惰性学习法(或近邻分类)
前面提高的所有分类方法——决策树分类,贝叶斯分类,基于规则的分类,贝叶斯网络分类,神经网络分类,支持向量机分类和使用频繁模式的分类都是急切学习法的例子。
何为急切学习法呢?
回顾这些分类方法,都是在接受训练元组训练时期就已经构成了分类模型。
而与之对应的惰性学习法则是直到对给定的检验元组分类之前的一刻才构造“分类模型”。
大家要注意到我在这里对“分类模型”打上了引号,是因为这里说的“分类模型”不同于急切学习的那样。
也就是说,当给定一个训练元组时,惰性学习法只对它进行简单的处理并存储它,然后一直等待。直到给定一个检验元组,它才进行泛化,以便根据与存储的训练元组的相似性对该元组进行分类。
所以,惰性学习法的分类是以来与训练元组的相似性来判定的,因此这个分类模型不同于急切学习法的分类模型。
所以,对急切学习法在花费大量时间和精力在训练上,惰性学习法则是花费大量时间和精力在分类和数值预测上。这意味着,惰性学习法在实际使用的时候计算开销可能会很大。你可以把它理解为平时不好好学习(训练),到了考试才临阵磨枪(预测或分类)
KNN算法是惰性学习的典型例子
K-最近邻分类(KNN)
KNN算法是基于类比学习的,即通过将给定的检验元组和它相似的几个训练元组进行比较来学习。它可以用来分类和回归。由于这俩个都差不多,所以这里就选择分类来进行讲解。
直白的理解就是,当我们分析一个人时,我们不妨观察和它最亲密的几个人(所谓近朱者赤近墨者黑)。
回头看第一句话,我重点标注了“相似”和“几个”。实际上这两个就是KNN算法最核心的东西,即计算相似性和核定K值。
首先我们来看一个最最基本的实际例子(该例子参考了这篇文章)。
考虑一个电影分类的例子。
首先,我们准备电影分类的数据集。
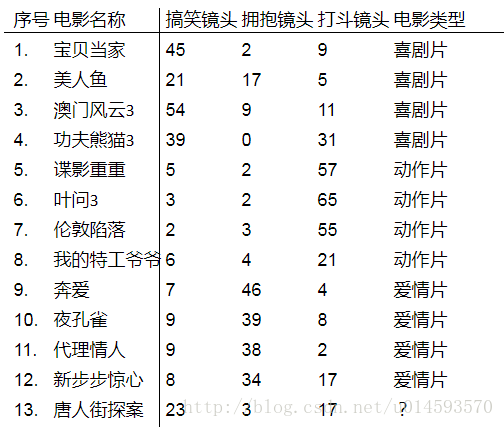
可以看到,这里有12个数据,其数据类别为喜剧片,动作片,爱情片三类。使用的特征值为搞笑镜头,拥抱镜头和打斗镜头数量。现在来了一部新电影《唐人街探案》,如果使用KNN来进行分类,该怎么做呢?
步骤如下:
1.首先构建一个已经分好类的数据集
"宝贝当家": [45, 2, 9, "喜剧片"],
"美人鱼": [21, 17, 5, "喜剧片"],
"澳门风云3": [54, 9, 11, "喜剧片"],
"功夫熊猫3": [39, 0, 31, "喜剧片"],
"谍影重重": [5, 2, 57, "动作片"],
"叶问3": [3, 2, 65, "动作片"],
"伦敦陷落": [2, 3, 55, "动作片"],
"我的特工爷爷": [6, 4, 21, "动作片"],
"奔爱": [7, 46, 4, "爱情片"],
"夜孔雀": [9, 39, 8, "爱情片"],
"代理情人": [9, 38, 2, "爱情片"],
"新步步惊心": [8, 34, 17, "爱情片"]} 2.计算新样本与数据集中所有样本的相似性
这里会涉及到数据的归一化(规范数据以方便计算)和相似性的计算
归一化的必要性后面再说。
计算数据之间的相似性我们在第二章的2.4节(P44)就已经详细介绍过了,包括使用的数据结构(数据矩阵和相异性矩阵),以及标称属性,数值属性的相似性计算都详解在那里,不清楚的同学翻回去看看。
这里我们选择最简单也是最常用的欧氏距离来依次计算新样本和数据集中所有样本的距离(相似性更确切的说是相异性),输出结果如下:
['谍影重重', 43.87]
['伦敦陷落', 43.42]
['澳门风云3', 32.14]
['叶问3', 52.01]
['我的特工爷爷', 17.49]
['新步步惊心', 34.44]
['宝贝当家', 23.43]
['功夫熊猫3', 21.47]
['奔爱', 47.69]
['美人鱼', 18.55]
['夜孔雀', 39.66]
['代理情人', 40.57]]3.按照距离大小(相似性)递增排序
['我的特工爷爷', 17.49]
['美人鱼', 18.55]
['功夫熊猫3', 21.47]
['宝贝当家', 23.43]
['澳门风云3', 32.14]
['新步步惊心', 34.44]
['夜孔雀', 39.66]
['代理情人', 40.57]
['伦敦陷落', 43.42]
['谍影重重', 43.87]
['奔爱', 47.69]
['叶问3', 52.01]] 4.选取距离最小的K个样本
因为欧式距离反应的是相异性,所以距离越小,则越相似。
这里取K=5
['我的特工爷爷', 17.49]
['美人鱼', 18.55]
['功夫熊猫3', 21.47]
['宝贝当家', 23.43]
['澳门风云3', 32.14]]5.确定这K个样本所在类别出现的频率,并输出频率最高的类别
因为KNN之前并不会在训练集中形成分类模型且是基于类比学习。因此,在拿到前K个数据之后,需要对这个K个数据所在的样本,计算它们的出现频率,从而得到出现频率最高的类别
('喜剧片', 4)
('动作片', 1)
('爱情片', 0)
输出“喜剧片”所以最后把《唐人街》探案归类为喜剧片。
OK,这就是最最基本的KNN的一套流程。
其中,值得特别关注的有两点。
一是K值到底取多大,二是数据归一化。
1选取k值及它的影响?(此处参考了这篇文章)
如果我们选取较小的k值,那么就会意味着我们的整体模型会变得复杂,容易发生过拟合
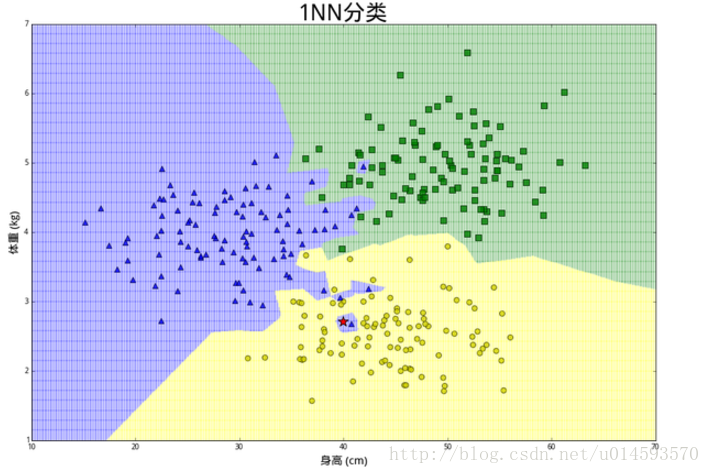
假设K=1,且有训练数据和待分类点如下图:
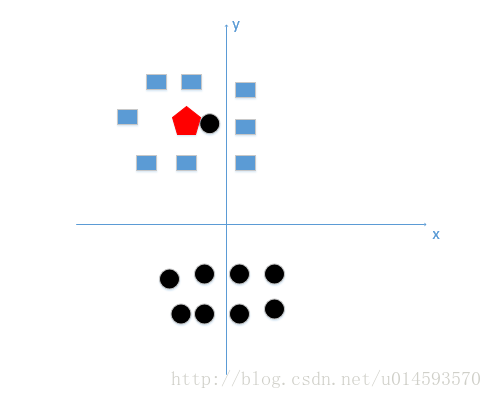
上图中有俩类,一个是黑色的圆点,一个是蓝色的长方形,现在我们的待分类点是红色的五边形。
好,根据我们的k近邻算法步骤来决定待分类点应该归为哪一类。我们由图中可以得到,很容易我们能够看出来五边形离黑色的圆点最近,k又等于1,那太好了,我们最终判定待分类点是黑色的圆点。
由这个处理过程我们很容易能够感觉出问题了,如果k太小了,比如等于1,那么模型就太复杂了,我们很容易学习到噪声,也就非常容易判定为噪声类别,而在上图,如果,k大一点,k等于8,把长方形都包括进来,我们很容易得到我们正确的分类应该是蓝色的长方形!如下图:
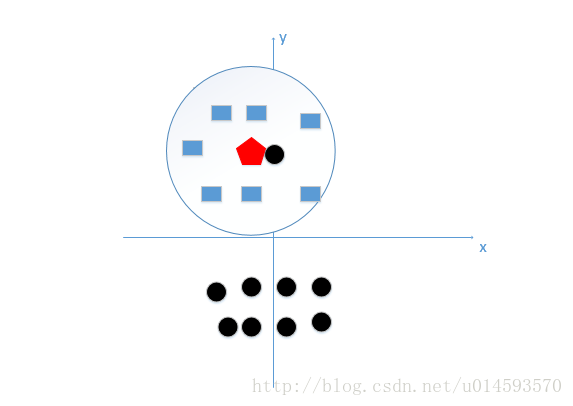
所谓的过拟合就是在训练集上准确率非常高,而在测试集上准确率低,经过上例,我们可以得到k太小会导致过拟合,很容易将一些噪声(如上图离五边形很近的黑色圆点)学习到模型中,而忽略了数据真实的分布!
看下面这两张图看得更明显。
如果我们选取较大的k值,就相当于用较大邻域中的训练数据进行预测,这时与输入实例较远的(不相似)训练实例也会对预测起作用,使预测发生错误,k值的增大意味着整体模型变得简单。
举个例子,如果k=N(N为训练样本的个数),那么无论输入实例是什么,都将简单地预测它属于在训练实例中最多的类。这时,模型是不是非常简单,这相当于你压根就没有训练模型呀!直接拿训练数据统计了一下各个数据的类别,找最大的而已!这好像下图所示:
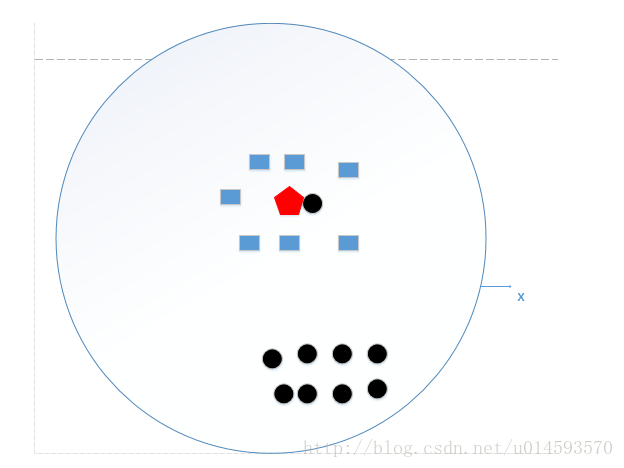
我们统计了黑色圆形是8个,长方形个数是7个,那么如果k=N,我就得出结论了,红色五边形是属于黑色圆形的(明显是错误的!)
这个时候,模型过于简单,完全忽略训练数据实例中的大量有用信息,是不可取的。
恩,k值既不能过大,也不能过小,在我举的这个例子中,我们k值的选择,在下图红色圆边界之间这个范围是最好的,如下图:
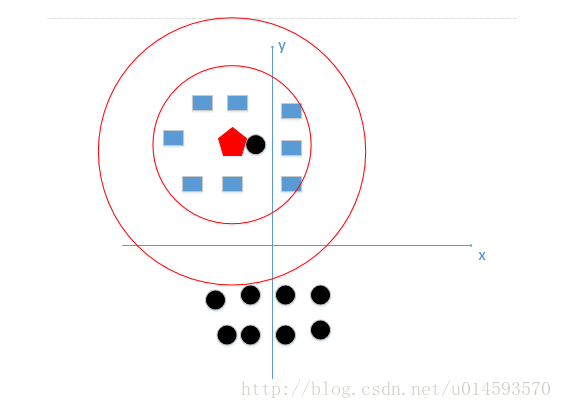
(注:这里只是为了更好让大家理解,真实例子中不可能只有俩维特征,但是原理是一样的1,我们就是想找到较好的k值大小)
那么我们一般怎么选取呢?李航博士书上讲到,我们一般选取一个较小的数值,通常采取 交叉验证法来选取最优的k值。(也就是说,选取k值很重要的关键是实验调参,类似于神经网络选取多少层这种,通过调整超参数来得到一个较好的结果)
2.特征归一化的必要性
首先举例如下,我用一个人身高(cm)与脚码(尺码)大小来作为特征值,类别为男性或者女性。我们现在如果有5个训练样本,分布如下:
A [(179,42),男] B [(178,43),男] C [(165,36)女] D [(177,42),男] E [(160,35),女]
通过上述训练样本,我们看出问题了吗?
很容易看到第一维身高特征是第二维脚码特征的4倍左右,那么在进行距离度量的时候,我们就会偏向于第一维特征。这样造成俩个特征并不是等价重要的,最终可能会导致距离计算错误,从而导致预测错误。口说无凭,举例如下:
现在我来了一个测试样本 F(167,43),让我们来预测他是男性还是女性,我们采取k=3来预测。
下面我们用欧式距离分别算出F离训练样本的欧式距离,然后选取最近的3个,多数类别就是我们最终的结果,计算如下:
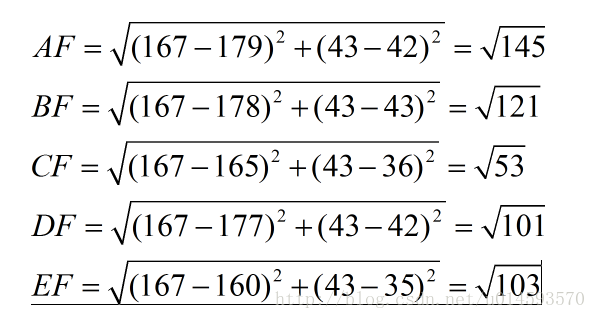
由计算可以得到,最近的前三个分别是C,D,E三个样本,那么由C,E为女性,D为男性,女性多于男性得到我们要预测的结果为女性。
这样问题就来了,一个女性的脚43码的可能性,远远小于男性脚43码的可能性,那么为什么算法还是会预测F为女性呢?那是因为由于各个特征量纲的不同,在这里导致了身高的重要性已经远远大于脚码了,这是不客观的。所以我们应该让每个特征都是同等重要的!这也是我们要归一化的原因!归一化公式如下:

KNN算法小结
KNN算法是很基本的机器学习算法了,它非常容易学习,在维度很高的时候也有很好的分类效率,因此运用也很广泛,这里总结下KNN的优缺点。
KNN的主要优点有:
1) 理论成熟,思想简单,既可以用来做分类也可以用来做回归
2) 可用于非线性分类
3) 训练时间复杂度比支持向量机之类的算法低,仅为O(n)
4) 和朴素贝叶斯之类的算法比,对数据没有假设,准确度高,对异常点不敏感
5) 由于KNN方法主要靠周围有限的邻近的样本,而不是靠判别类域的方法来确定所属类别的,因此对于类域的交叉或重叠较多的待分样本集来说,KNN方法较其他方法更为适合
6)该算法比较适用于样本容量比较大的类域的自动分类,而那些样本容量较小的类域采用这种算法比较容易产生误分
7)适合对稀有事件进行分类
8)特别适合于多分类问题(multi-modal,对象具有多个类别标签),例如根据基因特征来判断其功能分类,kNN比SVM的表现要好
KNN的主要缺点有:
1)计算量大,尤其是特征数非常多的时候
2)样本不平衡的时候,对稀有类别的预测准确率低
3)KD树,球树之类的模型建立需要大量的内存
4)使用懒散学习方法,基本上不学习,导致预测时速度比起逻辑回归之类的算法慢
5)相比决策树模型,KNN模型可解释性不强
参考文章
KNN算法理解
【数学】一只兔子帮你理解 kNN
【量化课堂】kd 树算法之思路篇
一文搞懂k近邻(k-NN)算法(一)
一文搞懂k近邻(k-NN)算法(二)