版权声明:本文为博主原创文章,未经博主允许不得转载。 https://blog.csdn.net/zhangcheng_95/article/details/81260685
深度学习二:使用TensorFlow搭建简单的全连接神经网络
学习《TensorFlow实战Google深度学习框架》一书
在前一篇博客中,学习了使用python搭建简单的全连接神经网络
这里继续学习使用TensorFlow来搭建全连接神经网络。文章结束后依旧会贴上全部代码
实验环境:Python+TensorFlow+Pycharm
实验依旧采用随机生成的数据集,用随机生成的x来拟合随机生成的y
首先是引入并生成随机数据:
import tensorflow as tf
from numpy.random import RandomState
import matplotlib.pyplot as plt
# 随机生成数据集,并自定义标签
rdm = RandomState(1)
dataset_size = 128 # 数据集大小
X = rdm.rand(dataset_size, 2)
Y = [[int(x1+x2 < 1)] for (x1, x2) in X] # 生成标签生成的输入X维度为(128,2),标签Y的维度为(128,1),可以认为输入为产品两个属性值x1和x2,如果x1+x2<1则被认为是合格产品,标签为Y为1,否则标签Y为0。
定义输入输出:
# 定义输入和标签(真实值)
x = tf.placeholder("float32", [None, 2])
y_ = tf.placeholder("float32", [None, 1])这里的x和y_用来接收输入的X和Y
设置神经网络的参数:
# 权重
W1 = tf.Variable(tf.random_normal([2, 3], stddev=1, seed=1))
W2 = tf.Variable(tf.random_normal([3, 1], stddev=1, seed=1))
# 偏置
b1 = tf.Variable(tf.zeros([3]))
b2 = tf.Variable(tf.zeros([1]))这里定义的是但隐层神经网络,w1和b1是隐藏层的权重和偏置,w2和b2是输出层的权重和偏置。设计隐藏层有3个隐藏节点,所以,w1的维度为(2,3)。Tenorflow提供了多种随机数生成的函数,这里使用tf.r的andom_normal()生成服从正态分布的随机数,tf.zeros则生成全0数组。
神经网络的前向传播输出:
# 输出
a1 = tf.nn.relu(tf.matmul(x, W1)+b1)
y = tf.nn.relu(tf.matmul(a1, W2)+b2)tf.nn.relu()函数提供了ReLu激活函数的实现,tf.matmul则实现了矩阵的乘法。可以看到,a1为隐藏层的输出,y为输出层的输出。
定义网络的训练:
# 定义损失函数
# cross_entropy = -tf.reduce_sum(y_*tf.log(y)+(1-y_)*tf.log(1-y))
cross_entropy = -tf.reduce_mean(y_*tf.log(tf.clip_by_value(y, 1e-10, 1.0)))
# cross_entropy = - tf.reduce_mean(y_*tf.log(y))
# cross_entropy = - (tf.reduce_mean(y_*tf.log(y))+tf.contrib.layers.l2_regularizer(0.01)(W1)) #加入L2正则
# 学习率
learning_rate = 0.001
# 定义优化方法
# optimizer = tf.train.GradientDescentOptimizer(learning_rate)
optimizer = tf.train.AdamOptimizer(learning_rate)
train_step = optimizer.minimize(cross_entropy)TensorFlow提供了多种训练优化方法的实现,很方便。
开始训练网络:
init = tf.global_variables_initializer()
with tf.Session() as sess:
# 初始化参数
sess.run(init)
# 定义批量大小和迭代次数
batch_size = 9
step = 1000
# 开始训练
for i in range(step):
# 获取批量训练的数据
start = (i*batch_size) % dataset_size
end = min(start+batch_size, dataset_size)
# 输入数据训练
sess.run(train_step, feed_dict={x: X[start:end], y_: Y[start:end]})
if i % 10 == 0:
# 每10轮迭代获取一次损失函数的值
loss = sess.run(cross_entropy, feed_dict={x: X, y_: Y})
# 输出绘图
print(i, "epoch,loss:", loss)
plt.plot(i, loss, 'ro')
plt.show()相比之下,使用TensorFlow实现的神经网络更加便捷,很多步骤都不需要自己去逐步实现。
全部代码如下:
import tensorflow as tf
from numpy.random import RandomState
import matplotlib.pyplot as plt
# 随机生成数据集,并自定义标签
rdm = RandomState(1)
dataset_size = 128 # 数据集大小
X = rdm.rand(dataset_size, 2)
Y = [[int(x1+x2 < 1)] for (x1, x2) in X] # 生成标签
# 定义输入和标签(真实值)
x = tf.placeholder("float32", [None, 2])
y_ = tf.placeholder("float32", [None, 1])
# 权重
W1 = tf.Variable(tf.random_normal([2, 3], stddev=1, seed=1))
W2 = tf.Variable(tf.random_normal([3, 1], stddev=1, seed=1))
# 偏置
b1 = tf.Variable(tf.zeros([3]))
b2 = tf.Variable(tf.zeros([1]))
# 输出
a1 = tf.nn.relu(tf.matmul(x, W1)+b1)
y = tf.nn.relu(tf.matmul(a1, W2)+b2)
# 定义损失函数
# cross_entropy = -tf.reduce_sum(y_*tf.log(y)+(1-y_)*tf.log(1-y))
cross_entropy = -tf.reduce_mean(y_*tf.log(tf.clip_by_value(y, 1e-10, 1.0)))
# cross_entropy = - tf.reduce_mean(y_*tf.log(y))
# cross_entropy = - (tf.reduce_mean(y_*tf.log(y))+tf.contrib.layers.l2_regularizer(0.01)(W1)) #加入L2正则
# 学习率
learning_rate = 0.001
# 定义优化方法
# optimizer = tf.train.GradientDescentOptimizer(learning_rate)
optimizer = tf.train.AdamOptimizer(learning_rate)
train_step = optimizer.minimize(cross_entropy)
init = tf.global_variables_initializer()
with tf.Session() as sess:
# 初始化参数
sess.run(init)
# 定义批量大小和迭代次数
batch_size = 9
step = 1000
# 开始训练
for i in range(step):
# 获取批量训练的数据
start = (i*batch_size) % dataset_size
end = min(start+batch_size, dataset_size)
# 输入数据训练
sess.run(train_step, feed_dict={x: X[start:end], y_: Y[start:end]})
if i % 10 == 0:
# 每10轮迭代获取一次损失函数的值
loss = sess.run(cross_entropy, feed_dict={x: X, y_: Y})
# 输出绘图
print(i, "epoch,loss:", loss)
plt.plot(i, loss, 'ro')
plt.show()实验结果:

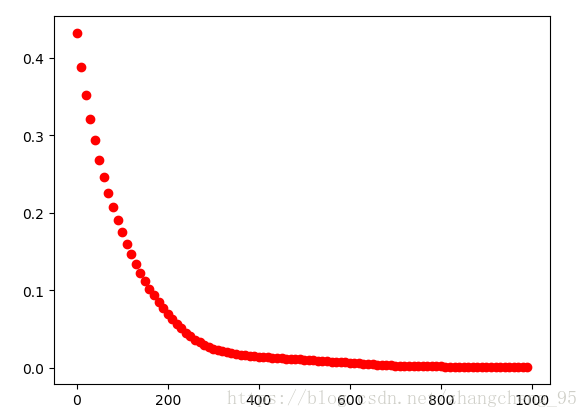
可以看到随着迭代次数的增加,损失函数是逐渐减小的。
改进版:用函数来实现参数的定义,并加入L2正则,代码如下:
import tensorflow as tf
from numpy.random import RandomState
import matplotlib.pyplot as plt
# 随机生成数据集,并自定义标签
rdm = RandomState(1)
dataset_size = 128
X = rdm.rand(dataset_size, 2)
Y = [[int(x1+x2 < 1)] for (x1, x2) in X]
def get_weight(shape, lambd):
# 生成一个变量
var = tf.Variable(tf.random_normal(shape), dtype= tf.float32)
# 将新生成变量的L2正则化损失加入集合
tf.add_to_collection('losses', tf.contrib.layers.l2_regularizer(lambd)(var))
return var
x = tf.placeholder(tf.float32, shape=[None, 2])
y_ = tf.placeholder(tf.float32, shape=[None, 1])
batch_size = 8
# 定义每一层网络中节点的个数
layer_dimension = [2, 10, 10, 1]
# 神经网络的层数
n_layers = len(layer_dimension)
# 维护前向传播时最深层的节点,开始的时候就是输入层
cur_layer = x
# 当前层的结点个数
in_dimension = layer_dimension[0]
for i in range(1, n_layers):
# 下一层的节点数
out_dimension = layer_dimension[i]
# 生成当前层中的权重和偏置,并加入L2正则
weight = get_weight([in_dimension, out_dimension], 0.001)
bias = tf.Variable(tf.constant(0.1, shape=[out_dimension]))
cur_layer = tf.nn.relu(tf.matmul(cur_layer, weight) + bias)
in_dimension = out_dimension
# 损失函数
mse_loss = tf.reduce_mean(tf.square(y_ - cur_layer))
tf.add_to_collection('losses', mse_loss)
loss = tf.add_n(tf.get_collection('losses'))
learning_rate = 0.001
optimizer = tf.train.AdamOptimizer(learning_rate)
train_step = optimizer.minimize(loss)
init = tf.global_variables_initializer()
with tf.Session() as sess:
sess.run(init)
for i in range(1000):
start = (i * batch_size) % dataset_size
end = min(start + batch_size, dataset_size)
sess.run(train_step, feed_dict={x: X[start:end], y_: Y[start:end]})
if i % 10 == 0:
l = sess.run(loss, feed_dict={x: X, y_: Y})
print(i, "epoch,loss:", l)
plt.plot(i, l, 'ro')
plt.show()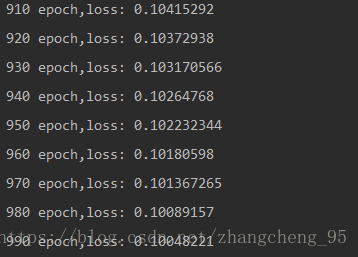
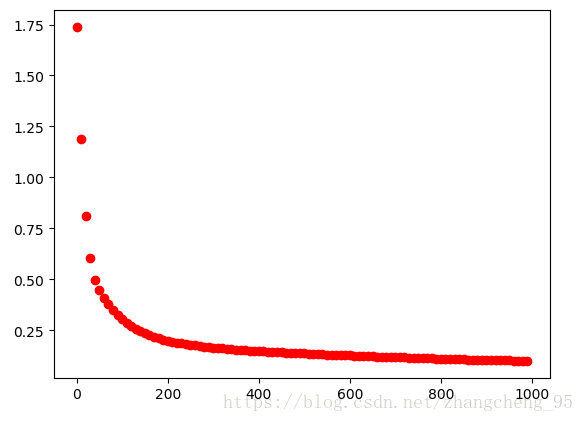
可以看到,由于加入了l2正则以避免过拟合,loss没有之前训练的那没小