都2018了,已经有好多专业的大神,介绍卷积神经网络。这里就记录一下,我觉得写的最好的吧。^^
知乎:能否对卷积神经网络工作原理做一个直观的解释
个人专栏YJangGo:https://blog.csdn.net/u010751535
鼻祖的斯坦福文章:http://cs231n.github.io/convolutional-networks/
一个可视化界面,查看CNN效果的:http://scs.ryerson.ca/~aharley/vis/conv/
知识备忘
1. 卷积
卷积的Kernel本质是两个: 第一, kernel具有局域性, 即只对图像中的局部区域敏感, 第二, 权重共享。 也就是说我们是用一个kernel来扫描整个图像, 其中过程kernel的值是不变的。
判定一个图是猫,就是分析图都有啥特征。原来的卷积核都是人工事先定义好的,是经过算法设计人员精心设计的,他们发现这样或那样的设计卷积核通过卷积运算可以突出一个什么样的特征,于是就高高兴兴的拿去卷积了。但是现在我们所需要的这种特征太高级了,而且随任务的不同而不同,人工设计这样的卷积核非常困难。于是,利用机器学习的思想,我们可以让他自己去学习出卷积核来!也就是学习出特征!
如前所述,判断是否是一只猫,只有一个特征不够,比如仅仅有猫头是不足的,因此需要多个高级语义特征的组合,所以应该需要多个卷积核,这就是为什么需要学习多个卷积核的原因。
但是实际上CNN会学习出猫头、猫尾巴、猫身然后经判定这是猫吗?显然我们的CNN完全不知道什么叫猫头、猫尾巴,也就是说,CNN不知道什么是猫头猫尾巴,它学习到的只是一种抽象特征,甚至可能有些特征在现实世界并没有对应的名词,但是这些特征组合在一起计算机就会判定这是一只猫!
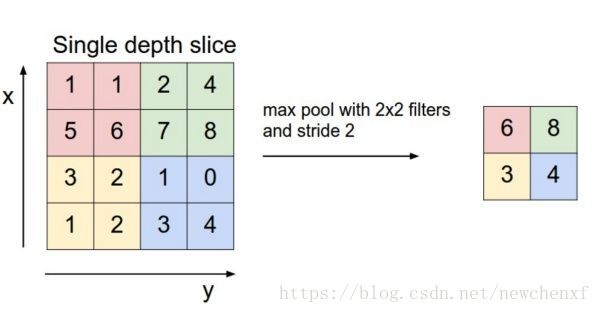
2. 池化pooling
池化的唯一目的是减少图像的空间大小。
pooling的方法很多,常见的叫做max pooling,就是找到相邻几个像素里值最大的那个作为代表其它扔掉。
3. 全连接层
当抓取到足以用来识别图片的特征后,接下来的就是如何进行分类。 全连接层(也叫前馈层)就可以用来将最后的输出映射到线性可分的空间。 通常卷积网络的最后会将末端得到的长方体平摊(flatten)成一个长长的向量,并送入全连接层配合输出层进行分类。
4. CNN
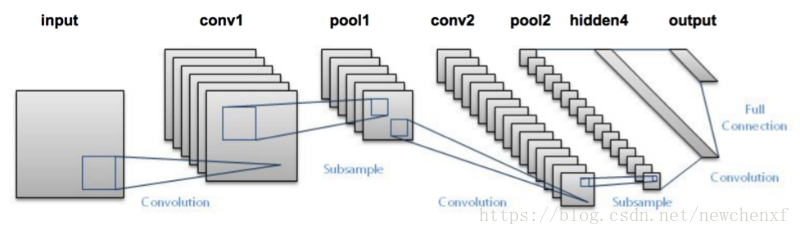
CNN的部件其实大致分为三个,卷积层、池化层、全连接层,这也是LeNet-5的经典结构,之后大部分CNN网络其实都是在这三个基本部件上做各种组合和改进。
LeNet-5在1998年由LeCun Yann(法国人)提出,当年就广泛用于银行,识别手写输入数字(32x32 pixel)。
ps: 其他CNN还有:AlexNet(2012), ZFNet(2013), GoogleNet(also named Inception, 2014), ResNet(2015)
conv1 + pool1 + conv2 + pool2, 可以认为是特征提取。 hidden4(全连接层), 可以认为是根据特征做分类。
这里也体现了深层神经网络或deep learning之所以称deep的一个原因:模型将特征抓取层和分类层合在了一起。 负责特征抓取的卷积层主要是用来学习“如何观察”。注意,卷积核的值,是我们要学习的,不是事先定义好的喔。