附上另外两篇教程:
①yolov7进行数据增强及数据划分:链接
②yolov7裁剪出识别结果:链接
目录
1.安装Anaconda
下载Anaconda3,考虑到下载速度,可以去清华镜像下载,下载地址:清华镜像站
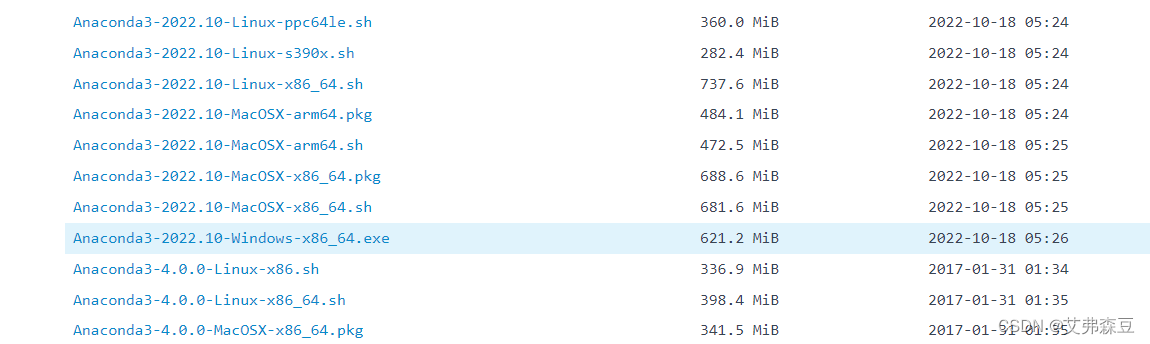
这里我下的是Anaconda3-2022.10-Windows-x86_64.exe
具体安装流程可以看这篇:https://blog.csdn.net/in546/article/details/117400839
2.创建python虚拟环境
打开刚下好的Anaconda Prompt(Anaconda3)
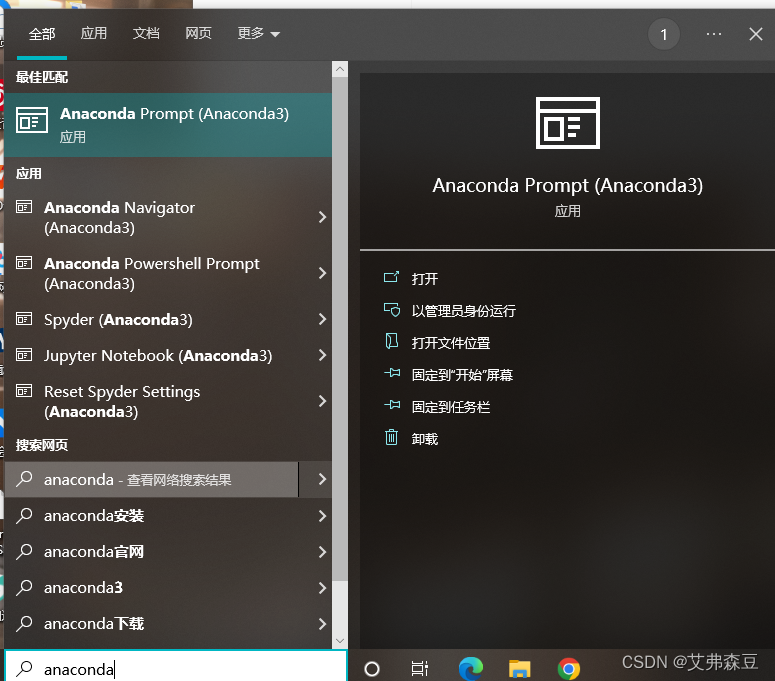
创建名为yolov7try,使用python3.8的虚拟环境:
conda create -n yolov7try python=3.8
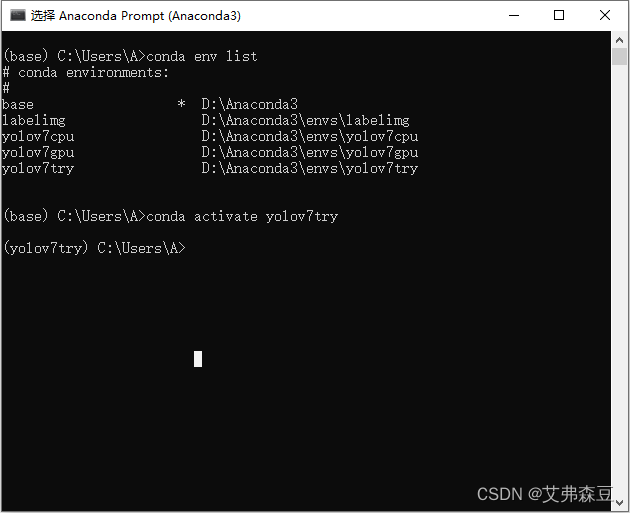
新建完后,查看所创建的环境:
conda env list
激活环境:
conda activate yolov7try
3.安装CUDA11.3
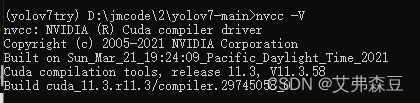
首先在Anaconda Prompt中查看一下现在已经安装的CUDA版本
nvcc -V
如果是其他版本,那就下载对应版本的pytorch与pytorchvision,这里我是用的CUDA11.3

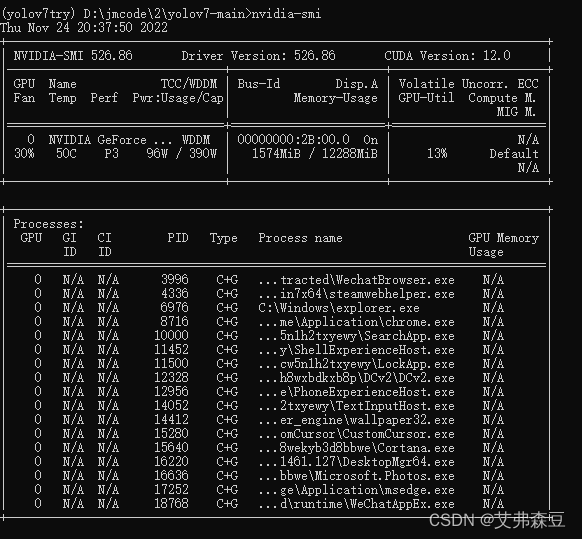
右上角查看CUDA驱动版本,小于等于它的都可以安装。
nvidia-smi
CUDA下载地址:CUDA下载地址
点击下载,安装教程:https://blog.csdn.net/Zinnir/article/details/122766367
安装成功后输入nvcc -V查看:
4.配置Yolov7环境
yolov7源码下载地址:yolov7
顺便把权重也下载了:

我用的是yolov7.pt,放在yolov7-main文件夹
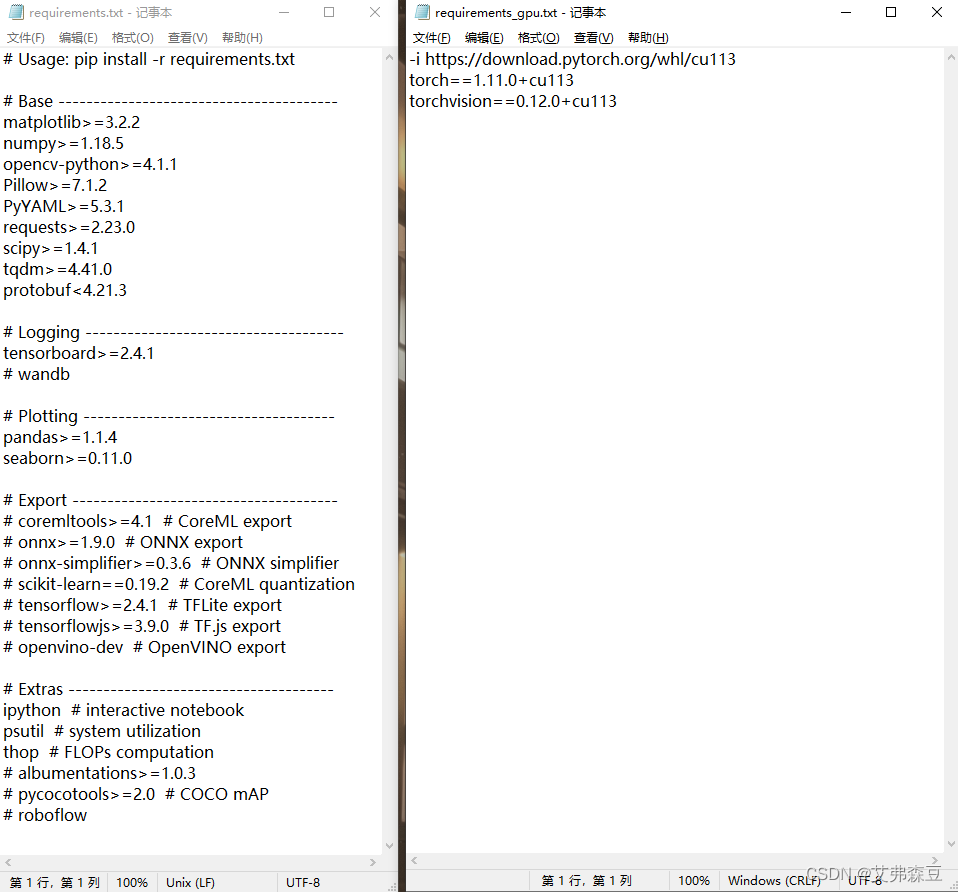
点开requirements.txt文件,把torch与torchvision这两行删除,新建一个requirements_gpu.txt文件:
-i https://download.pytorch.org/whl/cu113
torch1.11.0+cu113
torchvision0.12.0+cu113
然后在anaconda3中,cd到yolov7-main目录,输入下列命令:
pip install -r requirements.txt
pip install -r requirements_gpu.txt
如果速度过慢,可以参考这条配置清华源:https://blog.csdn.net/YPP0229/article/details/105630429/
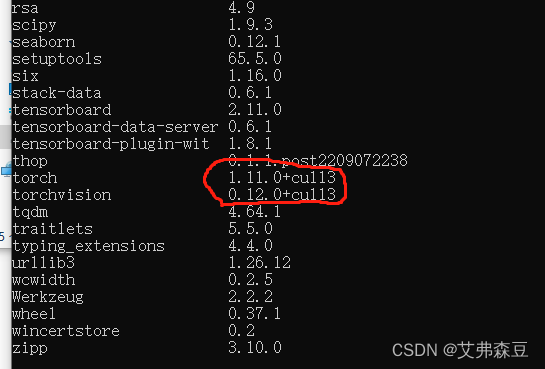
安装完后,pip list命令查看刚刚下载的库,显示这个就是安装成功了:
5.准备数据集
从roboflow下了一个行李数据集,下载地址:https://universe.roboflow.com/shudarshan-kongkham/baggage-jowci,我把它整合成yolov7支持的格式,如下:
百度网盘:链接
提取码:vuj9
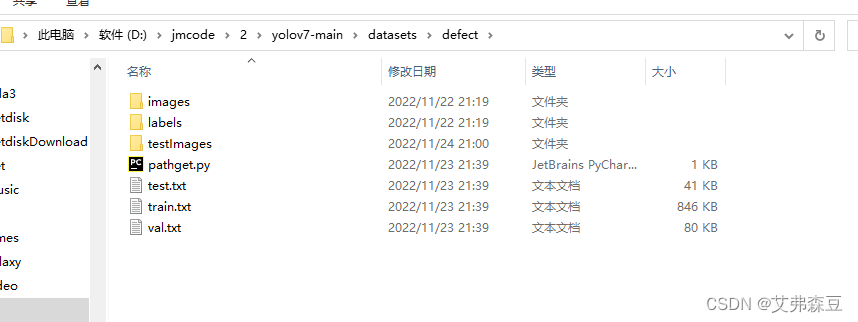
但是需要根据自己的图片路径修改下面这三个txt文件,打开pathget.py
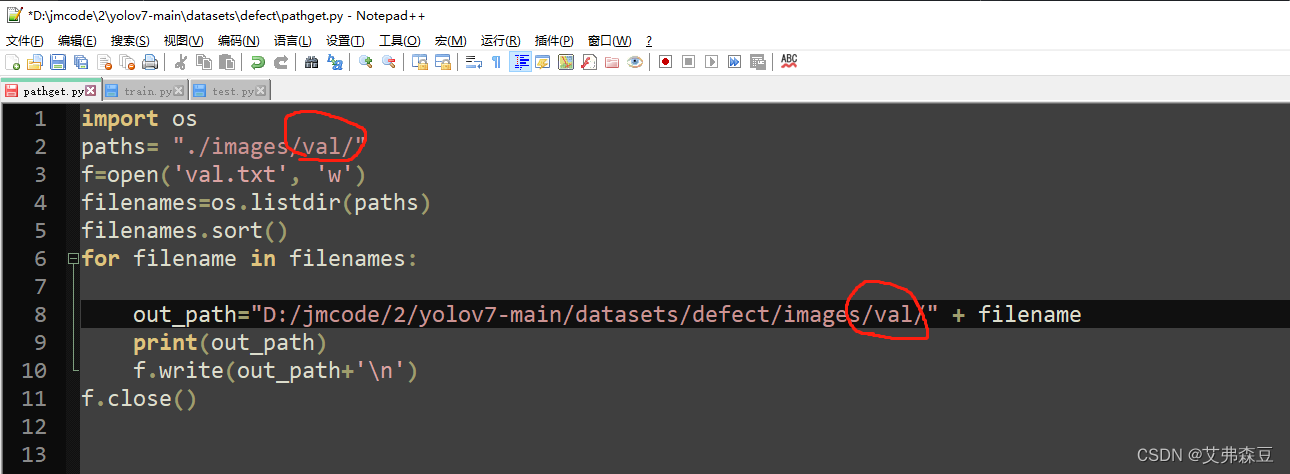
这里需要依次修改成test、train、val,运行三次,生成三个txt文件。
不过看到这里有人说了,怎么标记自己的数据集,下面开始讲
6.labelimg标记自己的数据集
在anaconda prompt中新建一个labelimg的环境
conda create -n labelimg python=3.6
新建完后,输入以下命令:
pip install labelimg -i https://pypi.tuna.tsinghua.edu.cn/simple
安装完后输入labelimg等待出现labelimg界面,这样就安装成功了
如何使用:https://blog.csdn.net/klaus_x/article/details/106854136
右侧切换YOLO模式,生成txt格式的标记文件。
接下来进行训练集、验证集与测试集图片划分,把所有图片放到images文件夹,把标签放到labels文件夹,运行代码如下。
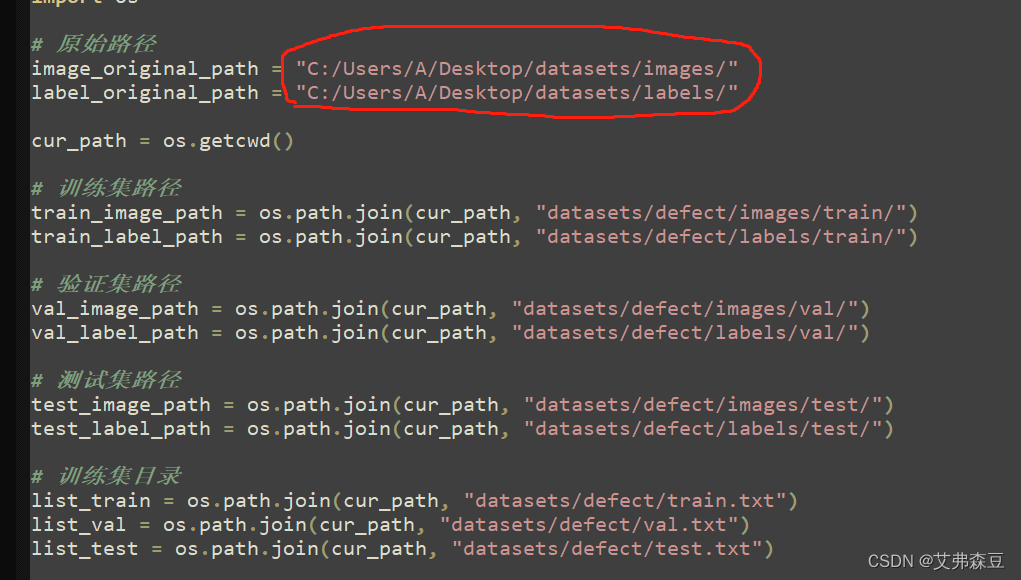
这里需要修改成自己的路径,下面的是生成划分好的数据集与.txt文件,这里的defect是我的一个缺陷数据集。
# 将图片和标注数据按比例切分为 训练集和测试集
import shutil
import random
import os
# 原始路径
image_original_path = "C:/Users/A/Desktop/datasets/images/"
label_original_path = "C:/Users/A/Desktop/datasets/labels/"
cur_path = os.getcwd()
# 训练集路径
train_image_path = os.path.join(cur_path, "datasets/defect/images/train/")
train_label_path = os.path.join(cur_path, "datasets/defect/labels/train/")
# 验证集路径
val_image_path = os.path.join(cur_path, "datasets/defect/images/val/")
val_label_path = os.path.join(cur_path, "datasets/defect/labels/val/")
# 测试集路径
test_image_path = os.path.join(cur_path, "datasets/defect/images/test/")
test_label_path = os.path.join(cur_path, "datasets/defect/labels/test/")
# 训练集目录
list_train = os.path.join(cur_path, "datasets/defect/train.txt")
list_val = os.path.join(cur_path, "datasets/defect/val.txt")
list_test = os.path.join(cur_path, "datasets/defect/test.txt")
train_percent = 0.6
val_percent = 0.2
test_percent = 0.2
def del_file(path):
for i in os.listdir(path):
file_data = path + "\\" + i
os.remove(file_data)
def mkdir():
if not os.path.exists(train_image_path):
os.makedirs(train_image_path)
else:
del_file(train_image_path)
if not os.path.exists(train_label_path):
os.makedirs(train_label_path)
else:
del_file(train_label_path)
if not os.path.exists(val_image_path):
os.makedirs(val_image_path)
else:
del_file(val_image_path)
if not os.path.exists(val_label_path):
os.makedirs(val_label_path)
else:
del_file(val_label_path)
if not os.path.exists(test_image_path):
os.makedirs(test_image_path)
else:
del_file(test_image_path)
if not os.path.exists(test_label_path):
os.makedirs(test_label_path)
else:
del_file(test_label_path)
def clearfile():
if os.path.exists(list_train):
os.remove(list_train)
if os.path.exists(list_val):
os.remove(list_val)
if os.path.exists(list_test):
os.remove(list_test)
def main():
mkdir()
clearfile()
file_train = open(list_train, 'w')
file_val = open(list_val, 'w')
file_test = open(list_test, 'w')
total_txt = os.listdir(label_original_path)
num_txt = len(total_txt)
list_all_txt = range(num_txt)
num_train = int(num_txt * train_percent)
num_val = int(num_txt * val_percent)
num_test = num_txt - num_train - num_val
train = random.sample(list_all_txt, num_train)
# train从list_all_txt取出num_train个元素
# 所以list_all_txt列表只剩下了这些元素
val_test = [i for i in list_all_txt if not i in train]
# 再从val_test取出num_val个元素,val_test剩下的元素就是test
val = random.sample(val_test, num_val)
print("训练集数目:{}, 验证集数目:{}, 测试集数目:{}".format(len(train), len(val), len(val_test) - len(val)))
for i in list_all_txt:
name = total_txt[i][:-4]
srcImage = image_original_path + name + '.jpg'
srcLabel = label_original_path + name + ".txt"
if i in train:
dst_train_Image = train_image_path + name + '.jpg'
dst_train_Label = train_label_path + name + '.txt'
shutil.copyfile(srcImage, dst_train_Image)
shutil.copyfile(srcLabel, dst_train_Label)
file_train.write(dst_train_Image + '\n')
elif i in val:
dst_val_Image = val_image_path + name + '.jpg'
dst_val_Label = val_label_path + name + '.txt'
shutil.copyfile(srcImage, dst_val_Image)
shutil.copyfile(srcLabel, dst_val_Label)
file_val.write(dst_val_Image + '\n')
else:
dst_test_Image = test_image_path + name + '.jpg'
dst_test_Label = test_label_path + name + '.txt'
shutil.copyfile(srcImage, dst_test_Image)
shutil.copyfile(srcLabel, dst_test_Label)
file_test.write(dst_test_Image + '\n')
file_train.close()
file_val.close()
file_test.close()
if __name__ == "__main__":
main()
最后将datasets文件夹放在yolov7-main中
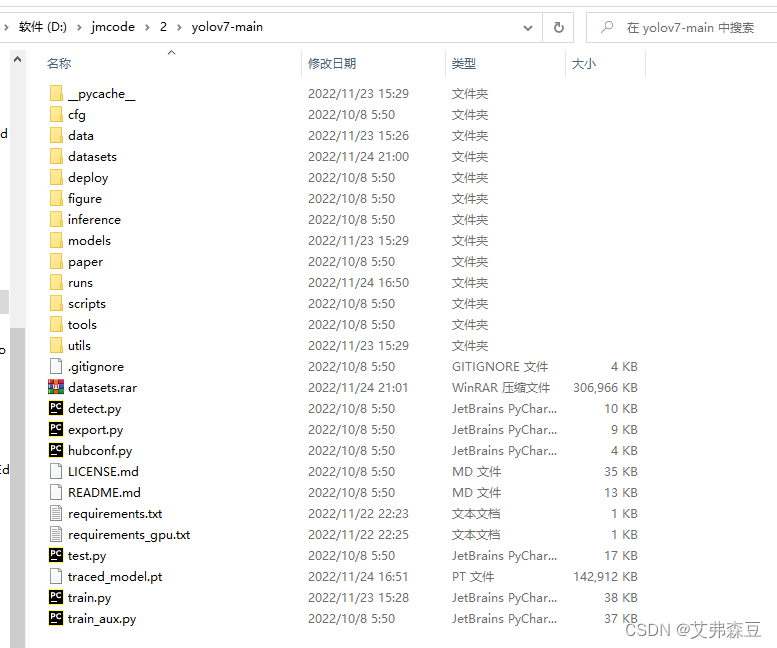
7.一些文件的修改
接着以行李箱识别为例,修改如下文件:
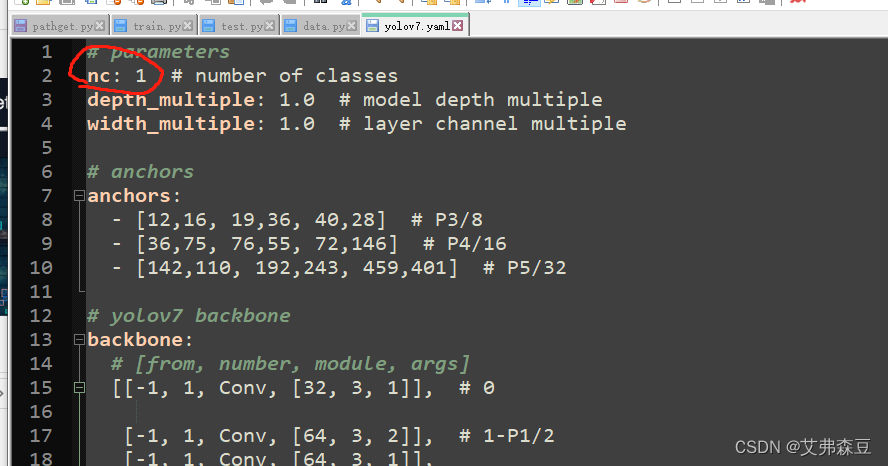
cfg\training中的yolov7.yaml,种类是多少就改成多少
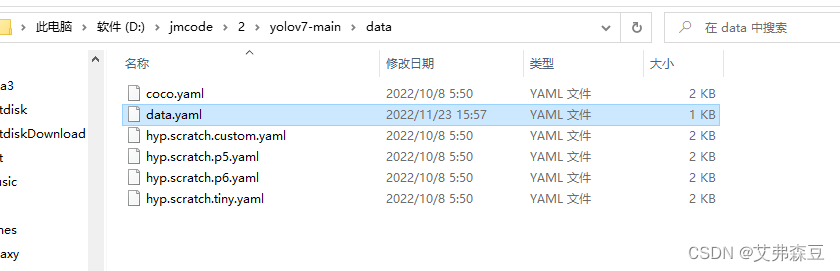
在data文件中新建一个data.yaml,修改成刚刚数据集的路径
# train and val data as 1) directory: path\images\, 2) file: path\images.txt, or 3) list: [path1\images\, path2\images\]
train: D:\jmcode\2\yolov7-main\datasets\defect\train.txt
val: D:\jmcode\2\yolov7-main\datasets\defect\val.txt
test: D:\jmcode\2\yolov7-main\datasets\defect\test.txt
# number of classes
nc: 1
# class names
names: ['baggage']
8.训练与测试
接下来就可以开始训练了
cd到yolov7-main文件夹,输入以下命令开始训练:
我这里设置的batchsize是16,epoch是100
python train.py --workers 0 --device 0 --batch-size 16 --data data/data.yaml --img-size 320 320 --cfg cfg/training/yolov7.yaml --weights 'yolov7.pt' --name yolov7 --hyp data/hyp.scratch.p5.yaml --epochs 100
添加–cache-images加快训练速度
python train.py --workers 0 --device 0 --batch-size 16 --data data/data.yaml --img-size 320 320 --cfg cfg/training/yolov7.yaml --weights 'yolov7.pt' --name yolov7 --hyp data/hyp.scratch.p5.yaml --epochs 100 --cache-images
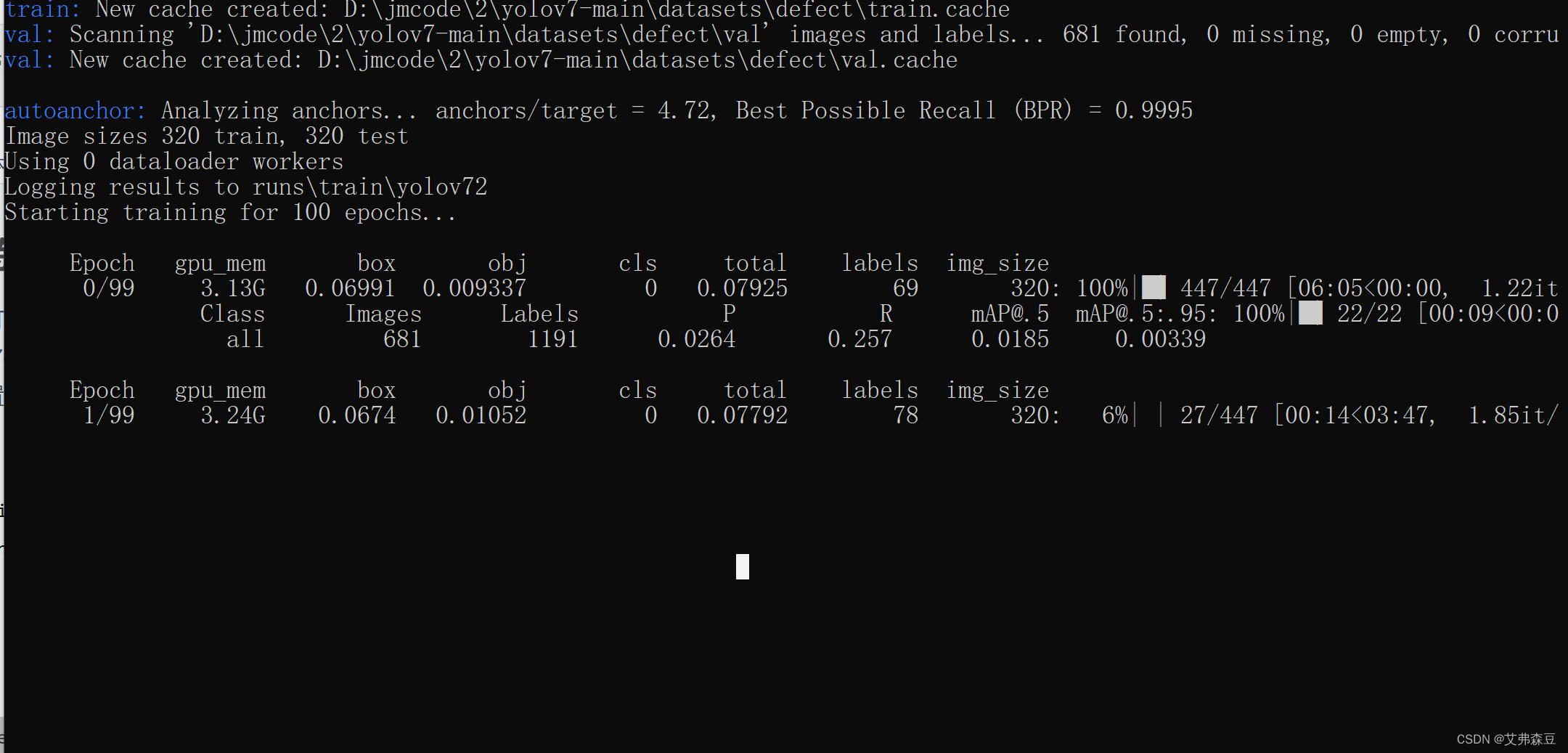
就可以慢慢等待训练了,训练好后,测试一下:
python detect.py --weights .\runs\train\yolov7\weights\best.pt --source .\datasets\defect\testImages\
