目录
一、模糊数学
- 利用模糊集及其运算研究,处理模糊不确定现象和关系的数学分支学科。
- 模糊集和模糊综合评价
1.模糊集
“亦此亦彼”的模糊性,排中律破损造成的。
定义
设给定论域U,所谓U上的一个模糊集A是指对于任意,都能确定一个正数
用其表示
属于
的程度。映射
称为的隶属函数,函数值
称为
对
的隶属度
- 每个元素都有隶属度的集合即为模糊集,确定模糊集的关键是构造隶属函数
2.模糊集的运算
通过隶属函数完成
设模糊集A,B的隶属函数为,则A与B的常用运算有:
- 包含:
- 相等:
- 交:
- 补:
- 内积:
- 外积:
3.常用模糊分布
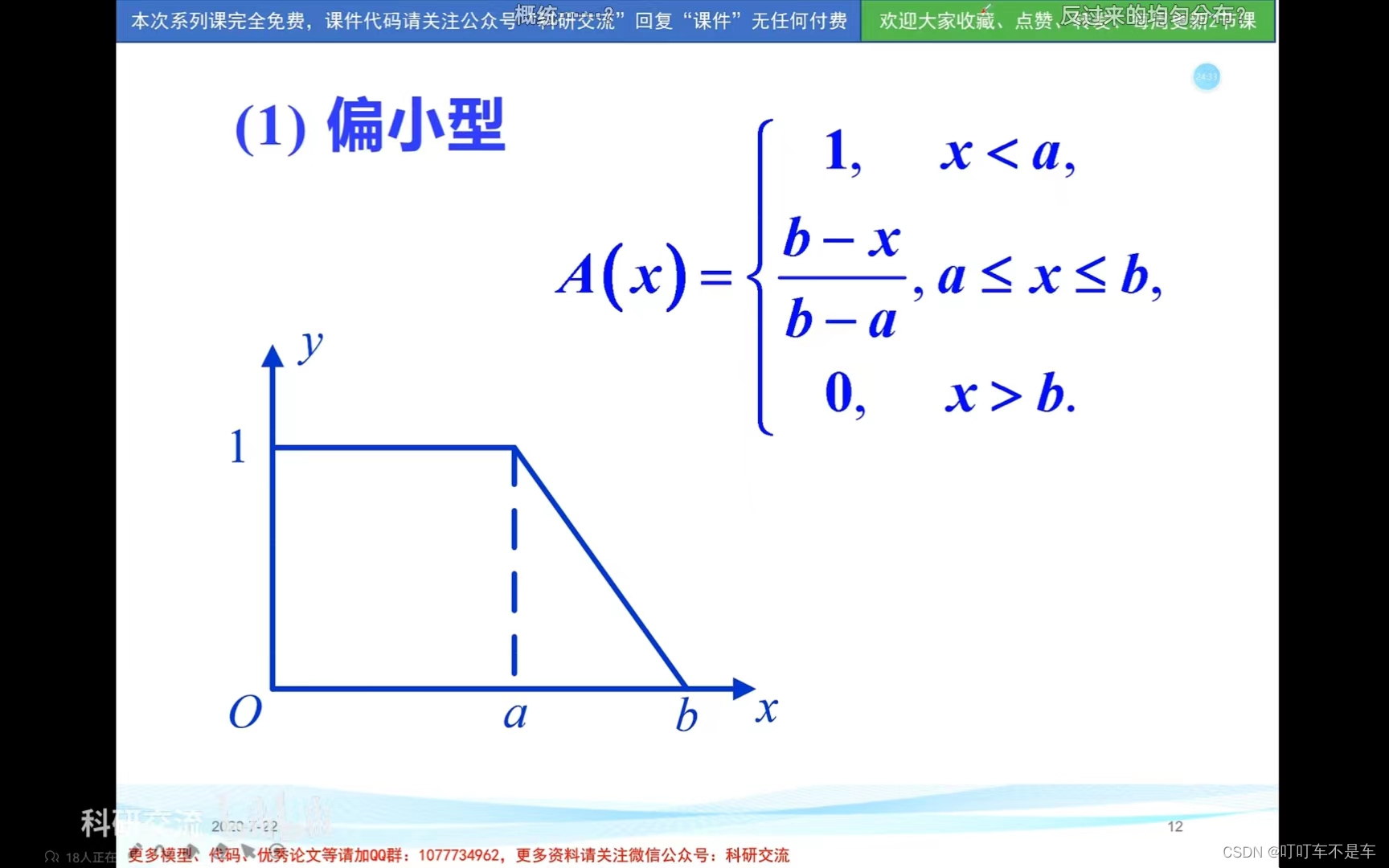

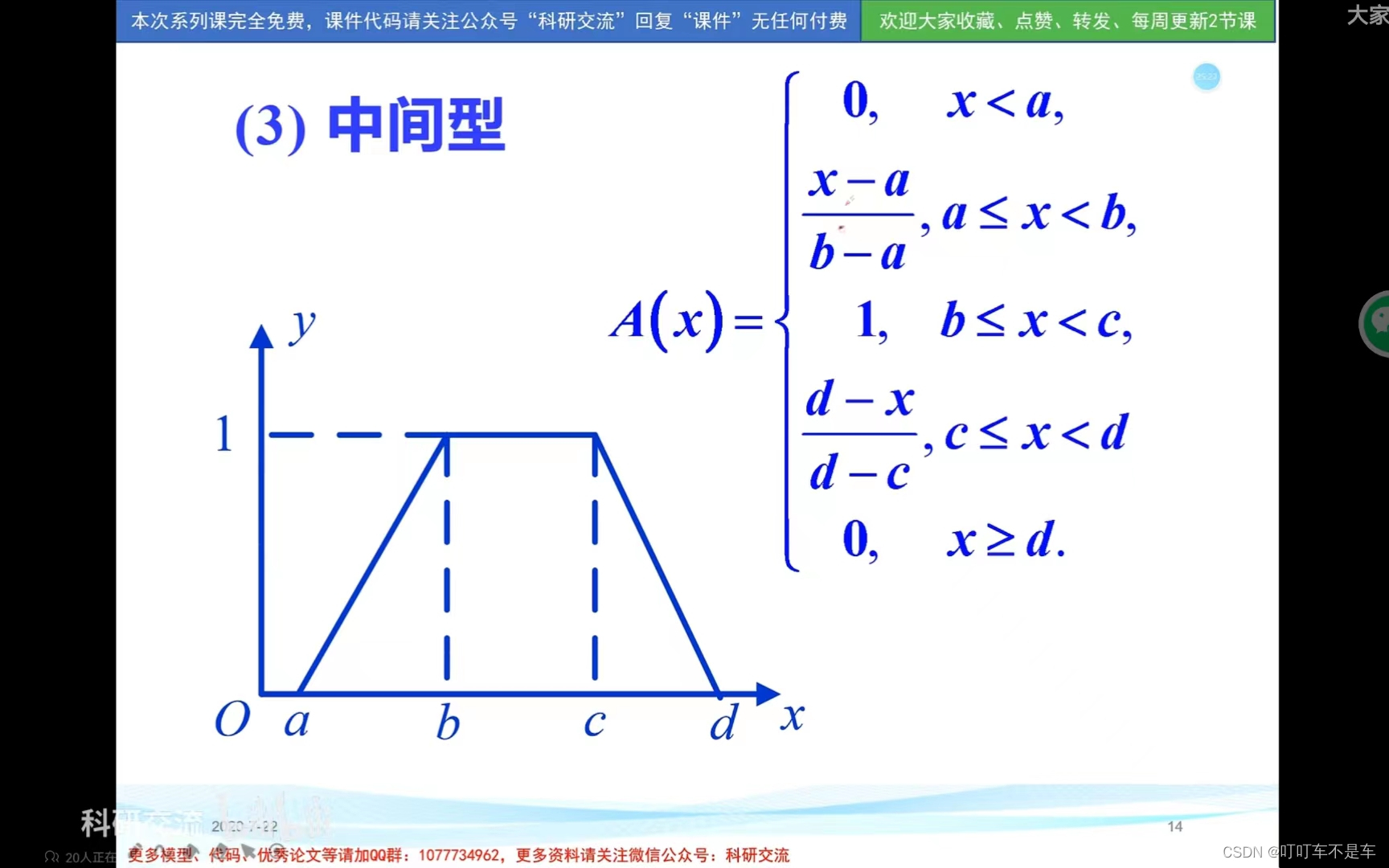
二、模糊综合评价
- 以模糊数学为基础,应用模糊关系合成原理,将一些边界不清、不易定量的因素定量化。
- 首先确定被评价对象的因素集和评价集,然后再分别确定各因素的权重及其隶属度向量,获得模糊评价矩阵(一般难以取得),最终将模糊评价矩阵与因素的权向量进行模糊运算并归一化,得到综合评价结果。
1.确定评价指标和评价等级
设为刻画被评价对象的m种因素,即评价指标;m为评价因素的个数
为刻画每一因素所在状态的n种评语,即为评价等级。n为评语的个数(等级
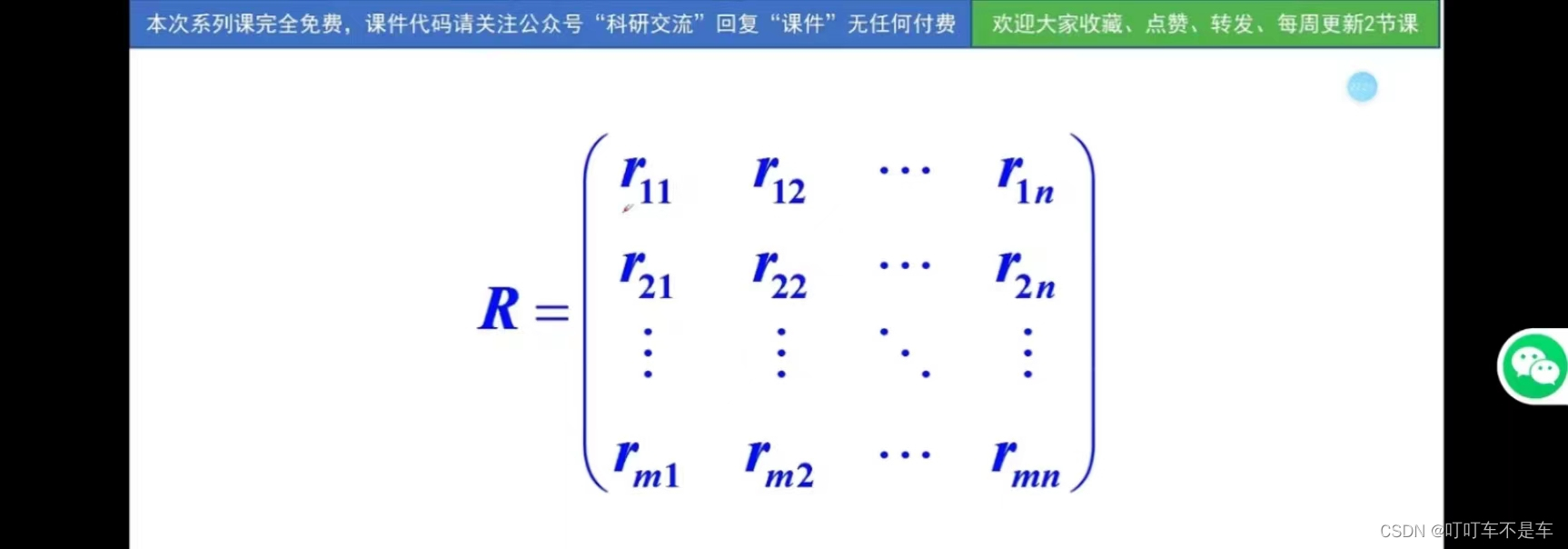
2.构造模糊综合评价矩阵
对每个评价指标逐一进行模糊评价。
方法
对评价指标给出其能被评为等级
的隶属度
。
可理解为指标
对于等级
的隶属度,通常要将
归一化以便使用。

每一行从左向右分别代表 对于不同评价等级(
)的隶属度(指数),每一行相加一定等于1
(eg,代表花色,
代表受欢迎比例,
代表一般的比例,
代表不受欢迎的比例)
3.评价指标权重的确定
引入模糊向量 来表示各评价指标在目标中所占权重,称之为权重向量。其中
为
的权重。(用层次分析法得到各个指标的权重
)
变异系数法 得到权重向量A
使用前提是重要性相当
若某项指标数值差异较大(方差大),能区分开各评价对象,应该给该指标较大的权重。
➡️可以用方差定义指标的权重
定义指标的分辨能力为:
(标准差/均值)

(2)令 ,归一化的
为各指标的权重,即
4.模糊合成与综合评价
对评价矩阵R和权向量A进行某种适当的模糊运算,将两者合成为一个模糊向 ,即B=AR,然后对B按照一定的法则进行综合分析后即可得出最终的模糊综合评价结果。



主因素突出型适用于模糊矩阵中数据相差悬殊的情形;加权平均型适用于因素很多且因素差距不大的情形
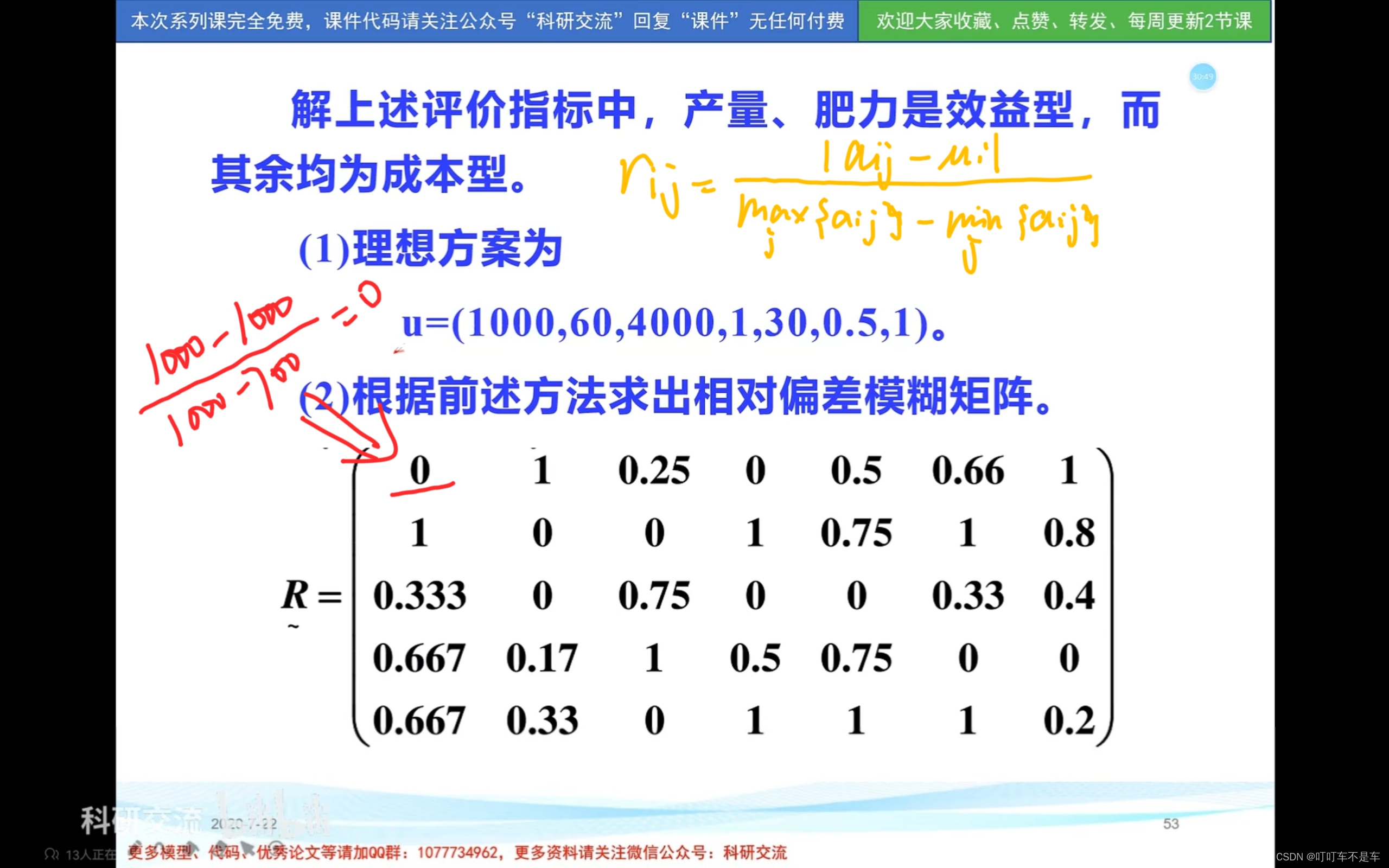
相对偏差法 得到模糊矩阵R
首先模拟一个理想方案u,然后按照某种方法建立各方案与u的偏差矩阵R,再确定各评价指标的权重A,最后用A对R加权平均得到方案与u的综合距离F,根据F对方案排序。
- 效益型指标越高越好;成本型指标越低越好
每行代表每一个指标,每列代表每个评价集




eg:


相对优属度 得到模糊矩阵R
将所有指标全部转化为效益性,得到优属度矩阵R

