监督学习
监督学习输入的数据集中包含了预测结果,从给定的训练集中学习出一个函数(模型参数),当新的数据到来时,可以根据这个函数预测结果。
KNN属于监督学习
分类
- 分类是有监督的算法
- 分类的类别是已经预定义的,在分类之前知道这个数据集是有多少种类的
- 分类算法中,待分析的数据是一个一个处理的,分类的过程,就像给数据贴标签的过程
KNN(K近邻)算法
KNN是K-Nearest Neighbor的缩写,基本思想是以待分类样本点为中心,选取距离最近的K个点,这K个点中什么类别的占比最多,待分类样本点就属于什么类别。
在KNN算法中,将K值设置为多少没有具体的计算公式,只能根据实战经验确定了。
KNN分类算法的步骤:
- 找K个最近邻。KNN分类算法的核心就是找最近的K个点,选定度量距离的方法之后,以待分类样本点为中心,分别测量它到其他点的距离,找出其中的距离最近的“TOP K”,这就是K个最近邻
- 统计最近邻的类别占比。确定了最近邻之后,统计出每种类别在最近邻中的占比
- 选取占比最多的类别作为待分类样本的类别
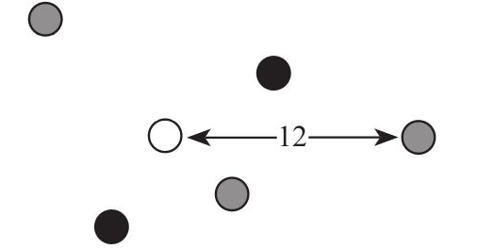
1. 假设已经有5个样本点,用颜色代表类别,现在放入一个新的待分类样本,由于类别不明,颜色用白色表示。

2. 首先逐一确定待分类样本点和训练集样本点的距离
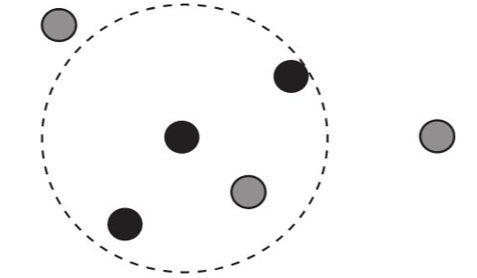
3. 在训练集样本点中找出与待分类样本点距离最近的K个点(K=3)

4. 决定待分类样本点的类别,由于黑色占大多数,所以待分类样本也为黑色
KNN算法实现
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.neighbors import KNeighborsClassifier
#导入pandas库、划分训练集和测试集方法、KNN分类算法
df=pd.read_excel("data.xlsx")
#读取数据表
X=df.drop(columns='y')
#X表示特征
y=df['y']
#y表示每条数据的标签
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2,random_state=42)
#将数据集按照8:2的比例划分训练集和测试集
knn = KNeighborsClassifier(n_neighbors=4)
#K设置为4
knn.fit(X_train, y_train)
#训练数据
knn.score(X_test,y_test)
#测试数据
data数据集部分截图
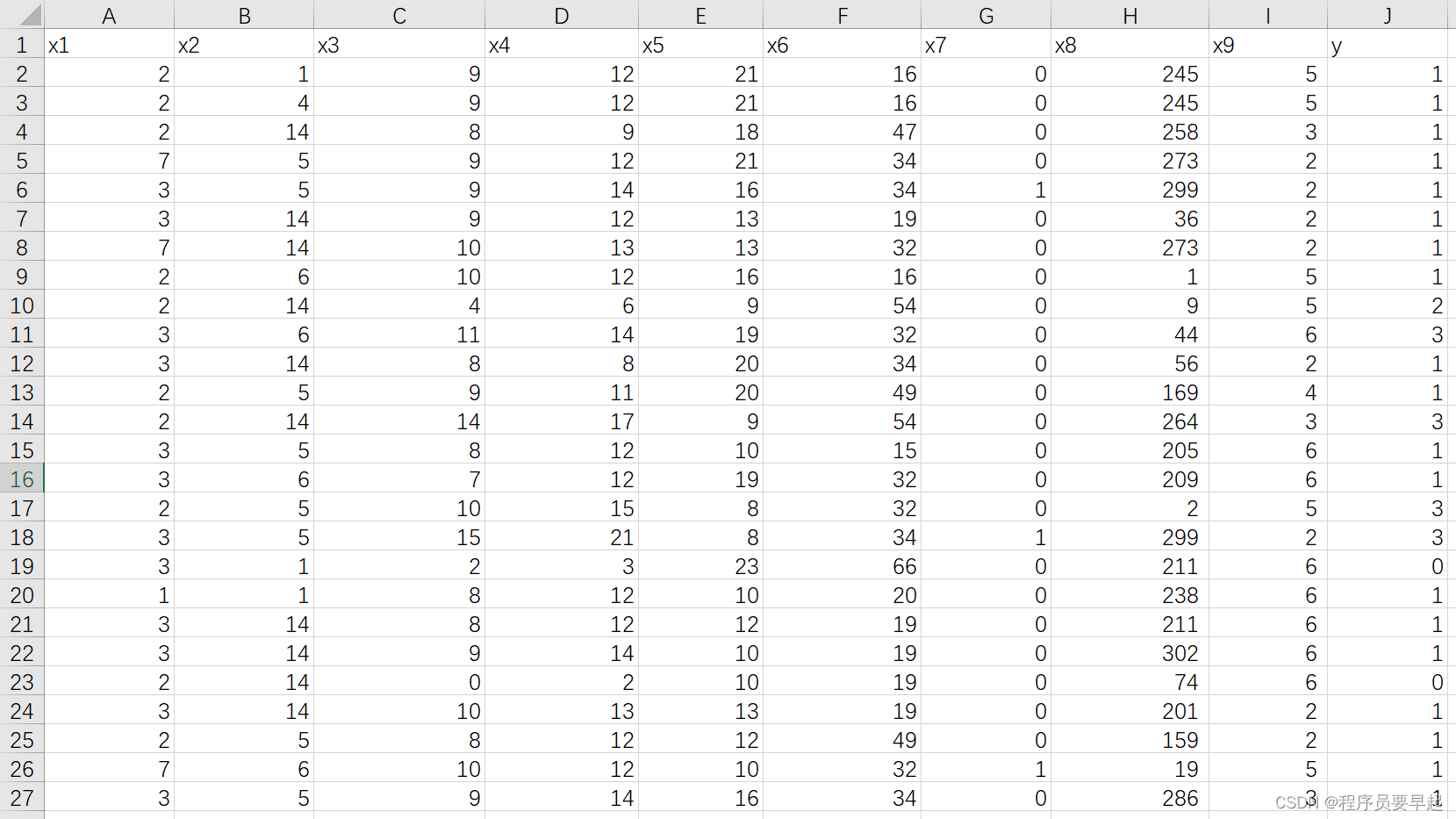
data数据集中有9个特征,2万多条数据,最后的实验结果为
0.9754958162720313