前言:
这次我们要做的是一个物堆(也可以是沙、矿堆之类)的数据集,用于语义分割。我们的工作,就是要使用labelme工具,利用原图1.jpg生成它的标签图片1.png,得到的最终结果像下面这样:
1. 安装 Anaconda3
具体安装步骤以及下载地址可见:Anaconda3+tensorflow2.0.0+PyCharm安装与环境搭建中的Anaconda3安装部分。已经安装过了可跳过这一步~
2. 安装 labelme
(1)第一步,打开Anaconda Prompt ,然后使用conda创建一个虚拟环境,并命名为labelme。
conda create -n labelme python=3.6
(2)进入创建好的虚拟环境
conda activate labelme
(3)下载安装labelme
pip install labelme
如果速度太慢的话,可改用清华镜像源下载(推荐),方法如下:
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple labelme
如果没有报错的话,到这一步你就安装完成了!
3. 使用 labelme
(1)打开 labelme 界面
在刚才创建的虚拟环境下,打开labelme。如下图所示:直接输入label,然后回车。

注:如果你之前不小心退出了labelme虚拟环境,需要重新进入该环境下。
打开之后,labelme的界面就像下面这样:
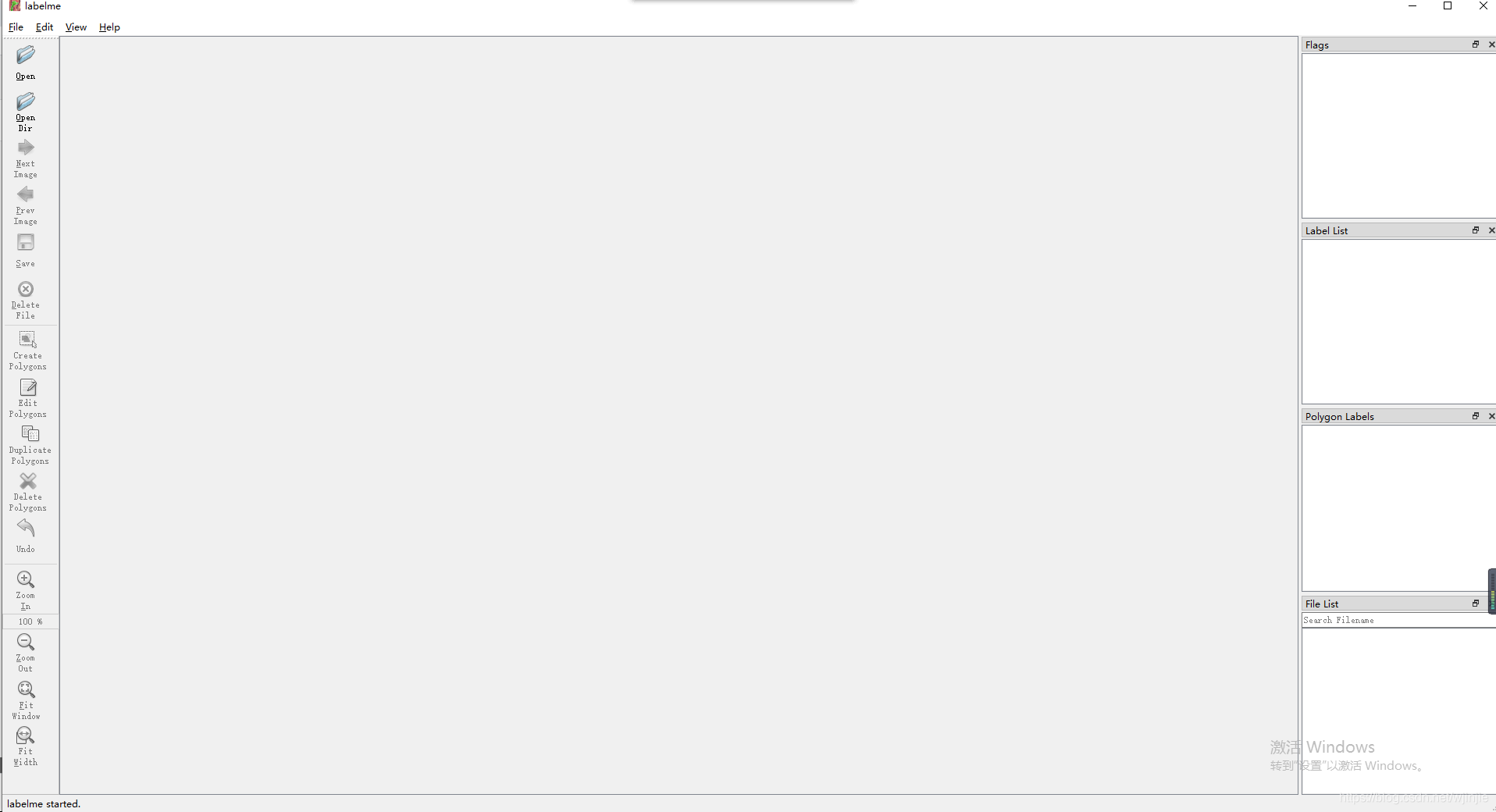

(2)标注数据集
第一步,点击open。打开你准备好的数据集,选中第一张图片打开。比如下面我打开的图片是302.jpg

第二步,点击 create polygons 开始描点。描点一定要细致,要将目标(这里是物堆)刚好框住。就像下面这样:

锚点完成后,会自动跳出下图页面让你标注类别。这里因为我只需要判断出物堆的区域,所以类别直接命名为1即可。
然后点击保存,就得到了对应的json文件。如下图所示:

(3)生成 png 图片标签
在开始菜单,再次找到 Anaconda Prompt 打开。注意第一次打开的 Anaconda Prompt 不要关。
第一步,先进入已经创建好的labelme环境:
conda activate labelme
第二步,cd 到刚才生成的json文件地址。比如我生成的302.json文件在:C:\Users\yibo_liu\Desktop\沙堆数据集\数据集test。那就cd 到该目录下:

第三步,运行如下代码:
labelme_json_to_dataset <文件名>.json
比如我要生成 302.json 的 png 标签文件,就像下面这样:

这一步完成后,就生成了302_json文件,我们最终需要的png标签就在这个文件夹里。

最后,打开302_json文件,需要将里面的 label.png 重命名为 302.png,这就是我们最终要的标签。
注意:标签图片名一定要和原图对应。

到这里就完成了一张图的标注过程。最终,需要将所有重命名后的png标签图片存有序地放在一个文件里。