安装教程看我主页的另一个博客Microsoft Planetary Computer(MFC):完整记录跑通mmrotate的demo!_我要当太空人!爸爸妈妈可高兴了的博客-CSDN博客!这里默认你已经把所有的包都装好了,demo也能跑通了!
1.引入需要的包。
from mmdet.apis import init_detector, inference_detector, show_result_pyplot
import mmrotate
2.把数据集放在该放的地方。
如果大家是用juputer,那么需要传zip。可以这样解压。
# 解压
import zipfile
import os
"""
src_path:压缩包所在文件路径
target_path:压缩后文件存放路径
"""
src_path="/home/jovyan/mmrotate/data/DOTA2.zip"
target_path="/home/jovyan/mmrotate/data/DOTA2"
if(not os.path.isdir(target_path)):
z = zipfile.ZipFile(src_path, 'r')
z.extractall(path=target_path)
z.close()
## 下面开始用split! 先trainval再test!我传的文件叫做DOTA2.zip,之后改个名哈。
为了图方便,我就把自己的数据集命名成了DOTA,这样就不用改json文件了。建议大家都这么改。 无论是test还是train还是val,反正都是这样的一个样子,照官网的说法来放:

mmrotate
├── mmrotate
├── tools
├── configs
├── data
│ ├── DOTA
│ │ ├── train
│ │ ├── val
│ │ ├── test
到这一步,你的原始的数据集就放好了!
3.数据集裁剪
语法请参考我这一篇博客:mmrotate:数据集裁剪_我要当太空人!爸爸妈妈可高兴了的博客-CSDN博客
因为我是用云服务器的,死活修改不了json文件,所以我需要加上-ann-dirs data/DOTA/test/labelTxt/。但是大家不用哈!大家可以直接在json文件里面改!
大家注意!原本的ms_test.json是没有标签的路径的!要自己去填或者改!

所以官方的这个代码不是特别准确!它没有告诉我们要改json!
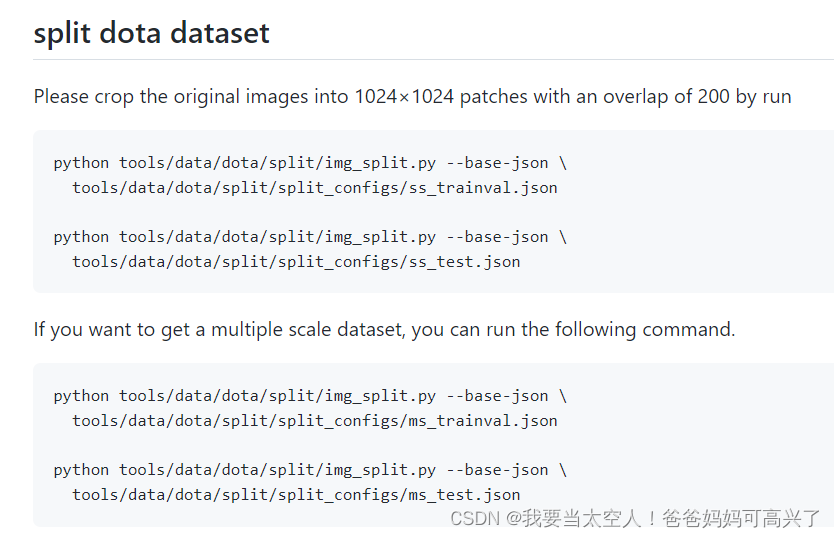
把代码贴过来
python tools/data/dota/split/img_split.py --base-json \
tools/data/dota/split/split_configs/ms_trainval.jsonpython tools/data/dota/split/img_split.py --base-json \
tools/data/dota/split/split_configs/ms_test.json
它会把裁剪好的数据放在mmrotate/data/split_ms_dota。
4.下载模型和权重
这样下载:我这里下载的是rotated_retinanet。大家可以在这里找到所有的config。
!mim download mmrotate --config rotated_retinanet_obb_r50_fpn_1x_dota_le90 --dest .
一般来说,去掉py就是模型的名字。但有时候没有,但它也会列出所有的模型的名字,自己看一下报错的详细内容应该可以搞定的。
5. 修改配置文件
这一步坑巨多了。
首先,在你放模型的路径底下,新建一个config文件。我新建的叫做my_config.py。请详细阅读官方的配置文件的讲解文档!认认真真看!教程 1:学习配置文件 — mmrotate 文档看完之后再修改自己的配置文件!
# 新配置继承了基础配置用于突出显示必要的修改
_base_ = './oriented_rcnn_r50_fpn_1x_dota_le90.py' # 修改这里的模型名称!
data_root = 'data/split_ms_dota/' # 修改这里的路径!
# 1. 数据集的设置
classes = ('ship',) # 修改这里的类别名称!
data = dict(
samples_per_gpu=2,
workers_per_gpu=2,
train=dict(
#注意将你的类名添加到字段 `classes`
classes=classes,
ann_file='data/split_ms_dota/trainval/annfiles/', #修改路径*6!
img_prefix='data/split_ms_dota/trainval/images/'),
val=dict(
#注意将你的类名添加到字段 `classes`
classes=classes,
ann_file='data/split_ms_dota/trainval/annfiles/',
img_prefix='data/split_ms_dota/trainval/images/'),
test=dict(
#注意将你的类名添加到字段 `classes`
classes=classes,
ann_file='data/split_ms_dota/test/annfiles',
img_prefix='/data/split_ms_dota/test/images'))
# # 2. 模型设置
model = dict(
roi_head=dict(
bbox_head=dict(
# 显式将所有 `num_classes` 字段从 15 重写为 1。
num_classes=1))) # 修改这里!
# 我们可以使用预训练的权重来获取更好的性能
load_from = 'oriented_rcnn_r50_fpn_1x_dota_le90-6d2b2ce0.pth' #修改这里!还需要修改dotav1.py的第二行!

还有修改dota.py的classes!

然后运行train.py!
!python tools/train.py my_config.py下面官方给的代码对我来说不好使!建议用我上面那个代码。
!mim train mmdet oriented_rcnn_r50_fpn_1x_dota_le90.py # 这个不好用!然后就可以快乐炼丹啦!