1. 摘要
由于Transformer的大火,相对应的也出来了许多文章,但是这些文章的速度和精度相较于CNN还是差点意思,2021年微软研究院发表在ICCV上的一篇文章Swin Transformer是Transformer模型在视觉领域的又一次碰撞,Swin Transformer可能是CNN的完美替代方案。
论文名称:Swin Transformer: Hierarchical Vision Transformer using Shifted Windows
原论文地址: https://arxiv.org/abs/2103.14030
在论文中,作者指出之前的Transformer模型从NLP迁移到CV没有大放光彩的主要原因是:
- 两个 个领域涉及的scale不同,NLP的scale是标准固定的,而CV的scale变化范围非常大,相对于文本,视觉实体的尺度区别很大,例如车辆和人
- CV比起NLP需要更大的分辨率,而且CV中使用Transformer的计算复杂度是图像尺度的平方,这会导致计算量过于庞大。
那么本篇论文作者为了解决该问题所用的方法有:
- 引入CNN中常用的层次化构建方式Hierarchical feature maps)构建层次化Transformer
- 提出了 Shifted Windows Multi-Head Self-Attention(SW-MSA)的概念,通过此方法能够让信息在相邻的窗口中进行传递
这样一来通过限制在窗口内使用自注意力,带来了更高的效率并且通过移动,使得相邻两个窗口之间有了交互,上下层之间也就有了跨窗口连接,从而变相达到了一种全局建模的效果。另外层级式的结构不仅非常灵活的去建模各个尺度的信息并且计算复杂度随着图像大小线性增长。
因为有了像卷积神经网络一样的分层结构,有了多尺度的特征,所以很容易的应用到下游任务里,例如图像分类、物体检测、物体分割等
2. 引言
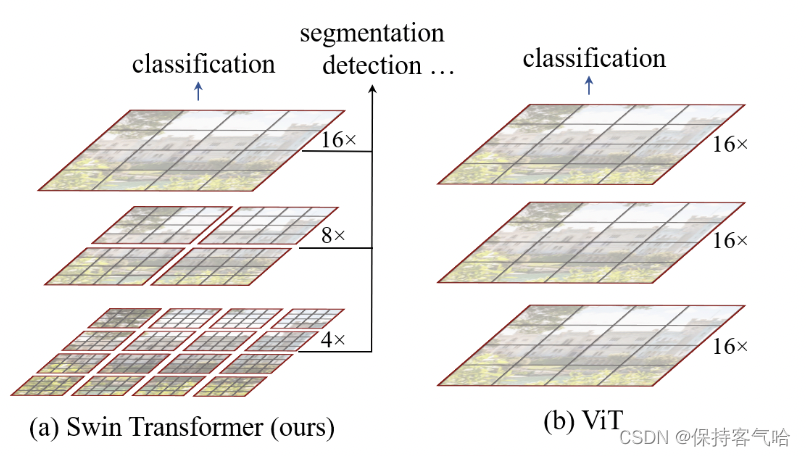
与之前的Vit(Vision Transformer)相比,论文中给出了相应的对比图如下,从中可以看出来两者的区别:
- Swin Transformer使用了类似卷积神经网络中的层次化构建方法(Hierarchical feature maps),比如特征图尺寸中有对图像下采样4倍的,8倍的以及16倍的,这样的backbone有助于在此基础上构建目标检测,实例分割等任务。而在之前的Vision Transformer中是一开始就直接下采样16倍,后面的特征图也是维持这个下采样率不变,这样对于多尺寸特征的获得会弱一些。
- Swin-Transformer使用窗口多头自注意力,将特征图划成多个不相交的区域,然后在每个窗口里进行自注意力计算,只要窗口大小固定,自注意力的计算复杂度也是固定的,那么总的计算复杂度就是图像尺寸的线性倍,而不是Vit对整个特征图进行全局自注意力计算,这样就减少了计算量,但是也隔绝了不同窗口之间的信息交流,随之作者提出后文的移动窗口自注意力计算(Shifted Windows Multi-Head Self-Attention(SW-MSA))
注:以16倍下采样为例,相当于把原图像划分为4×4的小patch,然后每个patch取一个像素值作为代表当前patch的像素值,或者取该patch的像素平均值作为代表像素值。其中,后者应该是更为合理的做法
3. 网络架构图
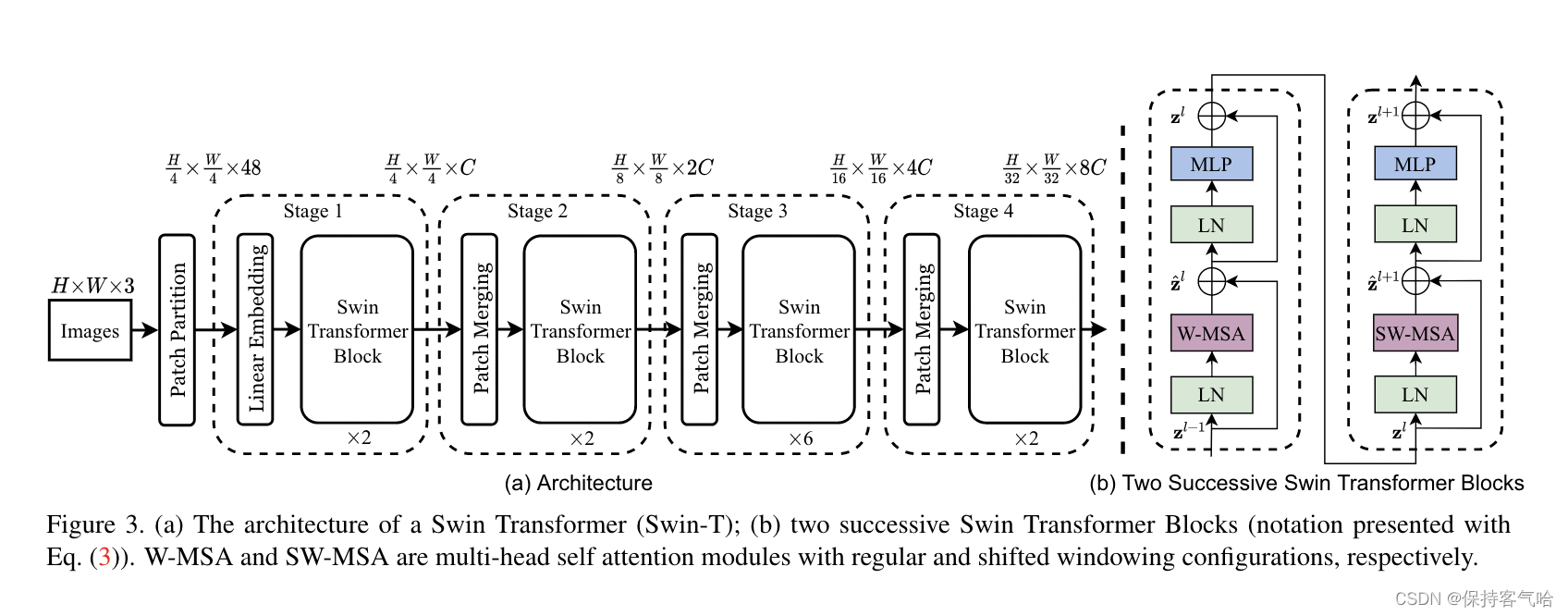
对于上图的流程解释如下:
- 输入图片H✖️W✖️3(假设是224✖️224✖️3),经过PatchPatition进行分块成为不重合的patch集合,其中每个patch的尺寸为4✖️4大小,在channel方向进行展平变成4✖️4✖️3=48,所以通过Patch Partition后图像shape由
[H, W, 3](224✖️224✖️3)变成了[H/4, W/4, 48](56✖️56✖️48),patch块的数量为H/4 x W/4(56✖️56),然后通过一个linear embedding将输划分后的patch特征维度变成我们所预制好的值(Transformer能够接受的值),这里是超参数C,对于上图Swin-T来说,C=96,即图像shape再由 [H/4, W/4, 48]变成了[H/4, W/4, C](56✖️56✖️96),前面的56✖️56会被拉直变成3136变成了这个序列长度,后面的96就是每个token的向量维度,然后问题就出现了,这里的3136并不是Transformer能够接受的长度,为了解决这个问题,Swin-Transformer就引入了基于窗口的自注意力计算,那每个窗口按照默认的就是有7✖️7=49个patch(默认参数window size =7),所以说序列长度就只有49的长度,就相当小了,这就是后面的Swin Transformer Block中包含的操作(后续会讲),经过它的输出shape还是[H/4, W/4, C](56✖️56✖️96); - 接下来如果想有多尺度的信息,那么就要构建一个层级式的Transformer,也就是说我们需要一个像卷积操作中类似于池化的操作,也就是紧接着的
Patch Merging操作,shape会由[H/4, W/4, C](56✖️56✖️96)变成[H/8, W/8, C](28✖️28✖️192)具体怎么操作看下文讲解; - 然后通过三个Stage构建不同大小的特征图,除了Stage1中先通过一个Linear Embeding层外,剩下三个stage都是先通过一个Patch Merging层进行下采样
在源码中Patch Partition和Linear Embeding就是直接通过一个卷积层实现的,想当于Vit中的Patch Projection
4. Patch Merging 操作
下图展示patch merging 的操作过程,顾名思义就是将邻近的小patch合并成一个大patch,这样就可以起到一个下采样特征图的效果了。
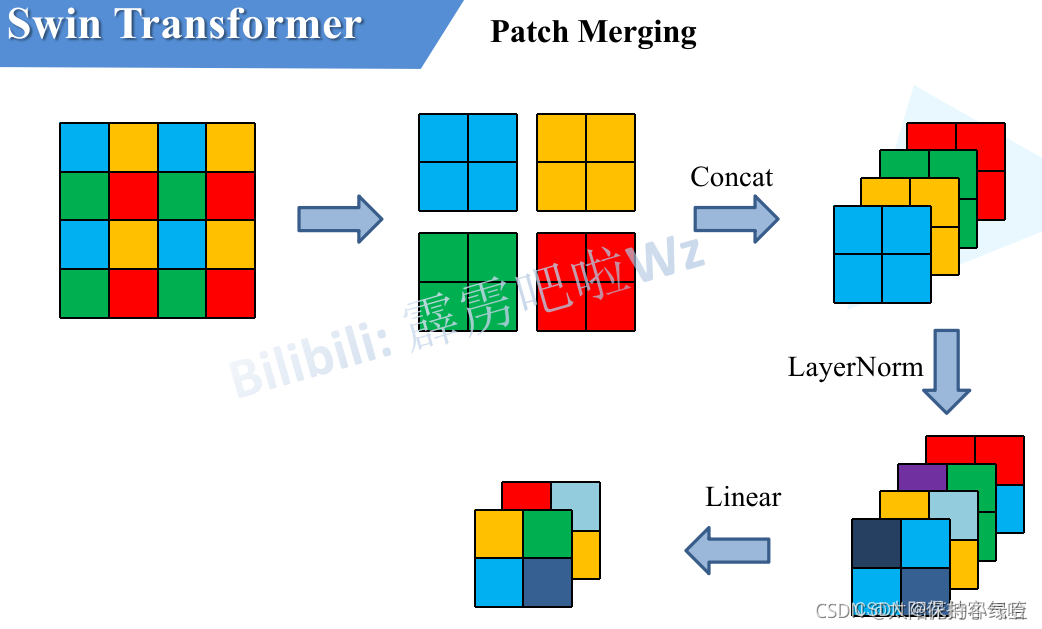
- 在这里我们是想下采样两倍,所以我们是每隔一个点选一个,得到上图中的4个2*2大小的张量,然后将四个张量在通道的维度上进行拼接,类似卷积操作的池化,为了和卷积网络那保持一致,我们只想让它翻倍而不是4倍,所以用1✖️1的卷积进行降维操作,通过Patch Merging层后,feature map的高和宽会减半,深度会翻倍。
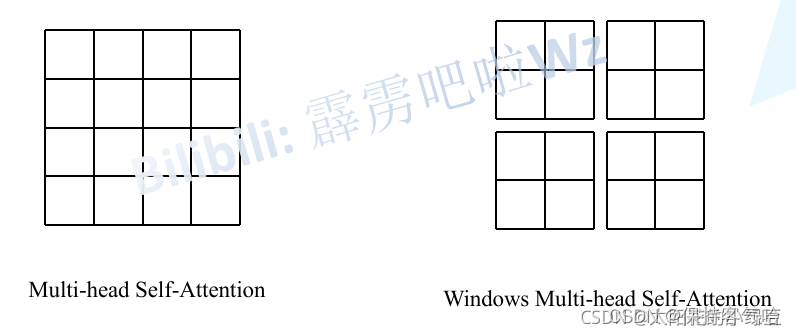
5. W-MSA操作
引入Windows Multi-head Self-Attention(W-MSA)模块是为了减少计算量,如下图所示,左侧使用的是普通的Multi-head Self-Attention(MSA)模块,对于feature map中的每个像素(或称作token,patch)在Self-Attention计算过程中需要和所有的像素去计算。但在图右侧,在使用Windows Multi-head Self-Attention(W-MSA)模块时,首先将feature map按照MxM(例子中的M=2)大小划分成一个个Windows,然后单独对每个Windows内部进行Self-Attention。
原论文中给出的计算量比较: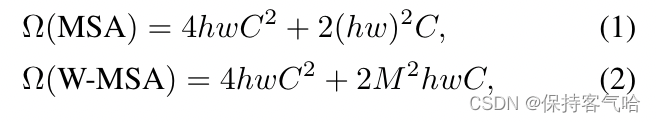
对于窗口的划分,这里以shape为(56✖️56✖️96)即56*56个patch为例,如下图所示(注意图中的m应该也是M=7,笔误)

下图是对于两者计算量的比较:

其实不要小看hw和M*M,代入数值进去就知道差距有多大了
6. Shifted Windows Multi-Head Self-Attention(SW-MSA)
虽然基于窗口计算自注意力能够很好的解决计算量大的问题,但是现在窗口与窗口之间没有联系,就达不到全局建模的能力,所以作者就提出了移动窗口的方式去解决,如下图所示,左侧是基于窗口的自注意力,右侧是基于移动窗口的自注意力,它俩一般是成对使用的,构成一个Swin-Transformer Block ,这样就能达到窗口之间的通信
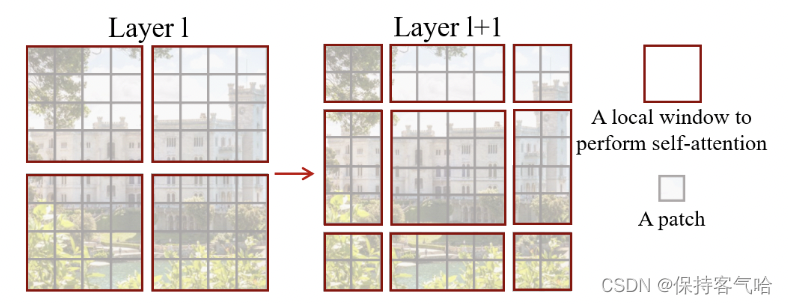
但是这种基于移动的多头自注意力窗口,在移动后变成了九个窗口,而且窗口之间的patch数量每个都不一样,这样就做不到把它们压成一个batch去进行计算,一个简单粗暴的方式就是补0,把它们填充成大小一样的窗口,再压成一个batch去计算,但是这样一来计算复杂度就大大加大了。那我们如何才能让移位后窗口还是四个,大小也一样呢?
作者在这里就提出来一个非常巧妙的掩码方式,当我们通过移动窗口得到九个窗口时,我们不在这九个窗口上进行计算,而是通过一次循环位移(cyclic shift)论文中的具体操作如下:
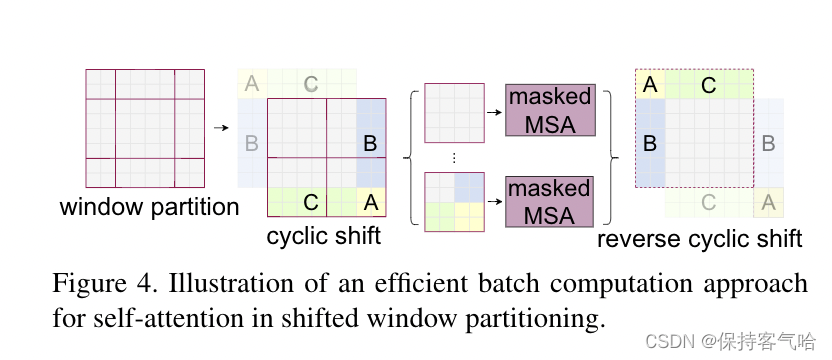
为了更好的理解可以参考下面的图:

最终的结果中,4是一个单独的窗口,5和3合成一个窗口,7和1合成一个窗口,8,6,2,0合成一个窗口,它们大小都一样(图中画的不标准),这样就是4个4*4大小的窗口了,所以能够保证计算量是一样的。但是这样又有一个问题,把不同区域汇合到一起,它们之间的元素都是从很远的地方搬运过来的,所以它们之间不应该作自注意力,不应该有太多的联系。(比如一张图的上面是天空,下面是土地,现在就是把部分天空移到了土地下面,再做自注意力就不太合适了),所以为了防止这个问题,实际计算中使用掩码操作(Masked MSA),这样就能使用蒙版来隔绝不同区域的信息了,算出自注意力之后再进行还原,否则破坏之前的语义信息,至于如何使用掩码操作参考下图:
以左下窗口为例:一共有7*7=49个patch,其实每个patch就是一个向量,
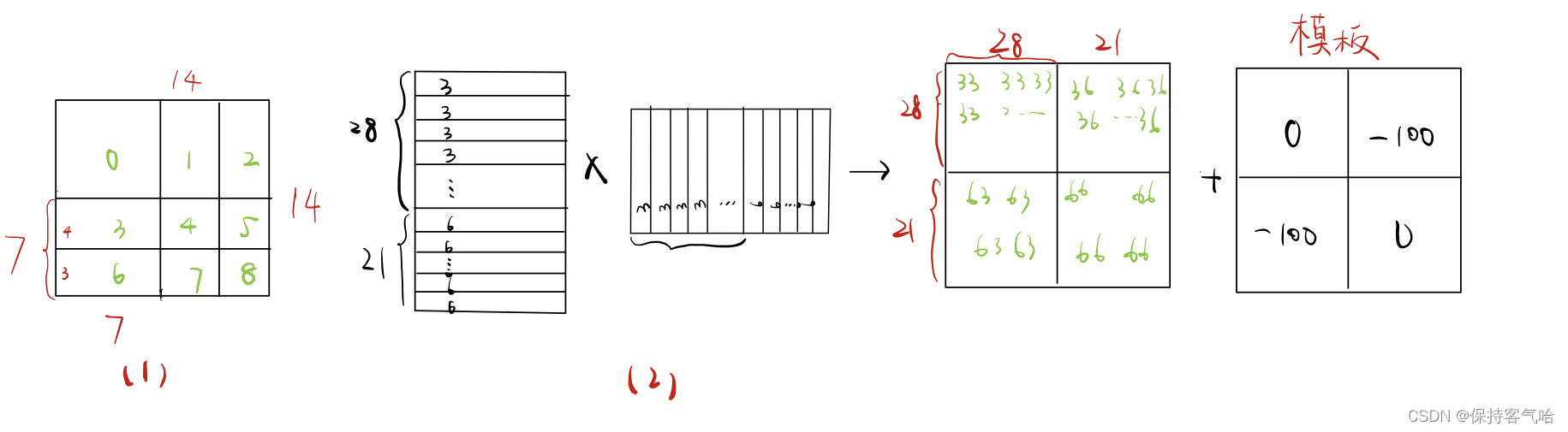
注意:
- 图(1)是经过循环位移之后的图,只有序号0是原来的窗口,其他都是拼接而得到的,所以需要用到掩码操作,图(2)是左下角3和6组成的窗口把对应的patch
从左到右,从上到下进行拉直得到的向量 - 因为移动窗口的时候是移动窗口的一半,在这里窗口大小是7,所以每次移动3(即6号窗口),3号窗口就是4,所以图(2)中的28=47,21=37
- 最后所得的结果中,33,66是来自同一窗口的,36,63是来自不同窗口的,它们之间是不应该作自注意力的,所以后面通过加上一个模板,在得到的自注意力结果中它们的值都是非常小的数,当加上一个很大的负数时,结果肯定也是负数,所以后面经过softmax就变成0过滤掉了;
7.Relative Position Bias
详情见博文:https://blog.csdn.net/qq_37541097/article/details/121119988