VL任务及数据集
Image Retrieval(图像检索)

基本模型结构:

Grounding Referring Expression(在图像中找到自然语言对应描述的物体)

基本模型结构:
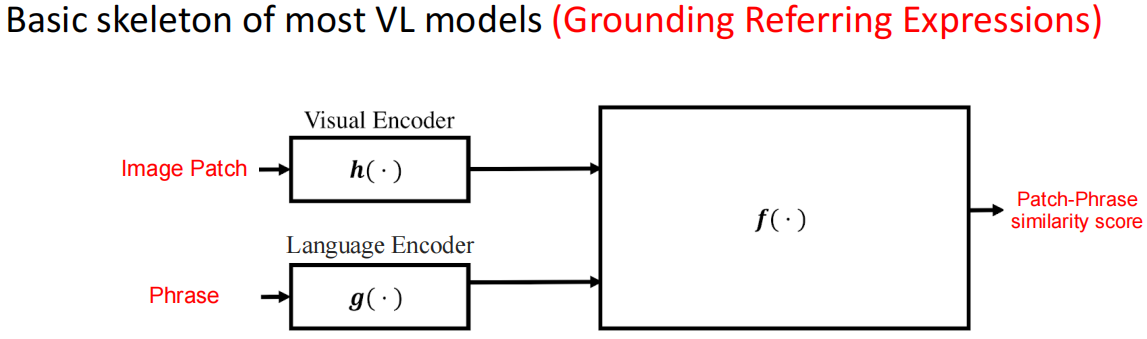
Image Captioning(图像描述)

基本模型结构:

数据集: COCO
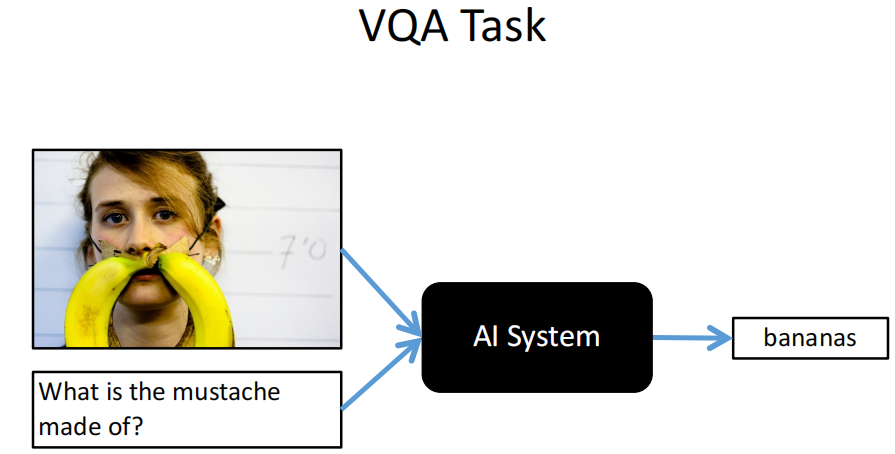
Visual Question Answering(VQA,视觉问答)

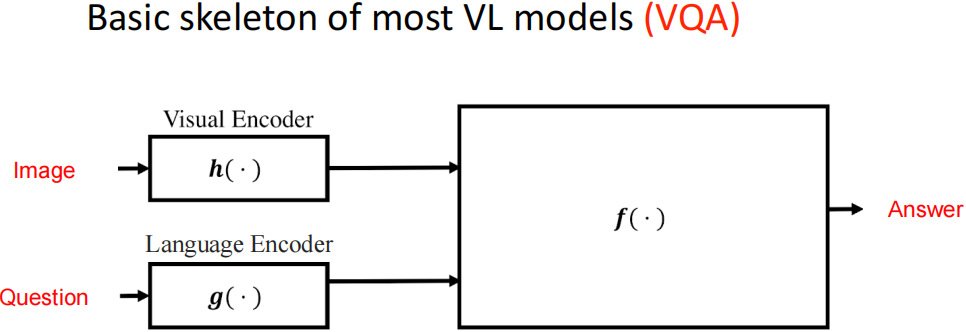
基本模型结构:
两通道 VQA 模型:

数据集: VQA v1, VQA v2, Visual Genome, GQA
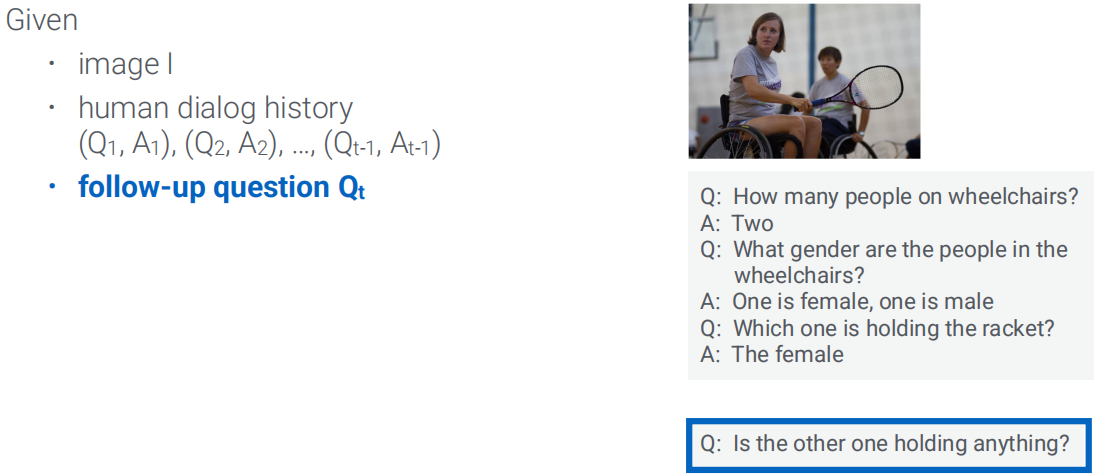
Visual Dialog(VD,视觉对话)



基本模型结构:
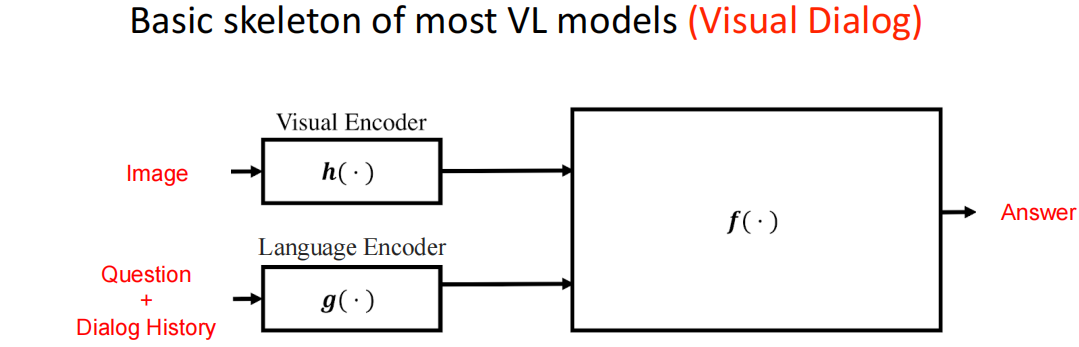
数据集: Visual Dialog, GuessWhat?!
demo
ViLBERT: https://vilbert.cloudcv.org/
本文参考于 ACL 2022 tutorial:Vision-Language Pretraining: Current Trends and the Future