用K最近邻算法KNN对酒的类型进行预测。数据来源于sklearn的数据集。
导入数据集
from sklearn.datasets import load_wine
wine_data = load_wine()
wine_data.keys()
sklearn里面的datasets 里的每一个数据集都包含以下信息: data:特征数据,target:目标变量,target_names:目标变量的名称,DESCR:数据描述,feature_names:特征名称。
探索数据
wine_data['data'].shape

可以发现这个数据集 一共178个样本,13个特征变量。
print(wine_data['DESCR'])
划分数据集
from sklearn.model_selection import train_test_split
X_train,X_test,y_train,y_test = train_test_split(wine_data['data'],wine_data['target'],random_state=0)在train_test_split()里面的 wine_data['data'],wine_data['target']代表特征变量和目标变量;
也可以先赋值X=wine_data['data'],y=wine_data['target'],train_test_split(X,y,random_state=0);
random_state是随机种子,可以任意写一个数字。
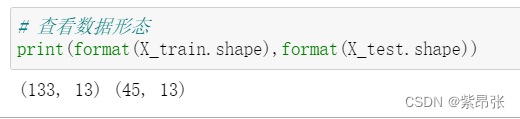
用shape方法可以看到训练集占75%,测试集25%。
建模&计算得分
# KNN分类模型
from sklearn.neighbors import KNeighborsClassifier
model_knn = KNeighborsClassifier()
model_knn.fit(X_train,y_train)format(model_knn.score(X_test,y_test))
模型准确率约73%,也就是对新酒做出预测是正确的概率为73%。