我们知道,数据不仅包含文字、数字,还包含图片、视频等,如何更好地查看、识别和解释图像和视频的内容,就像人类视觉一样,一直是目前人工智能的主要研究方向。机器学习无疑是现代数据科学的核心,在经历了几十年回归、分类、决策树、异常检测的沉淀后,数据科学的魔爪也不断地向更深度的学习试探。
一、计算机视觉的世界
今天,ofter会通过最简单、易懂、完整的讲解(尽量不出现公式之类枯燥的元素),带大家领略计算机视觉的世界!
- 人工神经网络的常用模型,以及如何使用正确的模型;
- 人工神经网络的实例检测和分割实战应用。

二、常规神经网络(NNs)
图片的本质是数字,通过对大量数字的处理,来实现我们对图片的一系列处理:
- 图像分类
- 图像分类+定位
- 实例检测
- 实例分割
- 图像风格转换
- 图像着色
- 影像重建
- 图像超分辨率
- 图像合成

最简单的图片类型,应该就是黑白的手写数字图了吧?这和我们小时候咿呀学语的状况很像,一开始我们也是在纸上写数字。从上图中,也可以看出来,我们写一个数字,就一笔,但计算机看到的却是一长串数字列表。
为了模拟人类视觉神经对图片的处理过程,有人发明了人工神经网络,其实就是把神经收发的信号换成数字。
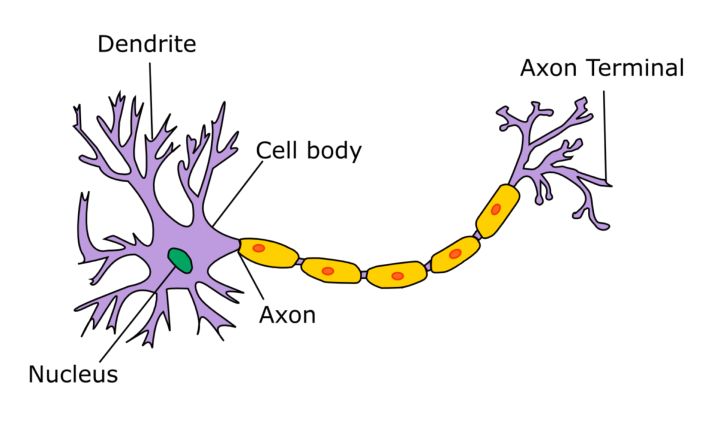
看下图,Input Layer是一个个数字,也可以是一个个数组,通过一层层的Hidden Layer加工处理,最后识别图片中的内容。

不过呢,这个是对人类神经网络的初步模仿,无论是速度、准确度肯定都没法与人类的视觉相比。因此,我们研究出了卷积神经网络(CNNs)、循环神经网络(RNNs)等模型来不断进化我们的计算机,使得计算机的识别力无限逼近人类,甚至超越人类。
三、卷积神经网络(CNNs)
今天,我们重点介绍下卷积神经网络的发展过程以及常用模型。卷积神经网络大大提高了图片的计算性能,它的架构下主要分为3个类型的层:卷积层、池化层、全连接层(神经网络)。
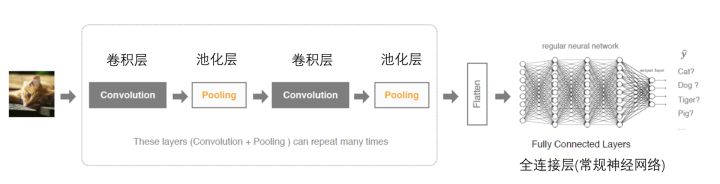
上图,也很明显,就是经过N次的卷积+池化,最后再进行常规的神经网络,输出识别内容。因为,作为数据科学家,其实不需要知道具体的卷积层、池化层以及常规神经网络是怎么运作的,我们只需要明白某个模型能带来什么样的识别、性能、效果就可以了,所以我就不详细展开每个模型具体每层是怎么计算的了。

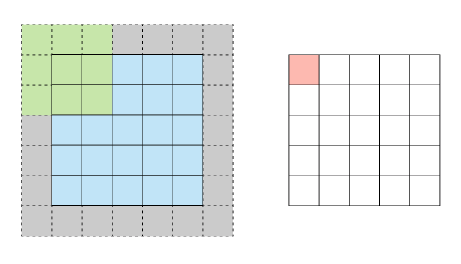
我们需要知道4个参数,这个在模型训练时要定义:
• 过滤器大小 (Filter,例如3 × 13)
• 过滤器的数量 (我们要使用多少个过滤器,例如我们可以使用 20 个过滤器,则 k = 20)
• Stride (指定过滤器每次移动的步长,例如,Stride = 2)

• 零填充量 (添加了一层零值像素(灰色区域),这样我们的特征图就不会缩小,例如 Padding = 2)
四、卷积神经网络的应用
4.1 常用的架构
近10年的时间里,我们研究了许多架构,性能、准确度也是不断地提升,从下图也可以看出来,总体上发展得比较迅速。
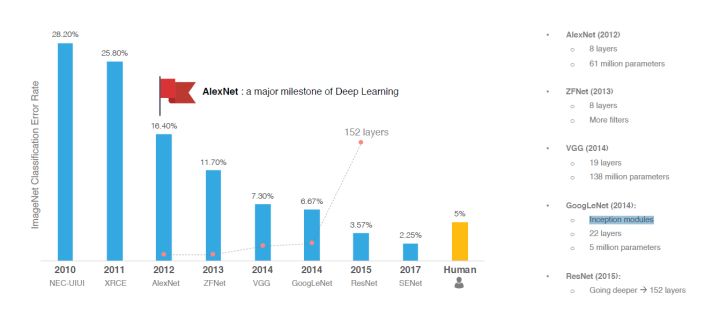
每一种架构,或多或少都有点站在前人肩膀上的意味,再加上自己的一些亮点。比如AlexNet、VGG、GoogleNet,它们基于卷积神经网络,在卷积层、池化层采用了不同的过滤器、不同数量的过滤器,不同的stride, padding,总之是各种排列组合,通过很多很多次的测试得到最佳案例。更多的架构:

4.2 训练模型
主要有2种训练方式:从头开始训练,预训练模型迁移学习。
在实践中,很少有人会从头开始训练整个卷积网络,从头开始训练一个准确的模型需要大量数据,大约数百万个样本,这需要大量时间。因此我们重点看下迁移学习,举个简单的例子,在学习识别汽车时获得的知识可以应用于识别卡车。在哪里找类似的预训练模型呢?推荐一个网址:http://modelzoo.co

许多研究和开发人员为各种任务训练机器学习模型,并在 Model Zoo 中共享他们的预训练模型。作为数据科学家,你可以评估哪个模型更加适合你关注的场景和数据,或组合新用途,甚至改进以前发布的模型。
4.3 图像处理

4.3.1 分类和定位
分类和定位比较好理解。
4.3.2 语义分割
语义分割的应用包括自动驾驶、医学成像分析、工业检测、室内导航,甚至虚拟或增强现实系统等。下图是医学成像的一个例子。
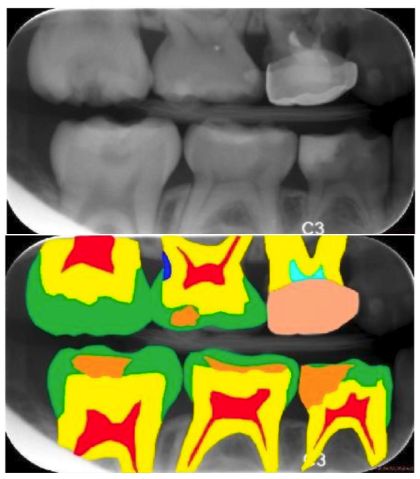
语义分割是将图像中的每种元素进行分类,具有相同标签的像素具有相同特征。比如下图:

但是,语义分割仍然不是一个成熟的领域,许多研究人员仍在研究它。 过去几年已经开发出了许多新方法。

4.3.3 实例检测

实例检测模型主要有2大类:基于预测区域的模型和不基于预测区域的模型。
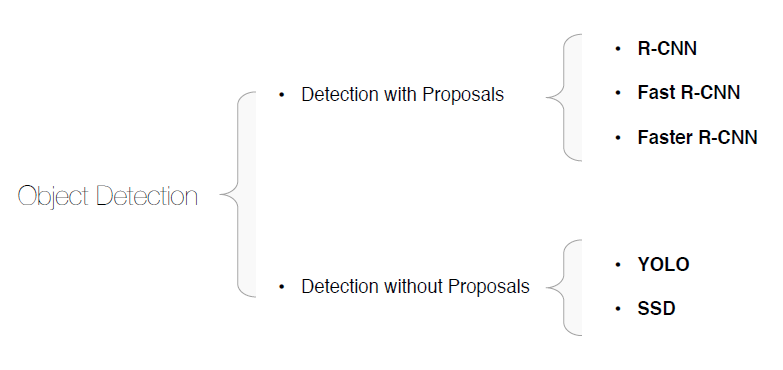
CSDN上也有好多YOLO、SSD的案例,总体来说,Faster R-CNN 比 YOLO/SSD 算法慢,但更准确。因此,当实时性比较高的时候,我们肯定要采用YOLO这样的模型,而实时性要求不高但准确度要求高的时候,我们就需要采用Faster R-CNN。
4.3.4 实例分割
Mask R-CNN 是非常有影响力的实例分割技术。 这是一个两阶段的框架:第一阶段扫描图像并生成建议(可能包含对象的区域)。 第二阶段对建议内容进行分类并生成边框和蒙版。

五、总结
今天,ofter为大家介绍了些常用的深度学习模型和使用场景。需要使用机器学习的时候,你就知道大概要使用什么样的模型。下一期,我们将通过实战,用python+tensorflow/keras等框架+模型进行图片内容的识别,敬请期待!