1 如何表示图像?
直接利用原始像素作为特征,展开为列向量。
2 全连接神经网络
全连接神经网路级联多个变换来实现输入到输出的映射。
注:非线性操作是不可以去掉
2.1 两层全连接神经网络
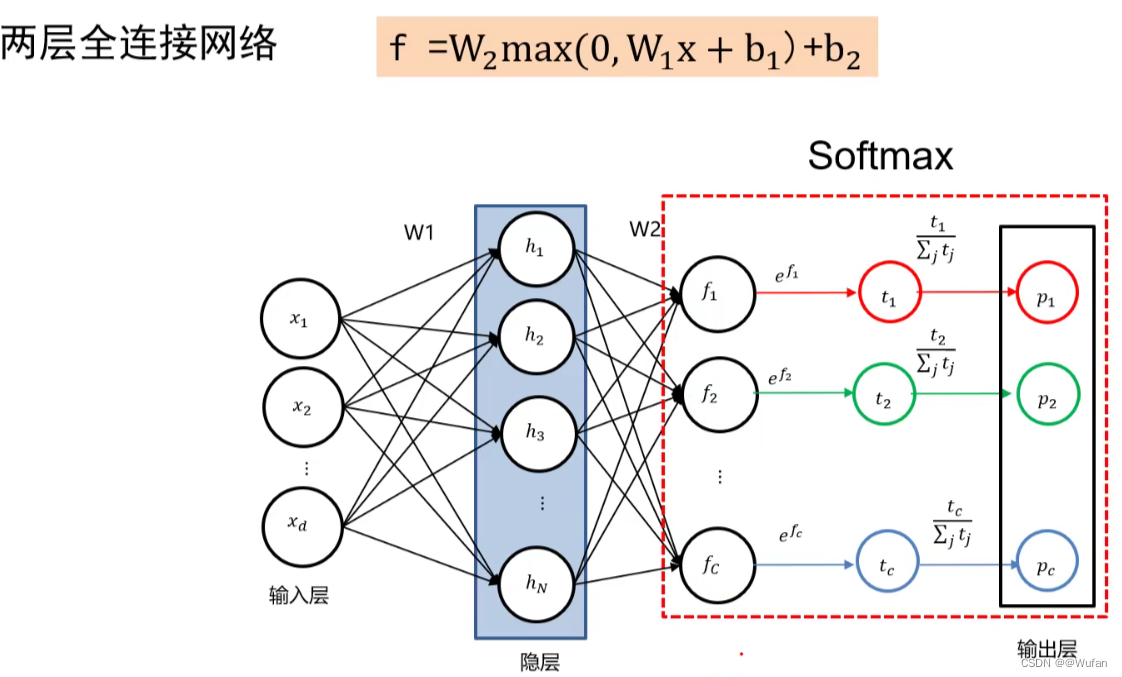
f = W 2 _{2} 2max(0,W 1 _{1} 1x+ b 1 _{1} 1) + b 2 _{2} 2
- W 1 _{1} 1也可看做模板;模板个数人为指定
- W 2 _{2} 2融合这多个模板的匹配结果来实现最终类别打分
2.2 三层全连接神经网路
f = W 3 _{3} 3max(0,W 2 _{2} 2max(0,W 1 _{1} 1x+ b 1 _{1} 1) + b 2 _{2} 2) + b 3 _{3} 3
2.3 激活函数
如上举例的3层神经网络,其中 max()是激活函数。
若去掉激活函数:f = W 3 _{3} 3 ( W 2 ( w 1 x + b 1 ) + b 2 ) + b 3 (W_{2}(w_{1}x + b_{1})+b_{2}) + b_{3} (W2(w1x+b1)+b2)+b3
\qquad\qquad\qquad =W 3 _{3} 3W 2 _{2} 2W 1 _{1} 1x + (W 3 _{3} 3W 2 _{2} 2b 1 _{1} 1+W 3 _{3} 3b 2 _{2} 2+b 3 _{3} 3)
\qquad\qquad\qquad =W ′ ^{'} ′x + b ′ ^{'} ′
则全连接神经网络将变成一个线性分类器
2.3.1 常用的激活函数
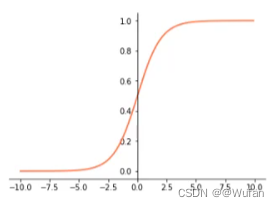
- Sigmoid: 1 1 + e − x \frac{1}{1+e^{-x}} 1+e−x1
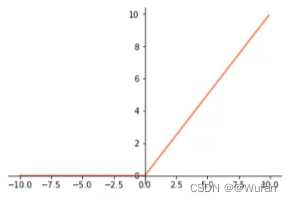
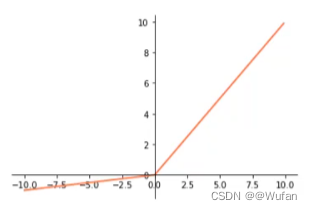
- ReLU:max(0,x)
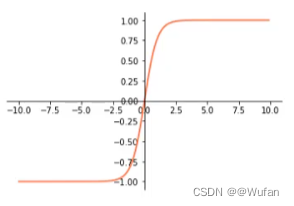
- tanh: e x − e − x e x + e − x \frac{e^{x}-e^{-x}}{e^{x}+e^{-x}} ex+e−xex−e−x
- Leaky ReLU:max(0.1x,x)
2.4 网络结构设计
- 用不用隐层,用一个还是用几个隐层?(深度设计)
- 每隐层设置多少个神经元比较合适?(宽度设计)
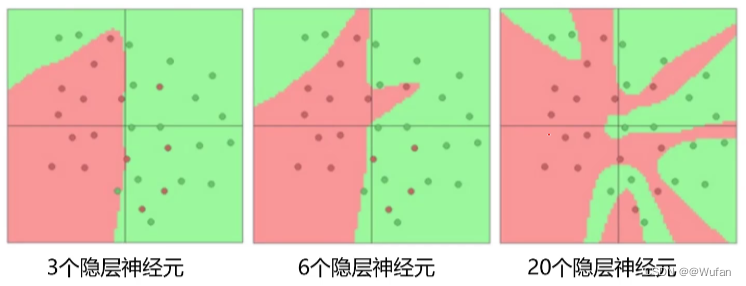
结论:神经元个数越多,分界面就可以越复杂,在这个集合上的分类能力就越强。
2.5 全连接神经网络小结
- 全连接神经网络组成:一个输入层、一个输出层及多个隐层;
- 输入层与输出层的神经元个数由任务决定,而隐层数量以及每个隐层的神经元个数需要人为指定;
- 激活函数是全连接神经网络中的一个重要部分,缺少了激活函数,全连接神经网络将退化为线性分类器。
3 SOFTMAX
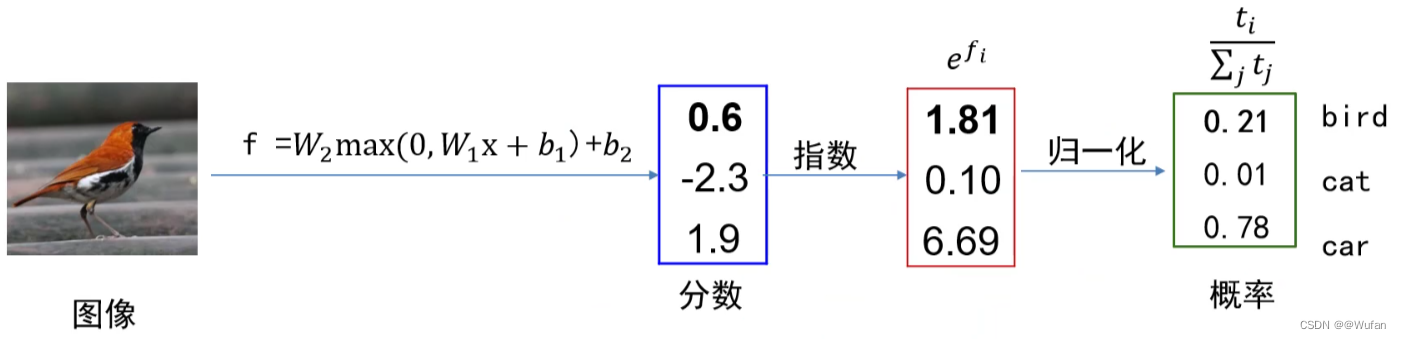
经过Softmax层,所得到的结果是具有概率性质的,其中p 1 _{1} 1+p 2 _{2} 2+…+p c _{c} c = 1
示例:
4 交叉熵损失

4.1 交叉熵-度量分类器输出与预测值之间的距离
- 熵:H( p )= - ∑ x \sum_{x} ∑xp(x)logp(x)
- 交叉熵:H(p,q) = - ∑ x \sum_{x} ∑xp(x)logq(x)
- 相对熵:KL(P||Q) = - ∑ x \sum_{x} ∑xp(x)log q ( x ) p ( x ) \frac{q(x)}{p(x)} p(x)q(x)
相对熵(relative entropy)也叫KL散度(KL divergence);用来度量两个分布之间的不相似性(dissimilarity)。 - 三者之间的关系
H(p,q) = - ∑ x \sum_{x} ∑xp(x)logq(x)
\qquad =- ∑ x \sum_{x} ∑xp(x)logp(x)- ∑ x \sum_{x} ∑xp(x)log q ( x ) p ( x ) \frac{q(x)}{p(x)} p(x)q(x)
\qquad =H( p )+KL(p||q)
5 交叉熵损失 vs 多类支撑向量机损失
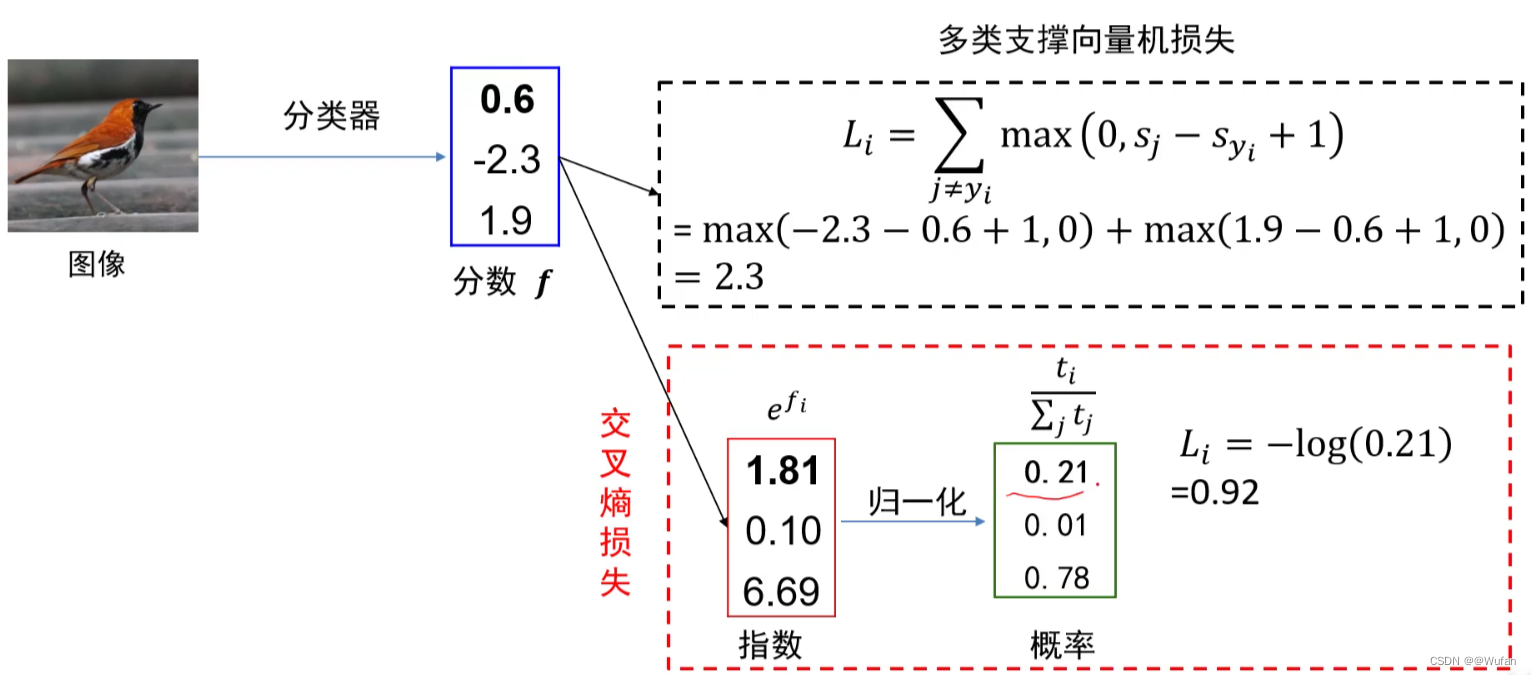
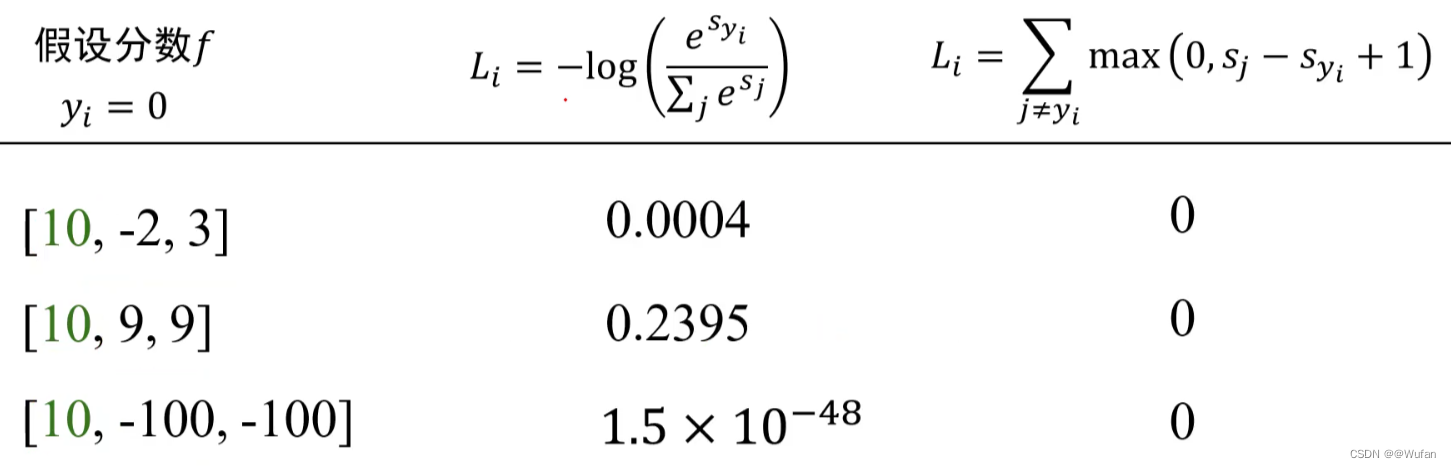
6 什么是计算图
计算图是一种有向图,它用来表达输入、输出以及中间变量之间的计算关系,图中的每个节点对应着一种数学运算。
6.1 计算图与反向传播算法
-
函数 f = ( x + y ) 2 ^{2} 2的计算图
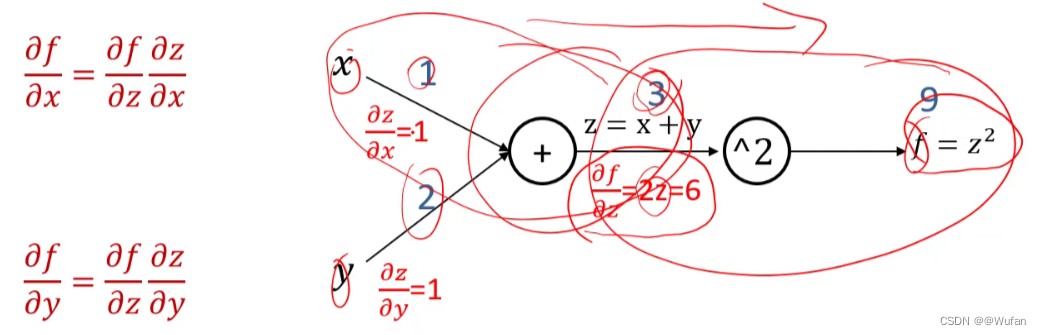
-
反向传播示例
f(w,x) = 1 1 + e − ( w 0 x 0 + w 1 x 1 + w 2 ) \frac{1}{1+e-^(w_{0}x_{0}+w_{1}x_{1}+w_{2})} 1+e−(w0x0+w1x1+w2)1
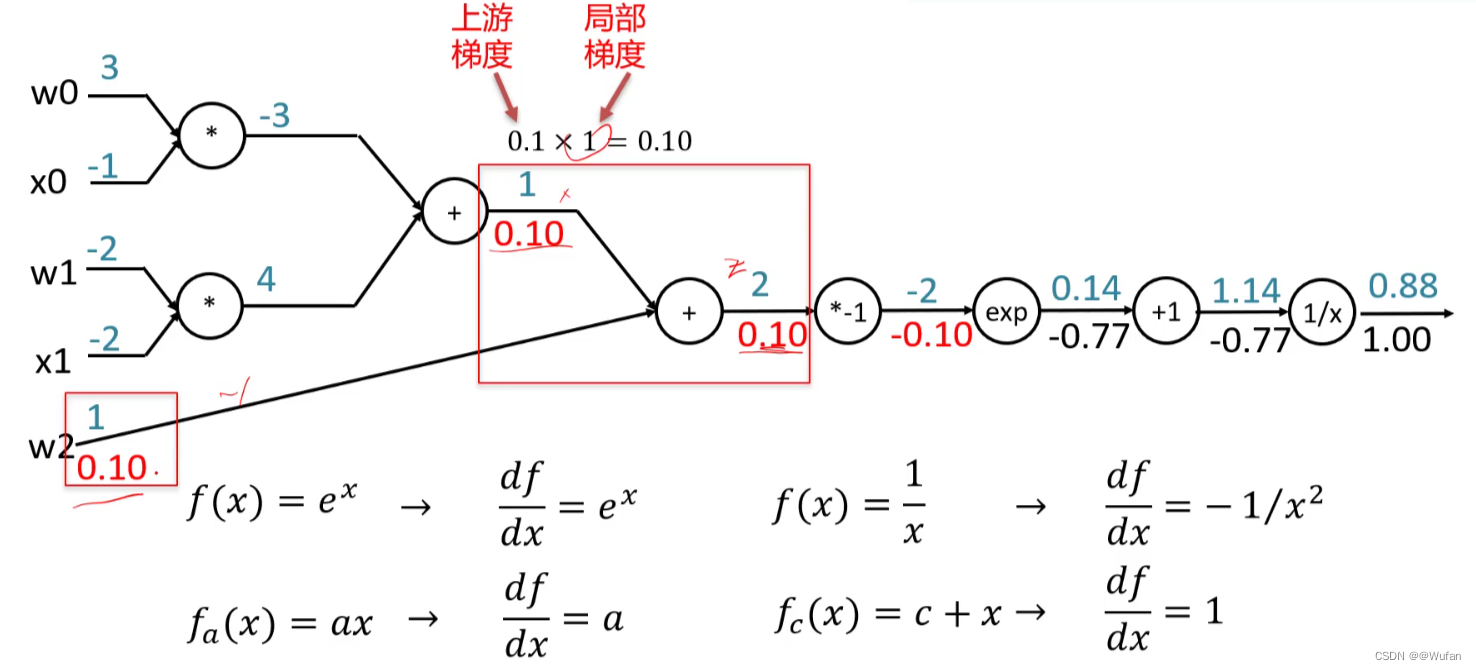
6.3 计算图中常见的门单元
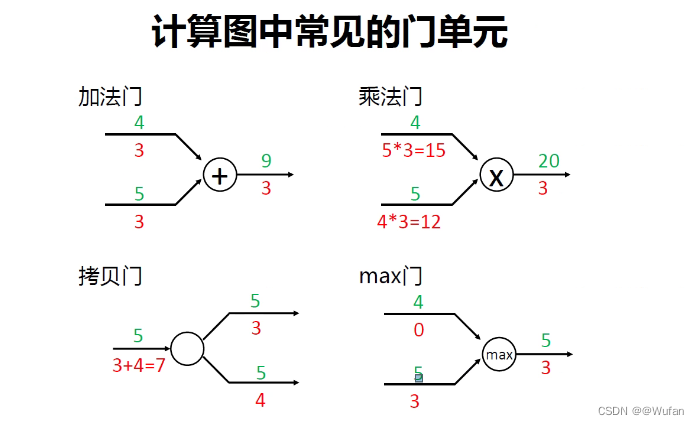
6.3 计算图总结
- 任意复杂的函数,都可以用计算图的形式表示
- 在整个计算图中,每个门单元都会得到一些输入,然后,进行下面两个计算:
1)这个门的输出值
2)其输出值关于输入值的局部梯度。 - 利用链式法则,门单元应该将回传的梯度乘以它对其的输入的局部梯度,从而得到整个网络的输出对该门单元的每个输入值的梯度。