文章目录
文章:Attention is all you need
文章链接:https://arxiv.org/abs/1706.03762
一、简介
Transformer 是谷歌在 17 年做机器翻译任务的 “Attention is all you need” 的论文中提出的,引起了相当大的反响。 每一位从事 NLP 研发的同仁都应该透彻搞明白Transformer,它的重要性毫无疑问,尤其是你在看完我这篇文章之后,我相信你的紧迫感会更迫切,我就是这么一位善于制造焦虑的能手。不过这里没打算重点介绍它,想要入门 Transformer 的可以参考以下三篇文章:一个是 Jay Alammar 可视化地介绍 Transformer 的博客文章 The Illustrated Transformer ,非常容易理解整个机制,建议先从这篇看起, 这是中文翻译版本;第二篇是 Calvo 的博客:Dissecting BERT Part 1: The Encoder ,尽管说是解析 Bert,但是因为 Bert 的 Encoder 就是 Transformer,所以其实它是在解析 Transformer,里面举的例子很好;再然后可以进阶一下,参考哈佛大学 NLP 研究组写的 “The Annotated Transformer. ”,代码原理双管齐下,讲得也很清楚。
对于Transformer来说,需要明确加入位置编码学习position Embedding。因为对于self Attention来说,它让当前输入单词和句子中任意单词进行相似计算,然后归一化计算出句子中各个单词对应的权重,再利用权重与各个单词对应的变换后V值相乘累加,得出集中后的embedding向量,此间是损失掉了位置信息的。因此,为了引入位置信息编码,Transformer对每个单词一个Position embedding,将单词embedding和单词对应的position embedding加起来形成单词的输入embedding。
Transformer中的self Attention对文本的长距离依赖特征的提取有很强的能力,因为它让当前输入单词和句子中任意单词进行相似计算,它是直接进行的长距离依赖特征的获取的,不像RNN需要通过隐层节点序列往后传,也不像CNN需要通过增加网络深度来捕获远距离特征。此外,对应模型训练时的并行计算能力,Transformer也有先天的优势,它不像RNN需要依赖前一刻的特征量。
张俊林大佬在https://blog.csdn.net/malefactor/article/details/86500387中提到过,在Transformer中的Block中不仅仅multi-head attention在发生作用,而是几乎所有构件都在共同发挥作用,是一个小小的系统工程。例如Skip connection,LayerNorm等也是发挥了作用的。对于Transformer来说,Multi-head attention的head数量严重影响NLP任务中Long-range特征捕获能力:结论是head越多越有利于捕获long-range特征。
二、transformer结构
详见我的博客总结《Attention is all you need》
三、用于文本分类的transformer
Transformer结构有两种:Encoder和Decoder,在文本分类中只使用到了Encoder,Decoder是生成式模型,主要用于自然语言生成的。
1. embedding layer(嵌入层)
获得词的分布式表示
2. positional encoding(位置编码)
由于attention没有包含序列信息(即语句顺序并不影响结构),因此需要加入位置的信息,在transformer中选择将顺序的信息加入到embedding中。
设某个词在句子中的位置为pos,词的embeding维度为 ,我们需要产生一个关于pos的维度为 的向量。因此可以使用公式: , 来计算pos对应的位置向量的各个维度的值。
以 来举例, ;但是这种方式的编码并没有考虑到相对位置,因此在论文中使用了三角函数对奇偶维进行变化,下面是论文中的位置编码公式:
3. Scaled dot-product attention(缩放的点乘注意力机制)
在attention中query、key、value的来源各不相同,但是在该attention中query、key、value均是从同一个输入中产生。如下图中query、key、value均是将输入的embedding乘以一个矩阵产生的:

(可以观测到
的维度是由权重矩阵的维度决定的,因此维度的大小由设计者决定)
有了 后,我们先通过点积计算 与 的相似度,并且为了防止相似度放入 中太大,因此将点积结果除以 ,其中 是 的维度。在将结果放入到 中输出当前 与各个 的相似度,如下图:

有了
与各个
的相似度以后,使用这些相似度对
进行加权求和,得到当前
的输出:

上面介绍了Scaled dot-product attention的向量计算方式,但是在实际中为了加速计算需要使用矩阵的计算方式。下面介绍矩阵计算:
首先对于所有的输出计算对应的
,如下图:

(这样可以一次计算出所有输入的
,并记输出的矩阵为
)
计算相似度并加权求和

论文中的计算公式:
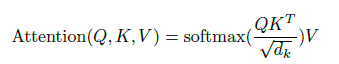
4. Multi-head attention(多头注意力)
在论文中他们发现将
在
, (即每个
的维度)维度上切成
份,然后分别进行scaled dot-product attention,并将最终的结果合并在一起,其中超参数
就是
的数量。
论文中的公式:

5. Padding mask
因为文本的长度不同,所以我们会在处理时对其进行padding。但是在进行attention机制时,注意力不应该放在padding的部分。因此将这些位置设置为非常大的负数,这样经过softmax后的概率接近0。
对于矩阵
的第
行第
列的元素表示的是第
个
与第
个
的相似度,为了进行padding mask,那么必须要将所有与padding key的相似度设为负无穷。因此生成一个形状与
相同的padding 矩阵,其中所有padding key对应的列设为false,其余为true。
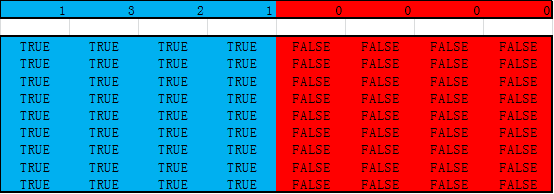
6. 残差连接

假设网络中某个层对输入
作用后的输出是
,那么增加残差连接后为
。当对该层求偏导时,
7. Layer Normalization
Batch Normalization:设某个batch中的样本均值为 ,样本方差为 ,那么BN的公式就是 。其主要是沿着batch方向进行的。
Layer Normalization:BN是在batch上计算均值和方差,而LN则是对每个样本计算均值和方差; 。可以方向公式中只是均值和方差不同而已。
8.Position-wise Feed-Forward network
这是一个全连接层,包含两个线性变换和一个非线性激活函数ReLU,公式为 。这个公式还可以用两个大小为 的一维卷积来实现,其中中间层的维度为 。
四、代码实现
详情参考:https://www.cnblogs.com/jiangxinyang/p/10210813.html
