1 纹理
1.1 纹理分类
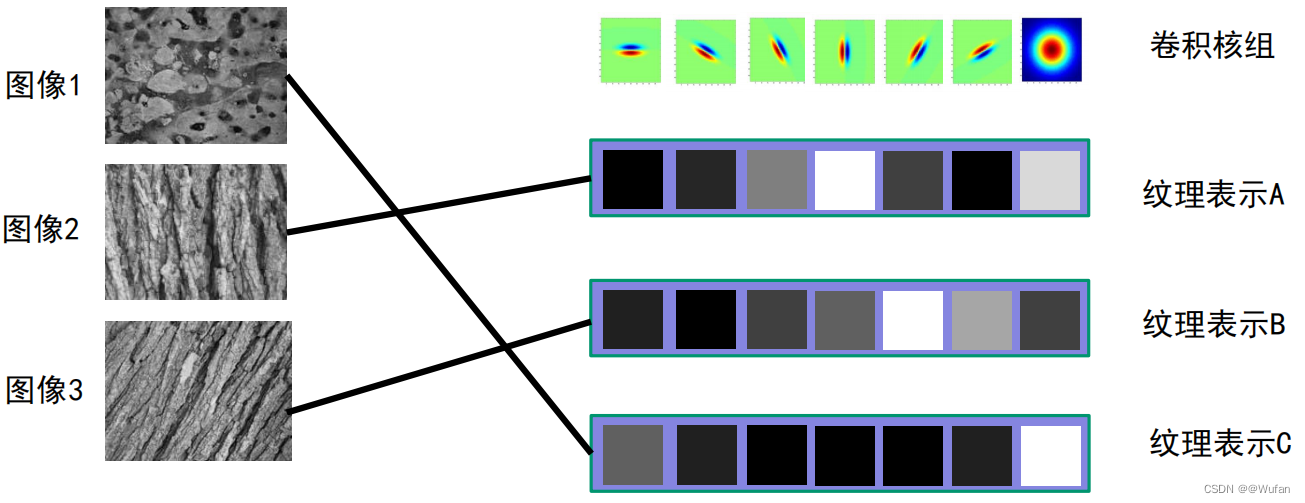
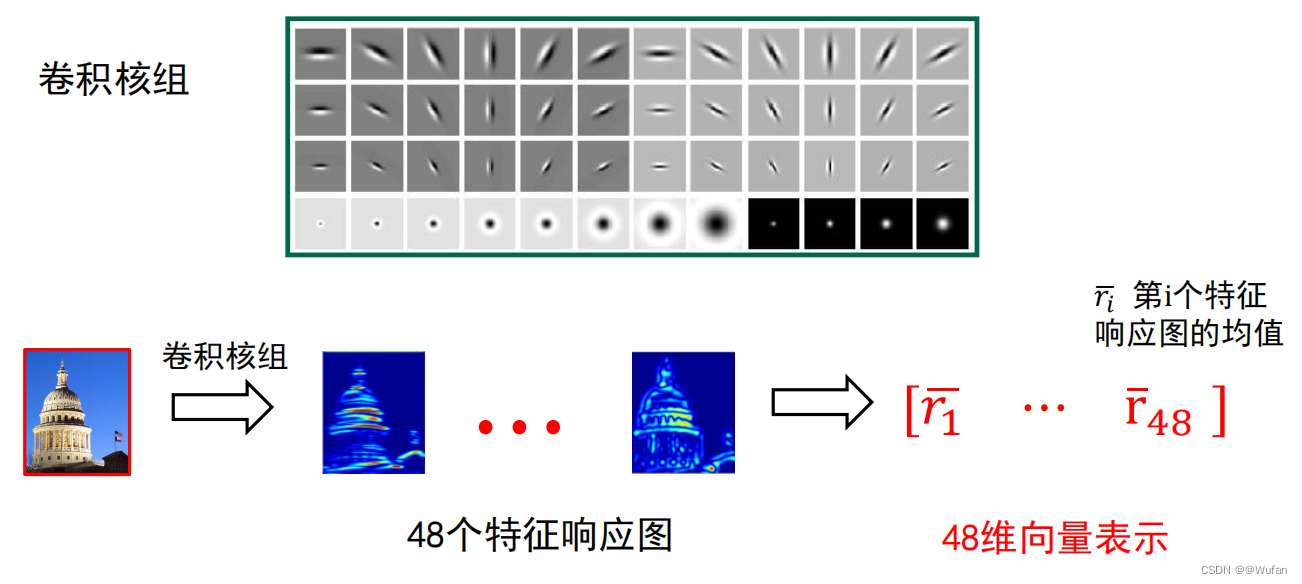
1.2 基于卷积核组的纹理表示方法
1)思路
利用卷积核组提取图像中的纹理基元;利用基元的统计信息来表示图像中的纹理
2)卷积核组

1.3 基于卷积核组的图像表示

1.3.1 过程设计
1)设计卷积核组;
设计重点:
① 卷积核类型(边缘、条形以及点状)
② 卷积核尺度(3-6个尺度)
③ 卷积核方向(6个角度)
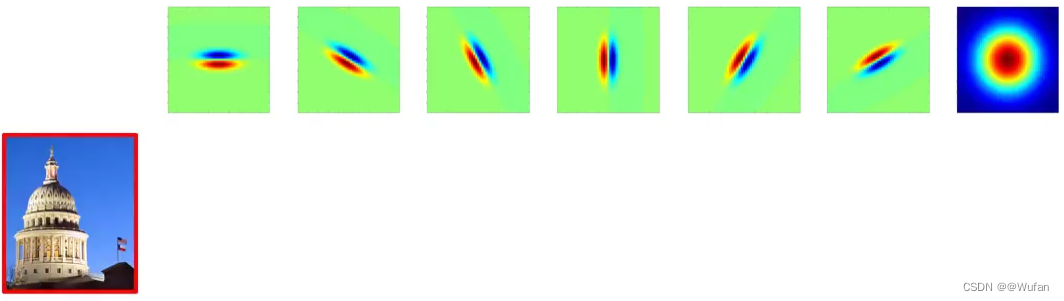
2)利用卷积核组对图像进行卷积操作获得对应的特征响应图组;
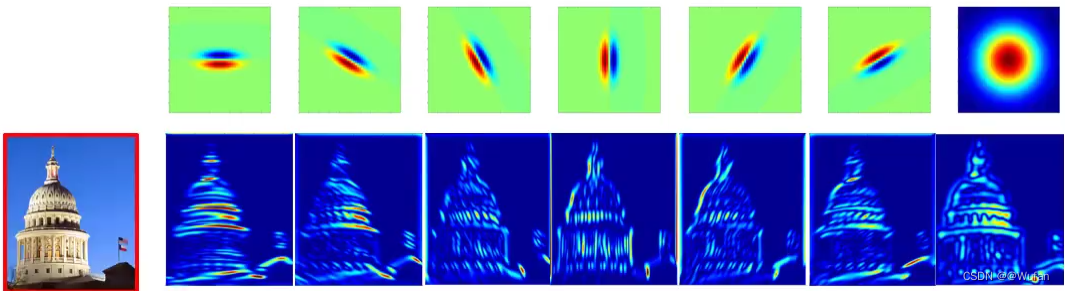
3)利用特征响应图的某种统计信息来表示图像中的纹理。
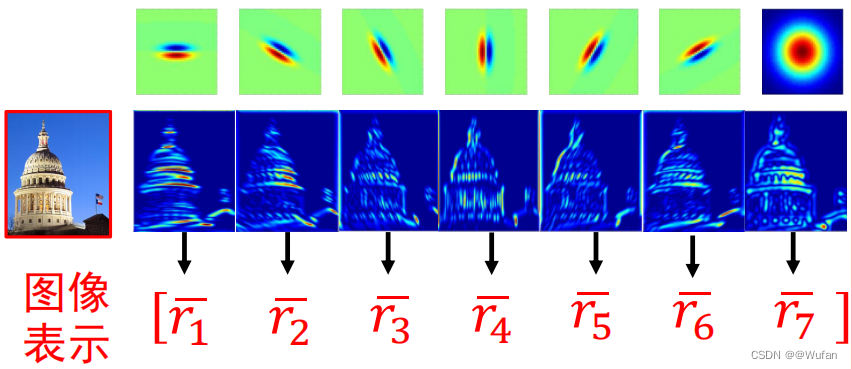
r 1 ‾ \overline{r_1} r1 第 i 个特征响应图的均值
4)小游戏:
1.3.2 示例
1)卷积核组

2)
1.4 纹理分类任务
- 忽略基元位置
- 关注出现了哪种基元对应的纹理以及基元出现的频率
2 卷积神经网络
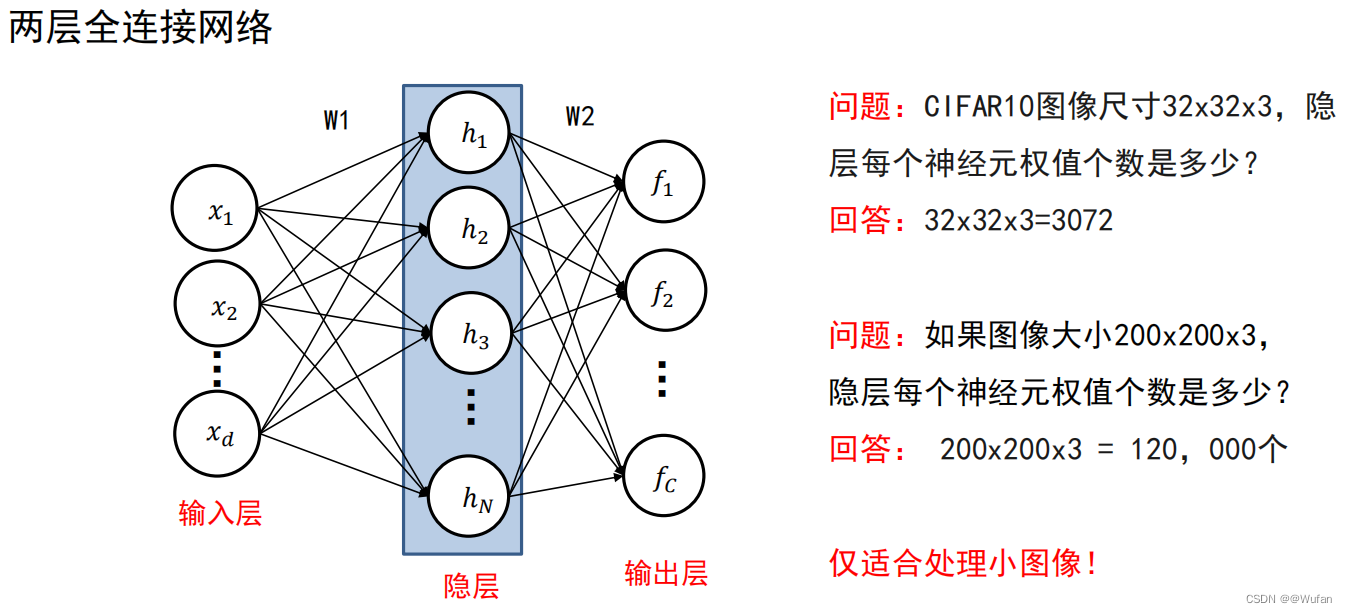
2.1 如何表示图像?
直接利用原始像素作为特征,展开为列向量。

cifar中每个图象可表示为一个3072(32323)维的向量
2.2 全连接神经网络的瓶颈
仅适合处理小图像!
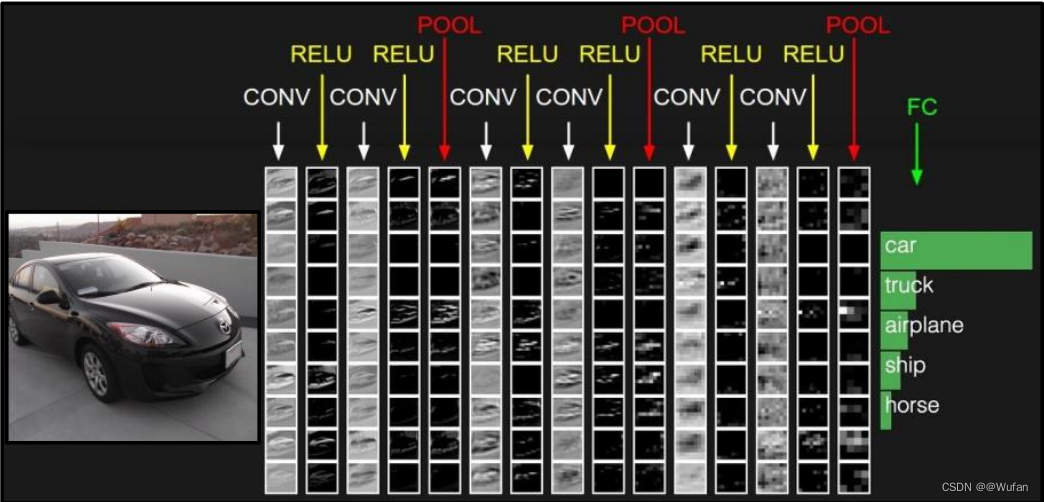
2.3 卷积神经网络
CONV:卷积层
RELU:激活层
POOL:池化层
FC:全连接层
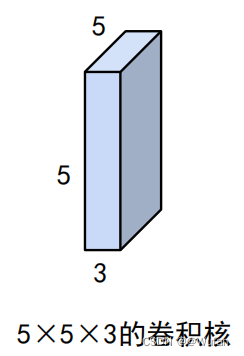
2.4 卷积网络中的卷积核
- 不仅具有宽和高,还具有深度,常写成如下形式:宽度 * 高度 * 深度
- 卷积核参数不仅包括核中存储的权值,还包括一个偏置值
2.5 卷积网络中的卷积操作
计算过程:
1)将卷积核展成一个553的向量,同时将其覆盖的图像区域按相同的展开方式展成553的向量
2)计算两者的点乘
3)在点乘的结果上加上偏移量
数学公式:
w T x w^Tx wTx + b
w为卷积核的权值,b为卷积核的偏置
结果:
1)使用 1 个卷积核
特征响应图中每个位置上的值反映了图像上对应位置是否存在卷积核所记录的基元结构信息
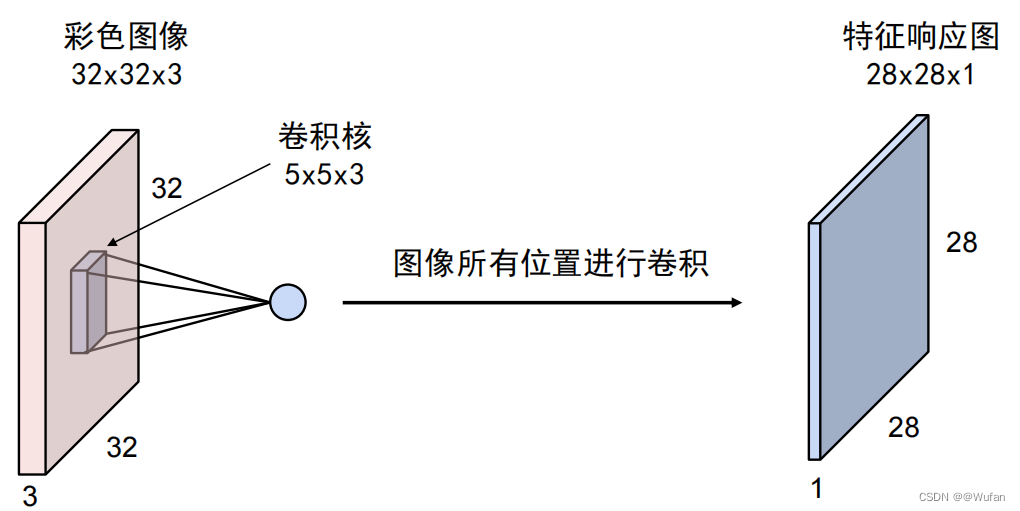
2)使用多个卷积核
① 特征响应图组深度等于卷积核的个数;
② 不同的特征响应图反映了输入图像对不同卷积核的响应结果;
③ 同一特征响应图上不同位置的值表示输入图像上不同位置对同一卷积核的响应结果。
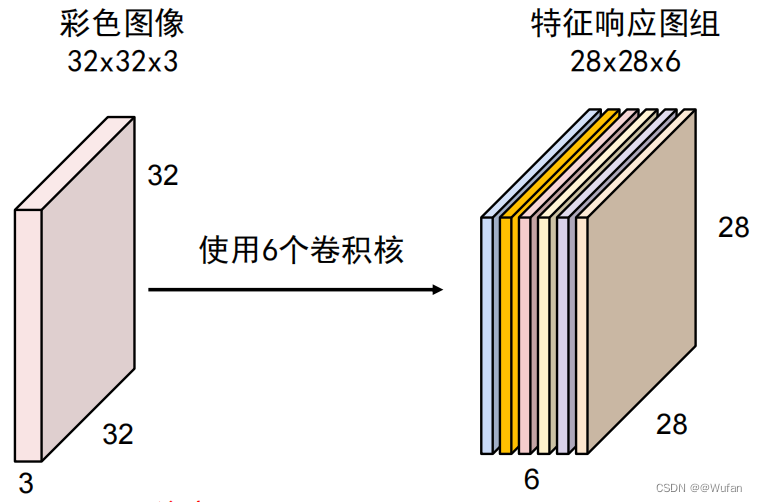
注:
卷积层输入不限于图像,可以是任意三维数据矩阵;
该层的卷积核深度要求与输入的三维矩阵的深度一致。
2.6 卷积步长
卷积神经网络中,卷积核可以按照指定的间隔进行卷积操作,这个间隔就是卷积步长。
输入数据矩阵尺寸:W1 × H1
输入特征图组尺寸:W2 × H2
W2与W1关系如下:
\qquad W2 = (W1 - F) / S + 1
\qquad H2 = (H2 - F) / S + 1
F:卷积核尺寸
S:卷积步长
例:卷积尺寸7 × 7,卷积核尺寸3 × 3
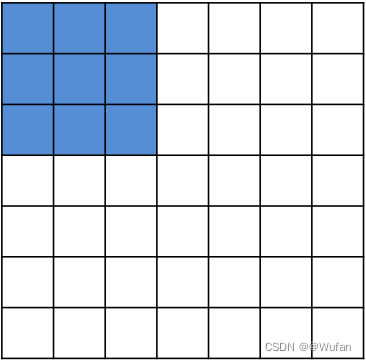
1)卷积步长:1 \qquad 卷积结果:5 × 5
2)卷积步长:2 \qquad 卷积结果:3 × 3
2.7 边界填充
卷积神经网络中最常用的填充方式是零值填充。
作用:保持输入、输出尺寸一致
输入数据矩阵尺寸:W1 × H1
输出特征图组尺寸:W2 × H2
W2与21关系如下:
\qquad W2 = (W1 - F + 2P) / S + 1
\qquad H2 = (H2 - F + 2P) / S +1
F:卷积核尺寸
S:卷积步长
P:零填充数量
例:
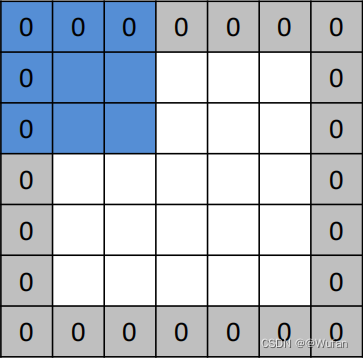
图像尺寸:5 × 5
卷积核尺寸:3 × 3
卷积步长:1
零值填充:1
卷积结果:5 × 5
2.8 特征响应图组尺寸计算
给定输入数据矩阵时,影响输出的特征图组尺寸大小的因素:
1)卷积核的宽、高;
2)是否采用边界填充操作;
3)卷积步长;
4)该层的卷积核个数。
输入数据矩阵尺寸:W1 × H1 × D1
输出特征图组尺寸:W2 × H2 × D2
特征图组尺寸计算如下:
\qquad W2 = (W1 - F + 2P) / S + 1
\qquad H2 = (H2 - F + 2P) / S + 1
\qquad D2 = K
卷积层的4个超参数:
F:卷积核尺寸
S:卷积步长
P:零填充数量
K:卷积核个数
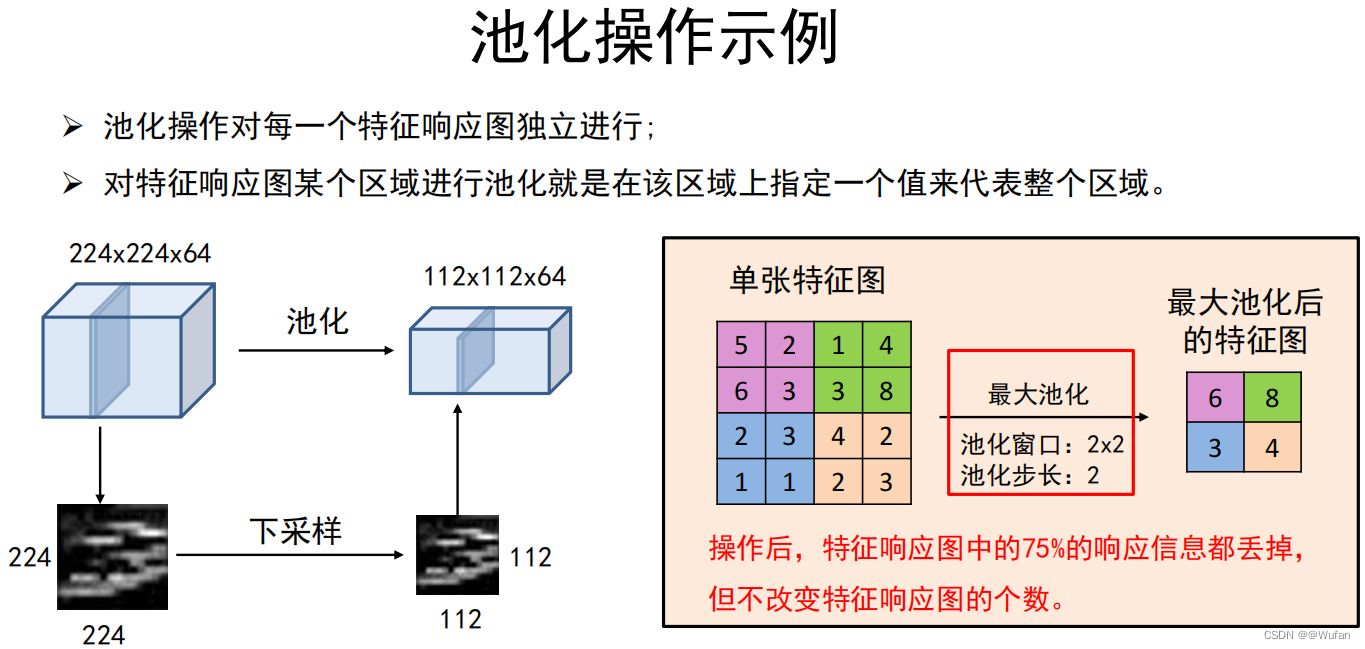
2.9 池化操作
池化的作用:对每一个特征响应图独立进行,降低特征响应图组中每个特征响应图的宽度和高度,减少后续卷积层的参数的数量,降低计算资源耗费,进而控制过拟合。
池化操作:对特征响应图某个区域进行池化就是在该区域上指定一个值来代表整个区域。
常见的池化操作:
最大池化:使用区域内的最大值来代表这个区域
平均池化:采用区域内所有值的均值作为代表
3 损失函数&优化算法
损失函数:交叉熵损失
优化算法:SGD、带动量的SGD以及ADAM
4 图像增强
1)存在的问题:过拟合的原因是学习样本太少,导致无法训练出能够泛化到新数据的模型。
2)数据增强:是从现有的训练样本中生成更多的训练数据,其方法是利用多种能够生成可信图像的随机变换来增强样本。
3)数据增强的目标:模型在训练时不会两次查看完全相同的图像。这让模型能够观察到数据的更多内容,从而具有更好的泛化能力
4.1 样本增强方案
4.1.1 翻转

4.1.2 随即缩放&抠图
\quad 以残差网络中的样本增强方法为例
\quad 输入要求:224×224的彩色图片
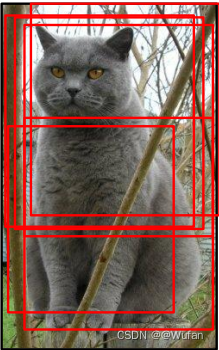
\quad 训练阶段:在不同尺度、不同区域随机扣取
1)在[256,480]之间随机选择一个尺寸L
2)将训练样本缩放至短边 = L
3)在该样本上随机采样一个224 × 224的图像区域
\quad 测试阶段:按照一套预先定义的方式扣取
1)将图像缩放成5种尺寸:{224,256,384,480,640}
2)对每一个尺度的图像及其镜像图像,分别在其四个角及中间位置扣取224 × 224区域,即可获得10个图像
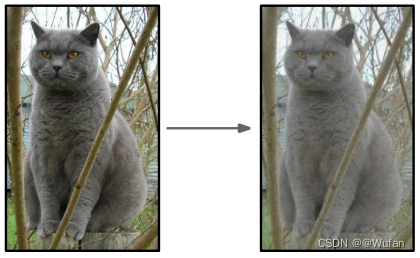
4.1.3 色彩抖动
操作步骤:
1)利用主成分分析方法提取当前图像的色彩数据([R G B])的主轴;
2)沿着主轴方向随机采样一个偏移;
3)将偏移量加入当前图像的每个像素。
4.1.4 其他方案
随机联合下述操作:
1)平移
2)旋转
3)拉伸
4)径向畸变
5)裁剪
。。。