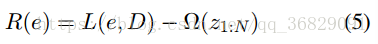Abstract
提出一种一般方法来分析神经网络的决策:清除一些部分的表示(various parts of the representation),例如输入的单词向量的维度(input word-vector dimensions)、中间隐藏单元(intermediate hidden units)、输入单词(input words),来看看这样会产生什么影响。
评估清除(erasure)影响的方法有:计算评价标准(evaluation metrics)的影响;使用强化学习(reinforcement learning),清除输入单词的最小集(the minimum set of input words),从而改变神经网络的决策。
我们对多种NLP任务的理解力分析(comprehensive analysis),比如
-
词汇级(lexical)的:word shape、morpgology
-
语句级(sentence-level)的:sentiment
-
文本级(document-level)的:sentiment aspect
发现提出的方法不仅提供了对神经模型决策的解释,也提供了对神经模型误差分析(error analysis)的方法
1 Introduction
在神经网络中有以下问题:
-
在输入层,单词向量的维度(word vector dimension)代表什么?
-
在中间层中的隐藏单元代表什么?
-
模型怎么把句子中不同部分的意思结合起来,并过滤信息?
-
输出层是怎么做出最终决策的?
这些问题使人难以分辨什么时候/为什么神经网络会出错。
为了翻译神经网络的行为,我们可以分析【清楚部分表示】后产生的影响,来看看什么样的改变影响了网络的决策。
我们可以直接计算清楚表示后,正确标签上的对数似然值。我们还提出了一种强化学习模型,来找到【为了改变模型决策而必须去掉的单词】。
提出的框架解释了以下几个方面:
-
神经网络怎么为语言特征分类器(linguistic feature classification)选择单词向量的维度。语言特征包括:词性(parts of speech,POS)、命名实体(named entity recognition,NER)、分块(chunking)。
-
神经网络在做情感分析(sentiment analysis)时,怎么选择和过滤重要单词、短语和句子。
-
为什么LSTM比RNN表现的更有竞争力。
2 Related Work
3 Linking Word Vector Dimensions to Linguistic Features
我们已经知道单词的向量表示能够编码像词性和语义这样的特征。我们的目标是发现神经网络怎么从单词向量维度中提取信息,从而对语言学特征(POS、NER、chunking、prefix、suffix、word-shape、word-frequency)做出分类。我们先训练一个对这些特征进行分类的分类器,然后再清除输入单词向量和中间层隐藏单元,来看看网络的决策。
3.1 Visualization Model
-
M 代表训练好的模型
-
代表训练样本,c是其正确的标签,Le是e的tag的索引
-
模型M给e的正确标签赋的对数似然值
-
d 代表一下目标向量的维度的索引
-
代表将维度d去掉后,模型M给e的正确标签赋的对数似然值
-
代表维度d的重要性,用
和
间的差别衡量
3.2 Tasks and Training
考虑两个任务
-
语句标记任务(sequence tagging tasks):POS、NER、chunking
-
单词本体分类任务(word ontological classification tasks):prefix、suffix、sentiment、word-shape、word-frequency
对于序列标记任务,输入由【单词到标记的向量表示】和它的【邻居表示】串联组成(窗口大小设置为5)。
对本体标记任务,输入就是输入单词的表示。
我们学习了word2vec和GloVe向量,每个50维向量都使用GigawordWiki语料库进行预训练。对每个任务,我们都训练了四层模型(1输入 词嵌入层,2中间层,1输出标量层),用TANH做激活函数,每个中间层有50个隐藏单元。训练准确率:

3.3 Results
对每个任务,我们都有一个预训练的模型(pre-trained model),然后把输入单词(input word)中的一个维度去掉(设为0),作为修改后的输入(modified input)放入预训练模型,并计算公式1,即清除维度的重要度。结果在Figure1中。

每一行对应一个特征分类任务(feature classification task),一行中的每一列代表单词向量维度对该任务的重要度。
-
对于word2Vec向量(Figure1a),发现模型更关注某些维度而不是其他维度,并且某些任务共享重要的维度。比如POS和chunking共享第34维;NER、prefix、suffix共享4和31维。在运用dropout时(Figure1b),我们可以清楚地看到,重要性在不同维度之间的分布更加均匀,因为在训练过程中,当主要维度dropout时,模型被迫使用其他维度。
-
对于GloVe向量,我们发现第31维几乎决定了所有任务(Figure1c)。当我们移除31维并重新训练模型时,又出现了第26维(Figure1d)。只有当31维、26维都被移除,模型才会将其注意力分散到其他维度(Figure1e)。另外,当移除这两维后,模型的表现并没有下降(可以从上面的Table7中看出)。使用dropout了以后,26和31维在许多任务上的影响力都剧烈下降,除了word-frequency,说明这两个维度与词频有关。Figure3显示了词频与26、31维具有很大相关性,说明GloVe模型依赖于这些词频,但是排除这些维数后,依然能从其它维数获取足够的信息。

-
Figure2说明了不同层的隐藏单元维度对POS任务的重要程度。可以看出高层的重要性平均地分散到各个维度上。换句话说,神经网络倾向于从输入层中的某些重要维度中提取信息,因此如果清除输入层的一些维度会造成很大危害。而到了higher layers,信息被分散到不同单元,重要程度也降低了,所以最终的分类觉得对于某些特定维度的修改更加鲁棒。

4 Finding Important Words in Sentiment Analysis
以上的部分主要关注单个向量维度,但是在许多NLP任务中,单词而非单个向量维度才是最基本的单元。这一部分我们基于Stanford Sentiment Treebank dataset,这个数据库与短语、句子级的分类有关。
我们可以计算单词的重要性,类似于单词向量维数,通过计算当一个特定单词被擦除时文本单元的正确情感标签的对数似然的相对变化。公式和
我们训练了三个模型:
-
用TANH作激活函数的标准RNN
-
Uni-LSTM
-
双向LSTM(Bi-LSTM)
我们先把数据集中的每个parse tree转化成token序列,每个序列对应一个短语/句子表示,并将其投入Softmax分类器。Bi-LSTM、Uni-LSTM、标准RNN分别得到0.526、0.501、0.453的准确率。
在Table3中,我们选择了几个有情感色彩的单词(sentiment-indicative),计算其重要程度。计算方法是找到包含某个单词(比如greatest)的所有测试样本,计算去掉改单词前后的对数似然值的不同,再对所有测试样本取平均。可以发现Bi-LSTM对这些情绪指标(sentiment indicator)比Uni-LSTM更敏感,而RNN则不敏感得多,这可能是因为LSTM中的门结构(gate structures)控制着信息的流向,让网络更关注情绪指标。

Table1中指出了最重要的10个单词:更完整的见Table8.

Figure4展示了对于不同模型,单词重要度的直方图。直方图也说明了Bi-LSTM对情绪指标更敏感,因为它对单词重要度的评分很高。

Figure5显示了一些样本中每个单词的重要程度,分值越高表明模型对该单词越敏感。可以看出,三个模型对情绪指标(如loved、entertainment、greatest)赋予更多重要性,并抑制了其它词。Figure5b表明LSTM还对感叹号赋予了重要性,而RNN则没有。

在Figure5中还可看出,一些单词的重要性是负值,说明去掉一些单词可以改善模型的决策。这些可以帮助进行误差分析,找出哪些单词影响了模型并导致了错误。
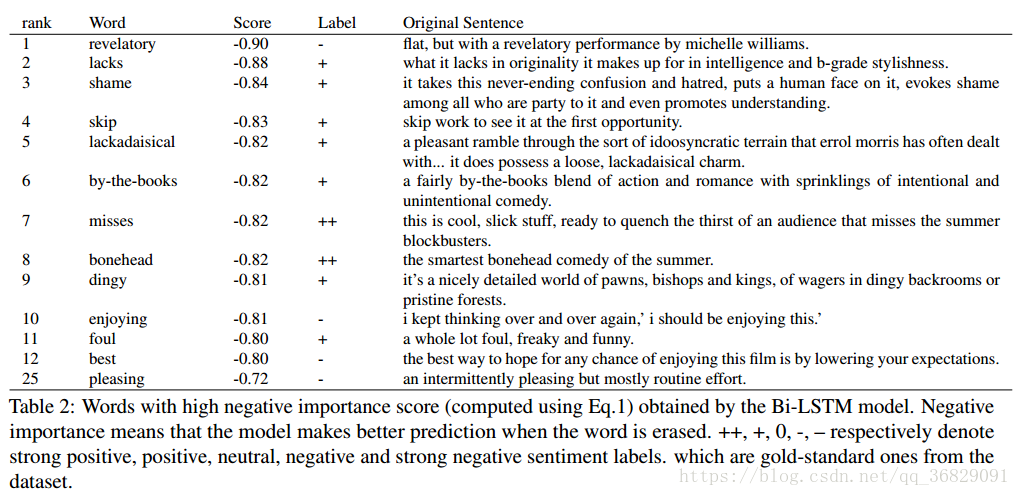
在Table2中我们列出了重要性负值最大的几个单词
在Table9、10、11中,我们列出了三个模型中重要性负值最大的几个单词。
从这些表格中,我们可以发现有一些模式可以使神经网络失败:
-
一个常见的情绪指示词被用在一个语境中(例如,描述电影的细节),使这个词不带有任何情绪导向,例如“happy ending”中的“happy”(Figure5e)或“shame”(Table2,rank3)。
-
情感指示词是在特定的语境中使用的,它将情感转化为与一般用法相反的词。例如,“the smartest bonehead”(Table2,rank8)
-
情绪指标用于非真实模式的范围,例如(Table2,rank10)。或者在讽刺的语境中,例如the best way to hope for any chance of enjoying this film is by lowering your expectations(Table 2, rank 12)。
-
在让步句中使用情感指标,需要对话语信息进行处理。例如,revelatory in flat, but with a revelatory performance by michelle williams(Table2,rank1);pleasing in an intermittently pleasing but mostly routine effort (Table2,rank25)。解决这些问题是今后情感分析工作的长期目标
5 Reinforcement Learning for Finding Decision-Changing Phrase
提出另一种方法,清除最少数量的单词来改变模型的预测。
-
e 代表一个【由单词序列组成的】输入文本单元:
-
N 代表e中的单词数
-
Le代表模型M给e打上的标签

任务是找到e的一个最小子集D,使得移除D中的所有单词(e-D)后,标签Le会发生改变。其中 |D| 代表D中单词的数量。整个问题可以描述为:
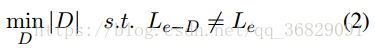
解决这个优化问题需要穷举所有可能的单词组合,这很困难,所以我们提出了强化学习方法来找到近似解。
我们对二元变量

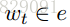

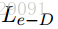
为了训练policy model,要设计一个reward function。如果标签改变,则policy model得到1的奖励,如

我们还添加了一个正则化器,它鼓励相同句子中单词z的相似值,以鼓励(或抑制)省略连续的短语:

其中S代表打破输入e后句子的集合。
所以最终的激励是