文章目录
一、提出任务
- 分组求TopN是大数据领域常见的需求,主要是根据数据的某一列进行分组,然后将分组后的每一组数据按照指定的列进行排序,最后取每一组的前N行数据。
- 准备一组数据
张益达 85
李炫迈 91
王绿箭 79
张益达 87
李炫迈 90
张益达 89
李炫迈 91
王绿箭 90
李炫迈 95
王绿箭 79
张益达 78
李炫迈 92
李炫迈 85
王绿箭 88
李炫迈 82
-
在 /home目录下创建 grades.txt 写入上方数据
-
将 grades.txt 上传到HDFS的 /input目录下

-
启动HDFS和Spark
二、完成任务
(一)新建Maven项目
(二)完成项目
- 修改pom.xml内容
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0
http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>net.huawei.rdd</groupId>
<artifactId>GradeTopN</artifactId>
<version>1.0-SNAPSHOT</version>
<dependencies>
<dependency>
<groupId>org.scala-lang</groupId>
<artifactId>scala-library</artifactId>
<version>2.11.12</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.11</artifactId>
<version>2.1.1</version>
</dependency>
</dependencies>
<build>
<sourceDirectory>src/main/scala</sourceDirectory>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-assembly-plugin</artifactId>
<version>3.3.0</version>
<configuration>
<descriptorRefs>
<descriptorRef>jar-with-dependencies</descriptorRef>
</descriptorRefs>
</configuration>
<executions>
<execution>
<id>make-assembly</id>
<phase>package</phase>
<goals>
<goal>single</goal>
</goals>
</execution>
</executions>
</plugin>
<plugin>
<groupId>net.alchim31.maven</groupId>
<artifactId>scala-maven-plugin</artifactId>
<version>3.3.2</version>
<executions>
<execution>
<id>scala-compile-first</id>
<phase>process-resources</phase>
<goals>
<goal>add-source</goal>
<goal>compile</goal>
</goals>
</execution>
<execution>
<id>scala-test-compile</id>
<phase>process-test-resources</phase>
<goals>
<goal>testCompile</goal>
</goals>
</execution>
</executions>
</plugin>
</plugins>
</build>
</project>
- 将main.java 改为main.scala
- 创建日志属性文件 log4j.properties
内容如下:
log4j.rootLogger=ERROR, stdout, logfile
log4j.appender.stdout=org.apache.log4j.ConsoleAppender
log4j.appender.stdout.layout=org.apache.log4j.PatternLayout
log4j.appender.stdout.layout.ConversionPattern=%d %p [%c] - %m%n
log4j.appender.logfile=org.apache.log4j.FileAppender
log4j.appender.logfile.File=target/spark.log
log4j.appender.logfile.layout=org.apache.log4j.PatternLayout
log4j.appender.logfile.layout.ConversionPattern=%d %p [%c] - %m%n
- 在scala目录下创建net.xxx.rdd包
- 在net.xxx.rdd包里创建GradeTopN.scala
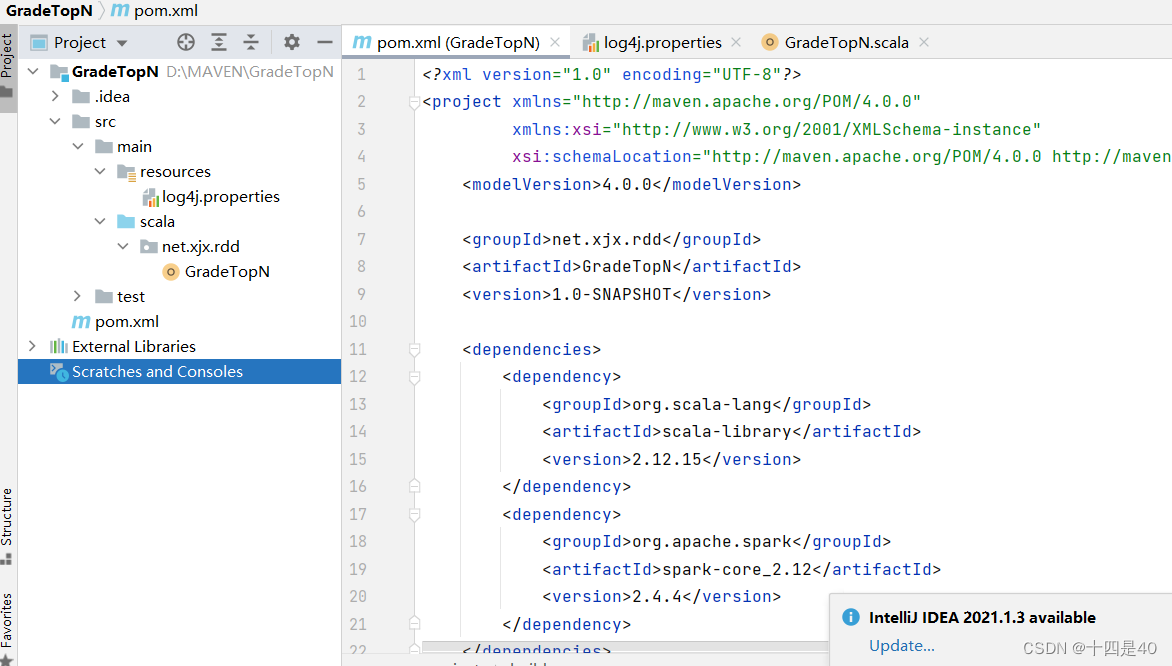
- GradesTopN 内容
(三)运行
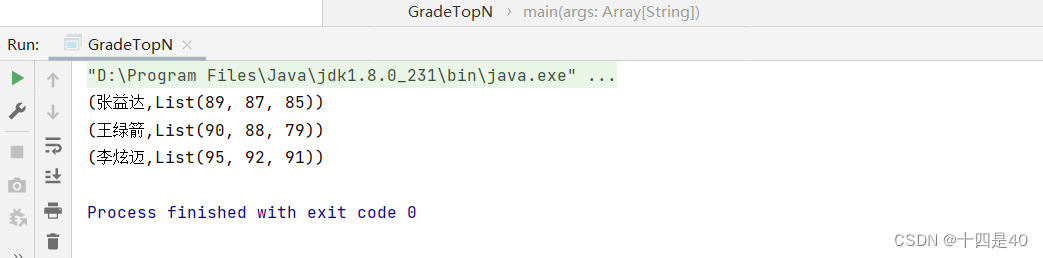
- 运行结果
- 修改方法,使输出结果更美观
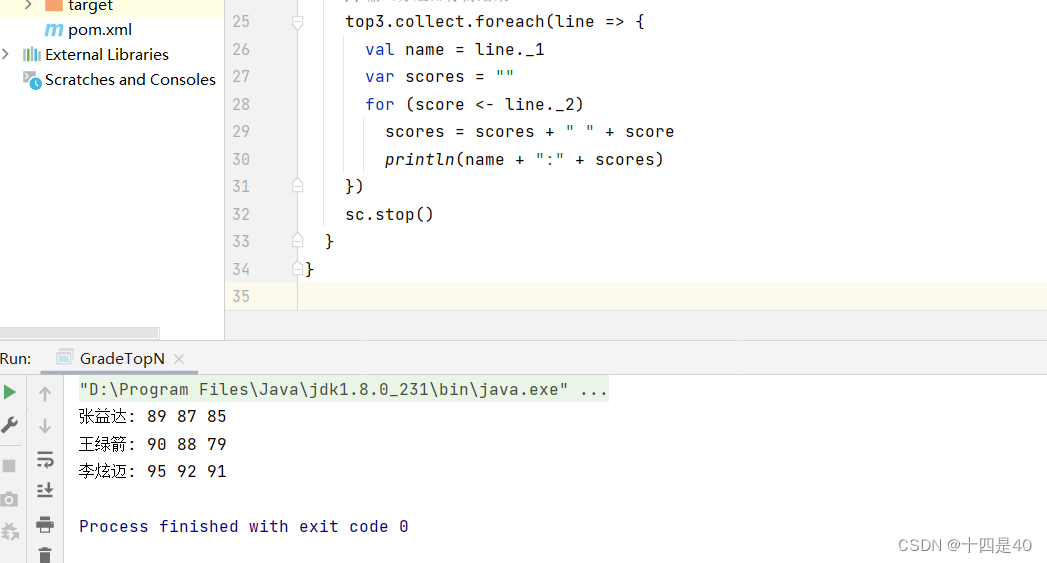
(四)交互式操作查看中间结果
- 启动scala
- 命令:spark-shell --master spark://master:7077
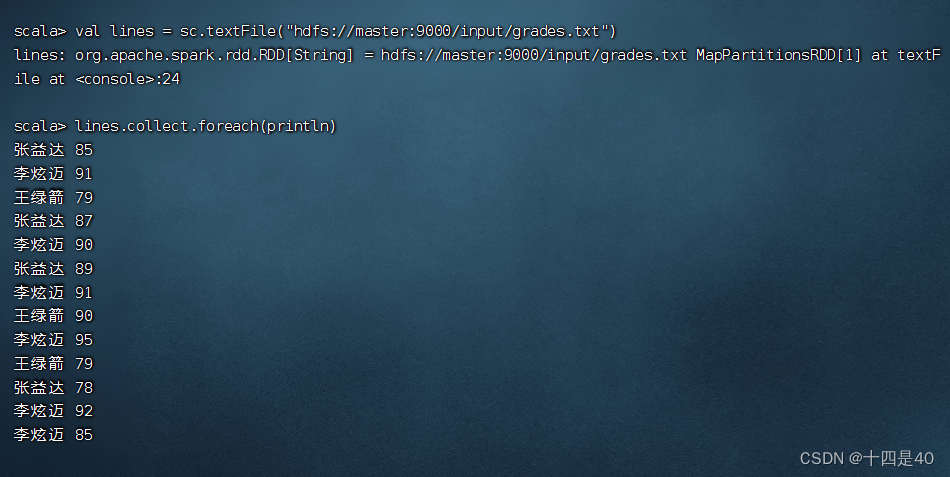
1、读取成绩文件得到RDD
- 执行命令:val lines = sc.textFile(“hdfs://master:9000/input/grades.txt”)
2、利用映射算子生成二元组构成的RDD
进入 :paste模式
执行如下代码:
val grades = lines.map(line => {
val fields = line.split(" ")
(fields(0), fields(1))
})

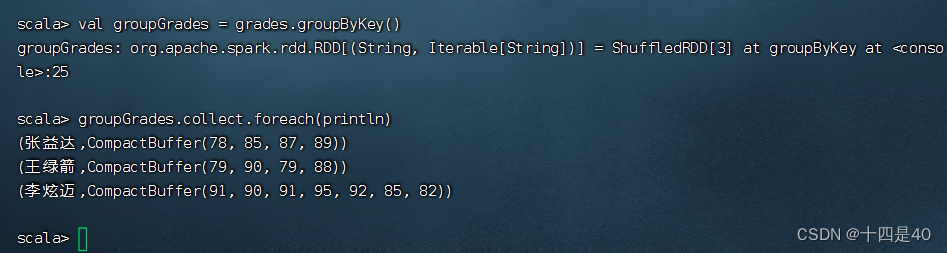
3、按键分组得到新的二元组构成的RDD
执行命令:val groupGrades = grades.groupByKey()
4、按值排序,取前三
- 执行如下代码:
val top3 = groupGrades.map(item => {
val name = item._1
val top3 = item._2.toList.sortWith(_ > _).take(3)
(name, top3)
})

5、按指定格式输出结果
- 进入 :paste模式
- 执行如下代码
top3.collect.foreach(line => {
val name = line._1
var scores = ""
for (score <- line._2)
scores = scores + " " + score
println(name + ":" + scores)
})
