特征图大小为5*5*1((7-3)/1+1),与输入图像一样;
而关于特征图的大小计算方法具体如下:

卷积层还有一个特性就是“权值共享”原则。如下图: 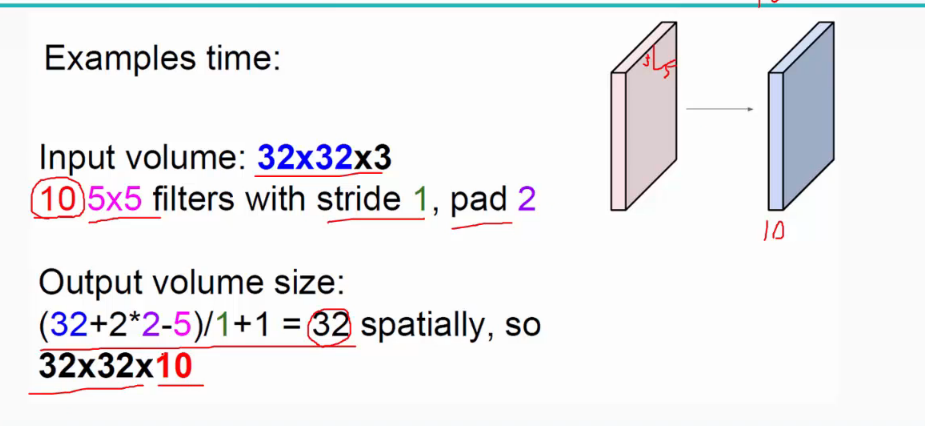
如没有这个原则,则特征图由10个32*32*1的特征图组成,即每个特征图上有1024个神经元,每个神经元对应输入图像上一块5*5*3的区域,即一个神经元和输入图像的这块区域有75个连接,即75个权值参数,则共有75*1024*10=768000个权值参数,这是非常复杂的,因此卷积神经网络引入“权值”共享原则,即一个特征图上每个神经元对应的75个权值参数被每个神经元共享,这样则只需75*10=750个权值参数,而每个特征图的阈值也共享,即需要10个阈值,则总共需要750+10=760个参数。
简而言之,所谓的权值共享就是说,给一张输入图片,用一个filter去扫这张图,filter里面的数就叫权重,这张图每个位置是被同样的filter扫的,所以权重是一样的,也就是共享。
池化层:对输入的特征图进行压缩,一方面使特征图变小,简化网络计算复杂度;一方面进行特征压缩,提取主要特征,如下:
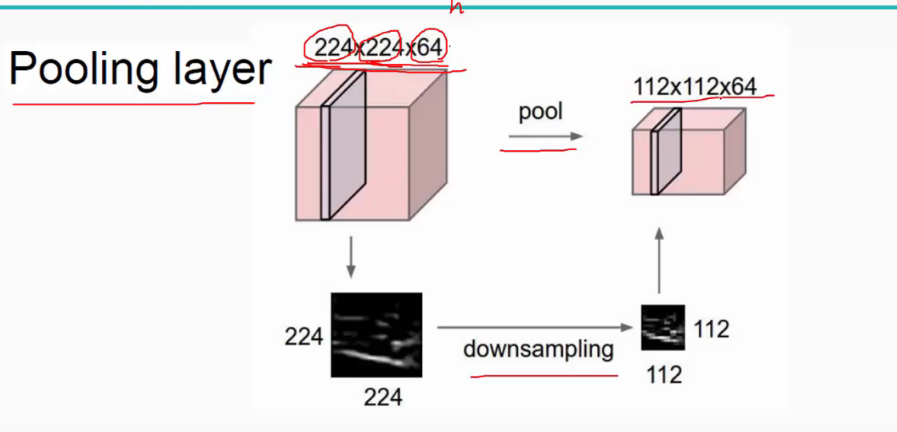
主要会做降采样(downsampling)
池化操作一般由两种,一种是Ava Pooling ,一种max Pooling 如下
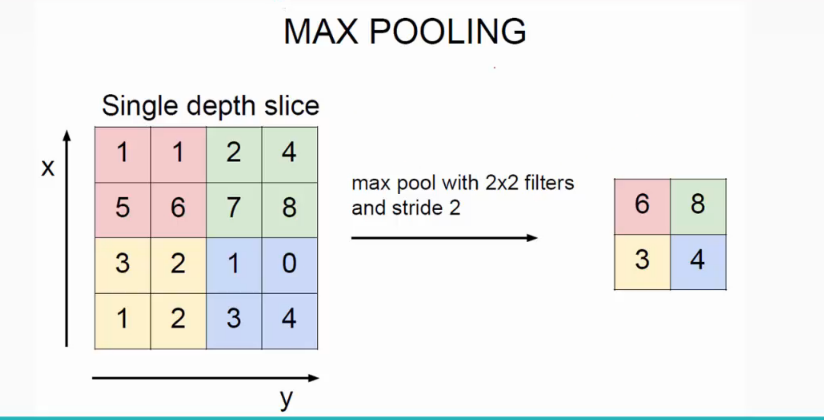
同样地采用一个2*2的filter,max pooling是在每一个区域中寻找最大值,这里的stride=2,最终在原特征图中提取主要特征得到右图。
(Avy pooling现在不怎么用了,方法是对每一个2*2的区域元素求和,再除以4,得到主要特征),而一般的filter取2*2,最大取3*3,stride取2,压缩为原来的1/4.
注意:这里的pooling操作是特征图缩小,有可能影响网络的准确度,因此可以通过增加特征图的深度来弥补(这里的深度变为原来的2倍)。
全连接层:连接所有的特征,将输出值送给分类器(如softmax分类器)。
总的一个结构大致如下:
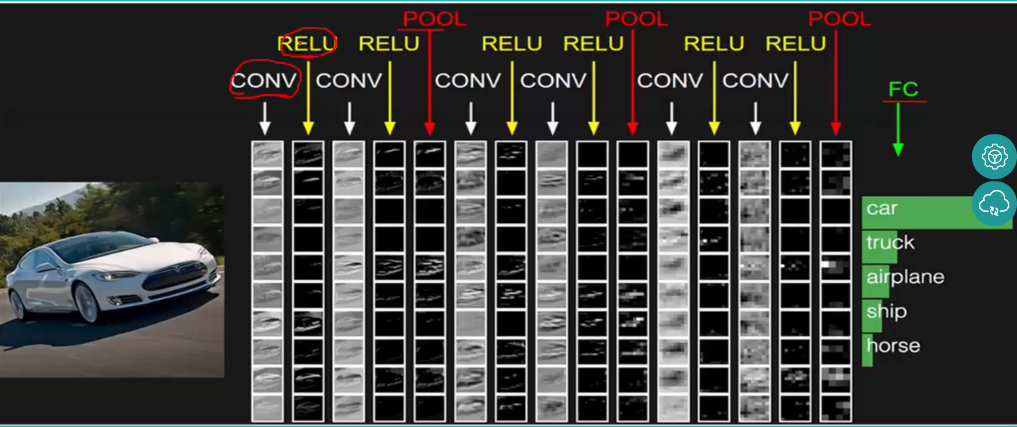
另外:CNN网络中前几层的卷积层参数量占比小,计算量占比大;而后面的全连接层正好相反,大部分CNN网络都具有这个特点。因此我们在进行计算加速优化时,重点放在卷积层;进行参数优化、权值裁剪时,重点放在全连接层。
卷积神经网络主要利用3个思想:稀疏连接、参数共享、平移不变性。
池化输出的是邻近区域的概括统计量,一般是矩形区域。池化有最大池化、平均池化、滑动平均池化、L2范数池化等。 池化能使特征获得平移不变性。如果我们只关心某些特征是否存在而不是在哪里时,平移不变性就很有用了。卷积也会产生平移不变性,注意区分,卷积对输入平移是不变的,池化对特征平移是不变的。
池化能显著地减少参数;池化能解决不同规格的输入的问题。