全连接神经网络 MLP
最近开始进行模型压缩相关课题,复习一下有关的基础知识。
1. MLP简介

上图是一个简单的MLP,这是典型的三层神经网络的基本构成,Layer L1是输入层,Layer L2是隐含层,Layer L3是隐含层。
为了方便下面的公式描述,引入一张带公式的图。

i是input层,h是hide层,o是output层。
2. MLP 正向传播
正向传播其实就是预测过程,就是由输入到输出的过程。
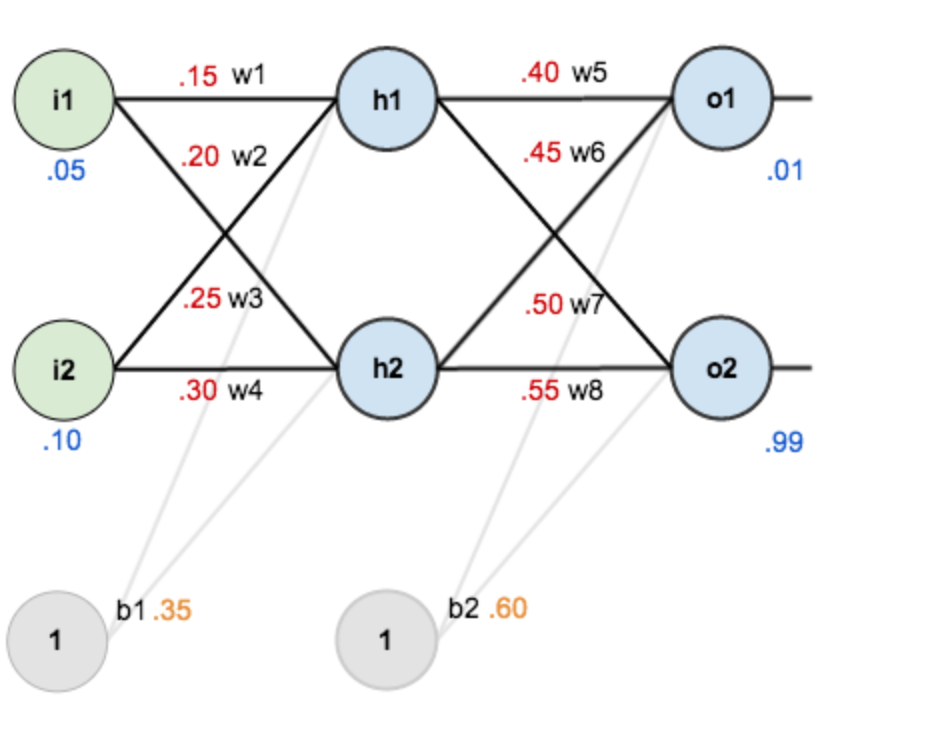
为之前的图片赋上初值,
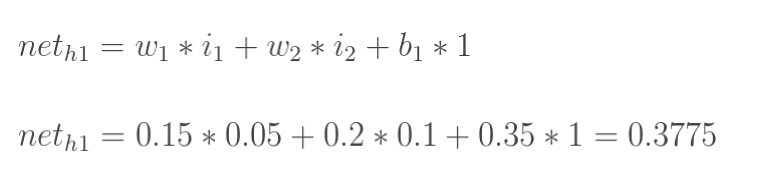
![]()
上述变量中,存在着如下过程:原始输入-> 带权计算-> net_h1-> 激活函数-> out_h1
同理,可以计算另一个隐层net_h2, out_h2,以及输出层net_o1, net_o2, out_o1, out_o2
此时在输出端我们可以得到一个预测值,但是在随机初始化权值的情况下,这个值一定还有上升的空间,怎么才能使这个值变得更为准确呢?
3. MLP 反向传播
MLP的反向传播过就是对于神经网络的训练过程。在这里,我们训练的是之前各条边上的权值。
3.1 总误差 (square error)
![]()
target为该样本的正确值,output为这一轮预测的值。
![]()
这里存在两个输出,所以,对于所有输出求和,并最终计算E_total
![]()
推广至N个输出(分类),则是把N各分类中的输出(一般是分类概率)误差分别求出,最终求和。
在这里的总误差在下面的应用时,主要看的是接受到了几个误差的影响(如果只接受到一个误差的影响,那就只使用一个误差)。
3.2 输出层参数更新
以权重参数w5为例,如果我们想知道w5对整体误差产生了多少影响,可以用整体误差对w5求偏导求出:(链式求导法则)


现在我们来分别计算每个式子的值:
计算![]() :
:

计算![]() :
:

(这一步实际上就是对sigmoid函数求导,比较简单,可以自己推导一下)
计算![]() :
:
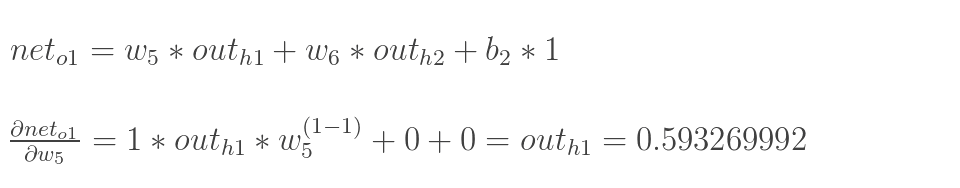
最后三者相乘:

这样我们就计算出整体误差E(total)对w5的偏导值。
回过头来再看看上面的公式,我们发现:
![]()
为了表达方便,用![]() 来表示输出层的误差:
来表示输出层的误差:

因此,整体误差E(total)对w5的偏导公式可以写成:
![]()
如果输出层误差计为负的话,也可以写成:

最后我们来更新w5的值:
![]()
(其中,![]() 是learning rate,这里我们取0.5)
是learning rate,这里我们取0.5)
3.3 隐含层参数更新
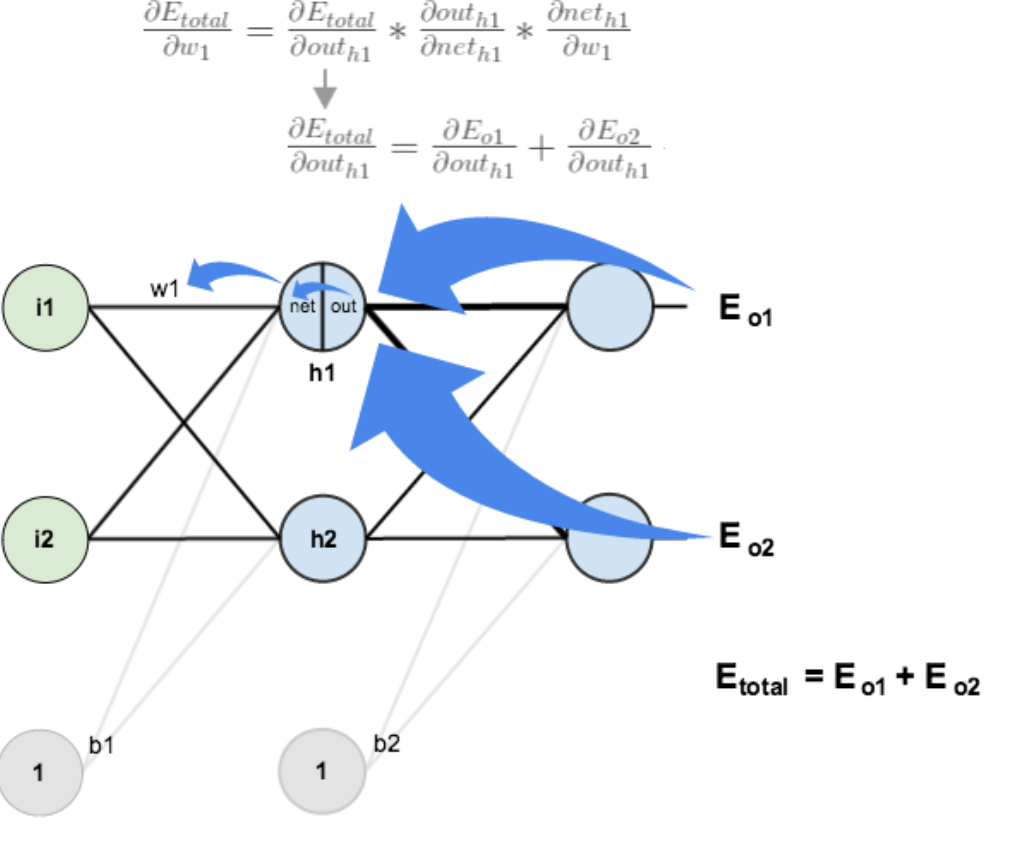
计算![]() :
:
![]()
先计算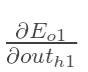 :
:
![]()
![]()
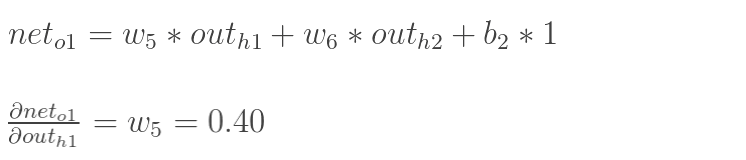
![]()
同理,计算出:
![]()
两者相加得到总值:
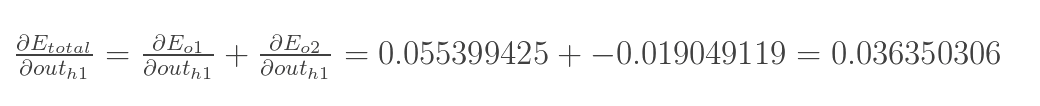
再计算![]() :
:

再计算![]() :
:

最后,三者相乘:

为了简化公式,用sigma(h1)表示隐含层单元h1的误差:

最后,更新w1的权值:
![]()
Python代码:
#coding:utf-8
import random
import math
#
# 参数解释:
# "pd_" :偏导的前缀
# "d_" :导数的前缀
# "w_ho" :隐含层到输出层的权重系数索引
# "w_ih" :输入层到隐含层的权重系数的索引
class NeuralNetwork:
LEARNING_RATE = 0.5
def __init__(self, num_inputs, num_hidden, num_outputs, hidden_layer_weights = None, hidden_layer_bias = None, output_layer_weights = None, output_layer_bias = None):
self.num_inputs = num_inputs
self.hidden_layer = NeuronLayer(num_hidden, hidden_layer_bias) self.output_layer = NeuronLayer(num_outputs, output_layer_bias) self.init_weights_from_inputs_to_hidden_layer_neurons(hidden_layer_weights) self.init_weights_from_hidden_layer_neurons_to_output_layer_neurons(output_layer_weights) def init_weights_from_inputs_to_hidden_layer_neurons(self, hidden_layer_weights): weight_num = 0 for h in range(len(self.hidden_layer.neurons)): for i in range(self.num_inputs): if not hidden_layer_weights: self.hidden_layer.neurons[h].weights.append(random.random()) else: self.hidden_layer.neurons[h].weights.append(hidden_layer_weights[weight_num]) weight_num += 1 def init_weights_from_hidden_layer_neurons_to_output_layer_neurons(self, output_layer_weights): weight_num = 0 for o in range(len(self.output_layer.neurons)): for h in range(len(self.hidden_layer.neurons)): if not output_layer_weights: self.output_layer.neurons[o].weights.append(random.random()) else: self.output_layer.neurons[o].weights.append(output_layer_weights[weight_num]) weight_num += 1 def inspect(self): print('------') print('* Inputs: {}'.format(self.num_inputs)) print('------') print('Hidden Layer') self.hidden_layer.inspect() print('------') print('* Output Layer') self.output_layer.inspect() print('------') def feed_forward(self, inputs): hidden_layer_outputs = self.hidden_layer.feed_forward(inputs) return self.output_layer.feed_forward(hidden_layer_outputs) def train(self, training_inputs, training_outputs): self.feed_forward(training_inputs) # 1. 输出神经元的值 pd_errors_wrt_output_neuron_total_net_input = [0] * len(self.output_layer.neurons) for o in range(len(self.output_layer.neurons)): # ∂E/∂zⱼ pd_errors_wrt_output_neuron_total_net_input[o] = self.output_layer.neurons[o].calculate_pd_error_wrt_total_net_input(training_outputs[o]) # 2. 隐含层神经元的值 pd_errors_wrt_hidden_neuron_total_net_input = [0] * len(self.hidden_layer.neurons) for h in range(len(self.hidden_layer.neurons)): # dE/dyⱼ = Σ ∂E/∂zⱼ * ∂z/∂yⱼ = Σ ∂E/∂zⱼ * wᵢⱼ d_error_wrt_hidden_neuron_output = 0 for o in range(len(self.output_layer.neurons)): d_error_wrt_hidden_neuron_output += pd_errors_wrt_output_neuron_total_net_input[o] * self.output_layer.neurons[o].weights[h] # ∂E/∂zⱼ = dE/dyⱼ * ∂zⱼ/∂ pd_errors_wrt_hidden_neuron_total_net_input[h] = d_error_wrt_hidden_neuron_output * self.hidden_layer.neurons[h].calculate_pd_total_net_input_wrt_input() # 3. 更新输出层权重系数 for o in range(len(self.output_layer.neurons)): for w_ho in range(len(self.output_layer.neurons[o].weights)): # ∂Eⱼ/∂wᵢⱼ = ∂E/∂zⱼ * ∂zⱼ/∂wᵢⱼ pd_error_wrt_weight = pd_errors_wrt_output_neuron_total_net_input[o] * self.output_layer.neurons[o].calculate_pd_total_net_input_wrt_weight(w_ho) # Δw = α * ∂Eⱼ/∂wᵢ self.output_layer.neurons[o].weights[w_ho] -= self.LEARNING_RATE * pd_error_wrt_weight # 4. 更新隐含层的权重系数 for h in range(len(self.hidden_layer.neurons)): for w_ih in range(len(self.hidden_layer.neurons[h].weights)): # ∂Eⱼ/∂wᵢ = ∂E/∂zⱼ * ∂zⱼ/∂wᵢ pd_error_wrt_weight = pd_errors_wrt_hidden_neuron_total_net_input[h] * self.hidden_layer.neurons[h].calculate_pd_total_net_input_wrt_weight(w_ih) # Δw = α * ∂Eⱼ/∂wᵢ self.hidden_layer.neurons[h].weights[w_ih] -= self.LEARNING_RATE * pd_error_wrt_weight def calculate_total_error(self, training_sets): total_error = 0 for t in range(len(training_sets)): training_inputs, training_outputs = training_sets[t] self.feed_forward(training_inputs) for o in range(len(training_outputs)): total_error += self.output_layer.neurons[o].calculate_error(training_outputs[o]) return total_error class NeuronLayer: def __init__(self, num_neurons, bias): # 同一层的神经元共享一个截距项b self.bias = bias if bias else random.random() self.neurons = [] for i in range(num_neurons): self.neurons.append(Neuron(self.bias)) def inspect(self): print('Neurons:', len(self.neurons)) for n in range(len(self.neurons)): print(' Neuron', n) for w in range(len(self.neurons[n].weights)): print(' Weight:', self.neurons[n].weights[w]) print(' Bias:', self.bias) def feed_forward(self, inputs): outputs = [] for neuron in self.neurons: outputs.append(neuron.calculate_output(inputs)) return outputs def get_outputs(self): outputs = [] for neuron in self.neurons: outputs.append(neuron.output) return outputs class Neuron: def __init__(self, bias): self.bias = bias self.weights = [] def calculate_output(self, inputs): self.inputs = inputs self.output = self.squash(self.calculate_total_net_input()) return self.output def calculate_total_net_input(self): total = 0 for i in range(len(self.inputs)): total += self.inputs[i] * self.weights[i] return total + self.bias # 激活函数sigmoid def squash(self, total_net_input): return 1 / (1 + math.exp(-total_net_input)) def calculate_pd_error_wrt_total_net_input(self, target_output): return self.calculate_pd_error_wrt_output(target_output) * self.calculate_pd_total_net_input_wrt_input(); # 每一个神经元的误差是由平方差公式计算的 def calculate_error(self, target_output): return 0.5 * (target_output - self.output) ** 2 def calculate_pd_error_wrt_output(self, target_output): return -(target_output - self.output) def calculate_pd_total_net_input_wrt_input(self): return self.output * (1 - self.output) def calculate_pd_total_net_input_wrt_weight(self, index): return self.inputs[index] # 文中的例子: nn = NeuralNetwork(2, 2, 2, hidden_layer_weights=[0.15, 0.2, 0.25, 0.3], hidden_layer_bias=0.35, output_layer_weights=[0.4, 0.45, 0.5, 0.55], output_layer_bias=0.6) for i in range(10000): nn.train([0.05, 0.1], [0.01, 0.09]) print(i, round(nn.calculate_total_error([[[0.05, 0.1], [0.01, 0.09]]]), 9)) #另外一个例子,可以把上面的例子注释掉再运行一下: # training_sets = [ # [[0, 0], [0]], # [[0, 1], [1]], # [[1, 0], [1]], # [[1, 1], [0]] # ] # nn = NeuralNetwork(len(training_sets[0][0]), 5, len(training_sets[0][1])) # for i in range(10000): # training_inputs, training_outputs = random.choice(training_sets) # nn.train(training_inputs, training_outputs) # print(i, nn.calculate_total_error(training_sets))