1 过拟合现象
- 出现过拟合,得到的模型在训练集上的准确率很高,但在真实的场景中识别率确很低。
- 过拟合:学习时选择的模型所包含的参数过多,以至于出现这一模型对已知数据预测的很好,但对未知数据预测得很差的现象。这种情况下模型可能只是记住了训练集数据,而不是学习到了数据特征。
- 欠拟合:模型描述能力太弱,以至于不能很好地学习到数据中的规律。产生欠拟合的原因通常是模型过于简单。
1.1 学习过程中的过拟合
- 机器学习的根本问题时优化和泛化的问题。
- 优化:是指调节模型以在训练数据上得到最佳性能。
- 泛化:是指训练好的模型在前所未见的数据上的性能好坏。
- 训练初期:优化和泛化是相关的(训练集上的误差越小,验证集上的误差也越小,模型的泛化能力逐渐增强)
- 训练后期: 模型在验证集上的错误率不再降低,转而开始变高。模型出现过拟合,开始学习仅和训练数据有关的模式。
1.2 应对过拟合
- 最优方案:获取更多的训练数据
- 次优方案:调节模型允许存储的信息量或者对模型允许存储的信息加以约束,该类方法也称为正则化。
- 调节模型大小
- 约束模型权重,即权重正则化(常用的有L1、L2正则化)
- 随机失活(Dropout)
1.2.1 L2正则化
L(W) = 1 N ∑ i L i ( f ( x i , W ) , y i ) ⏟ 数据损失 \underbrace{\frac{1}{N}\sum\limits_{i}L_{i}(f(x_{i},W),y_{i})}_{数据损失} 数据损失 N1i∑Li(f(xi,W),yi)+ λ \lambda λ R ( W ) ⏟ 权重正则损失 \underbrace{R(W)}_{权重正则损失} 权重正则损失 R(W)
L2正则损失:R(W) = ∑ k \sum\limits_{k} k∑ ∑ l \sum\limits_{l} l∑W k , l 2 _{k,l}^{2} k,l2
L2正则损失对于大数值的权值向量进行严厉惩罚,鼓励更加分散的权重向量,使模型倾向于使用所有输入特征做决策,此时的模型泛化性能好!
1.2.2 随机失活(Dropout)
- 随机失活:让隐层的神经元以一定的概率不被激活。
- 实现方式:训练过程中,对某一层使用Dropout,就是随机将该层的一些输出舍弃(输出值设置为0),这些被舍弃的神经元就好像被网格删除了一样。
- 随机失活比率(Dropout ratio):是被设为0的特征所占的比例,通常在0.2~0.5范围内
例:假设某一层对给定输入的样本返回值应该是向量:[0.2,0.5,1.3,0.8,1.1]。
使用Dropout后,这个向量会有几个随机的元素变成:[0,0.5,1.3,0,1.1]。
1.2.3 随机失活为什么能防止过拟合
- 随机失活使得每次更新梯度时参与计算的网络参数减少了,降低了模型容量,所以能防止过拟合。
- 随机失活鼓励权重分散,从这个角度来看随机失活也能起到正则化的作用,进而防止过拟合。
- Dropout可以看作模型集成
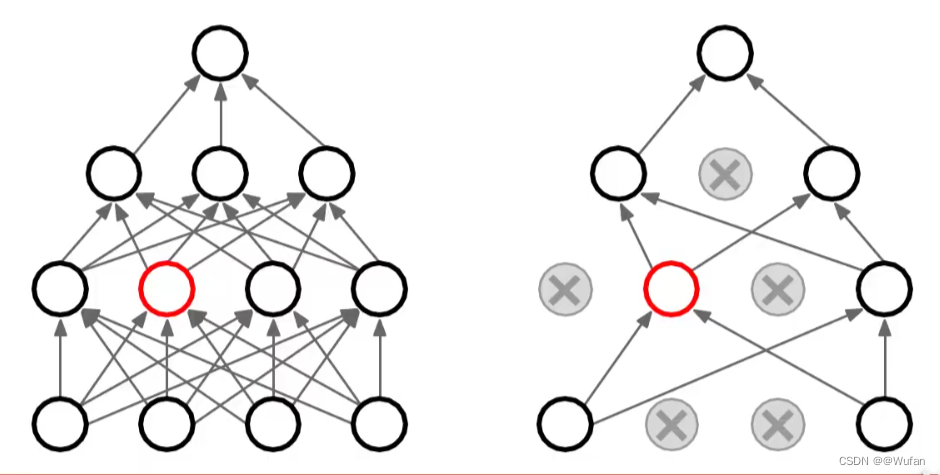
1.2.4 随机失活的应用

三层神经网络示例:
p = 0.5
def train(X):
H1 = np.maximum(0,np.dot(W1,X) + b1)
U1 = np.random.rand(*H1.shape) < p
H1 *= U1
H2 = np.maximum(0,np.dot(W2,H1) + b2)
U2 = np.random.rand(*H2.shape) < p
H2 *= U2
out = np.dot(W3,H2) + b3
def predict(X):
H1 = np.maximum(0,np.dot(W1,X) + b1) * P
H2 = np.maximum(0,np.dot(W2,H1) + b2) * P
out = np.dot(W3,H2) + b3
2 神经网络中的超参数
- 超参数:在模型设计阶段就指定的
- 网络结构:隐层神经元个数,网络层数,非线性单元选择等
- 优化相关:学习率、dropout比率、正则项强度等
2.1 学习率设置
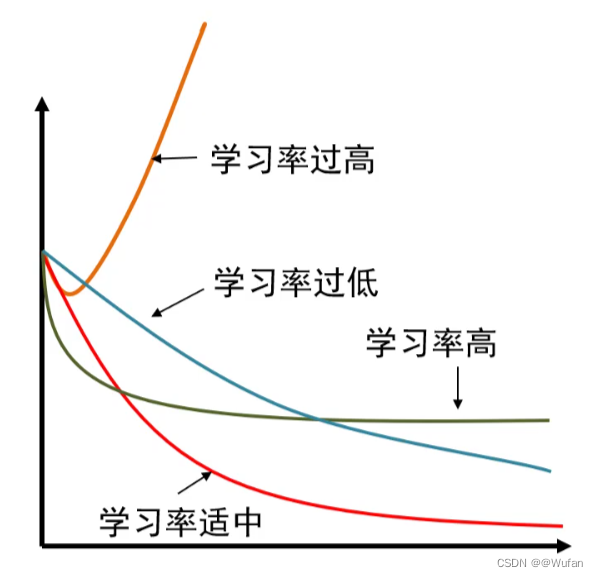
- 学习率过大,训练过程无法收敛
- 学习率偏大,在最小值附近震荡,达不到最优
- 学习率太小,收敛时间较长
- 学习率适中,收敛快、结果好
2.2 超参数优化方法
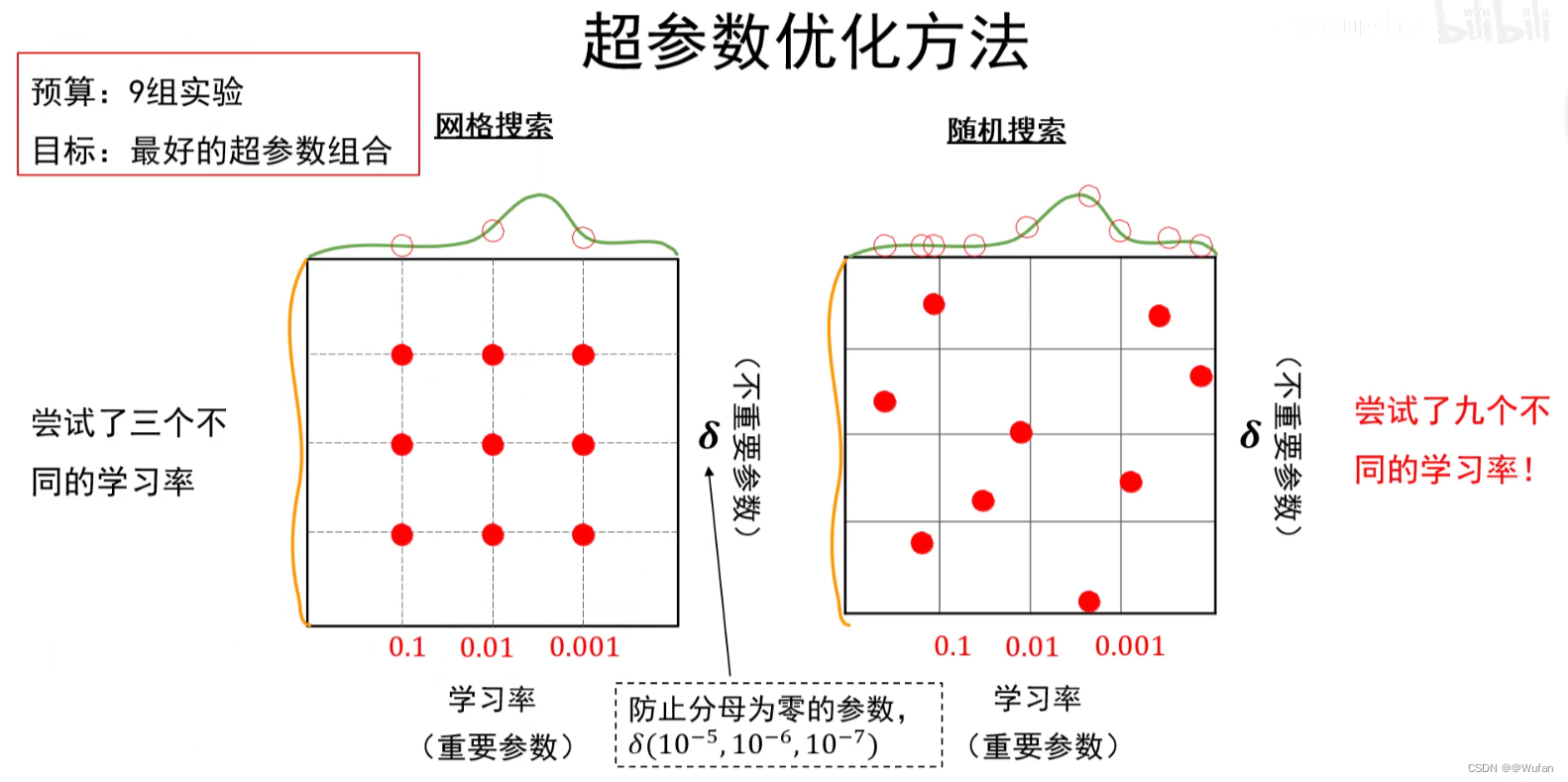
网格搜索法:
①每个超参数分别取几个值,组合这些超参数值,形成多组超参数;
②在验证集上评估每组超参数的模型性能;
③选择性能最优的模型所采用的那组值作为最终的超参数的值。
随机搜索法:
①参数空间内随机取点,每个点对应一组超参数;
②在验证集上评估每组超参数的模型性能;
③选择性能最优的模型所采用的那组值作为最终的超参数的值。
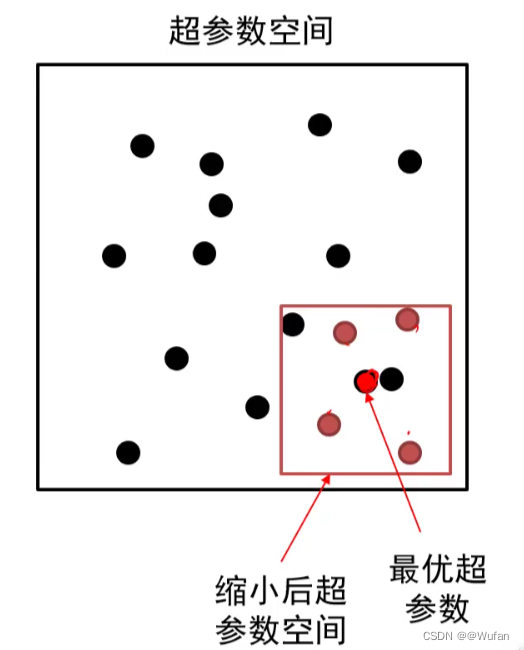
2.3 超参数搜索策略
- 粗搜索:利用随机法在较大范围里采样超参数,训练一个周期,依据验证集正确率缩小超参数范围。
- 精搜索:利用随机法在前述缩小的范围内采样超参数,运行模型五到十个周期,选择验证集上精度最高的那组超参数。
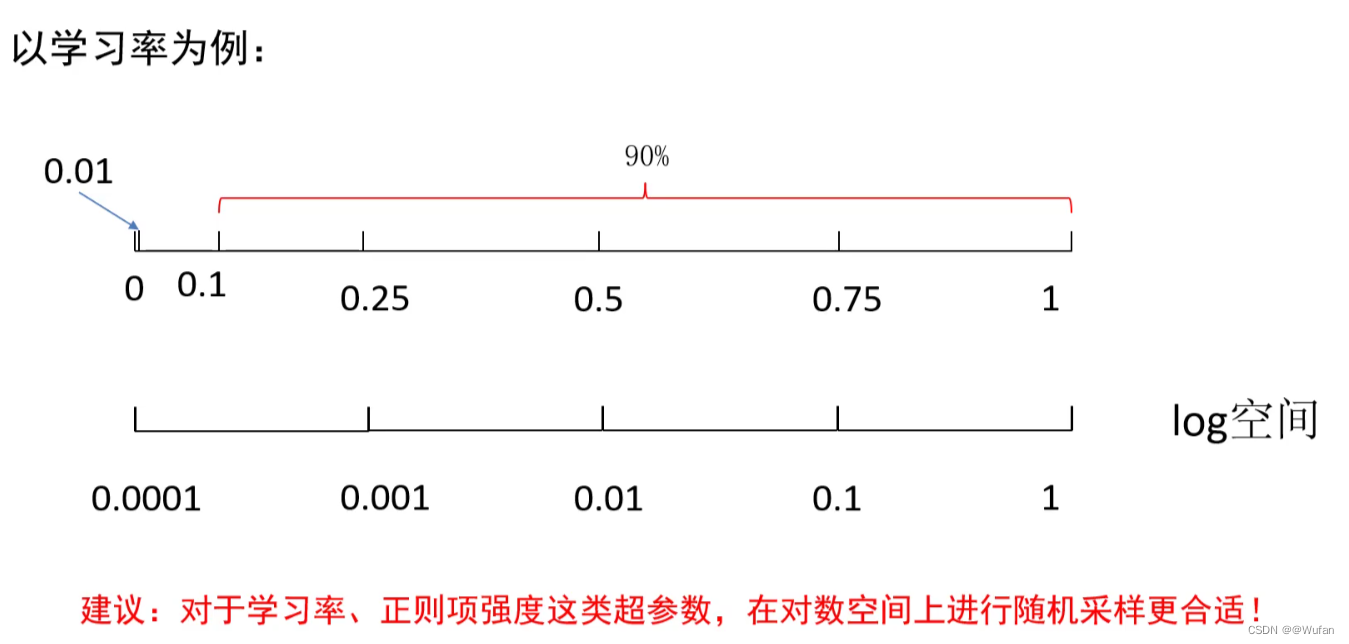
2.4 超参数的标尺空间