文章目录
一,提出任务
分组求TopN是大数据领域常见的需求,主要是根据数据的某一列进行分组,然后将分组后的每一组数据按照指定的列进行排序,最后取每一组的前N行数据。
有一组学生成绩数据
张三丰 90
李孟达 85
张三丰 87
王晓云 93
李孟达 65
张三丰 76
王晓云 78
李孟达 60
张三丰 94
王晓云 97
李孟达 88
张三丰 80
王晓云 88
李孟达 82
王晓云 98
同一个学生有多门成绩,现需要计算每个学生分数最高的前3个成绩,期望输出结果如下所示
张三丰:94 90 87
李孟达:88 85 82
王晓云:98 97 93
二,实现思路
使用Spark RDD的groupByKey()算子可以对(key, value)形式的RDD按照key进行分组,key相同的元素的value将聚合到一起,形成(key, value-list),将value-list中的元素降序排列取前N个即可。
三,准备工作
1、在本地创建成绩文件
在/home目录里创建grades.txt文件
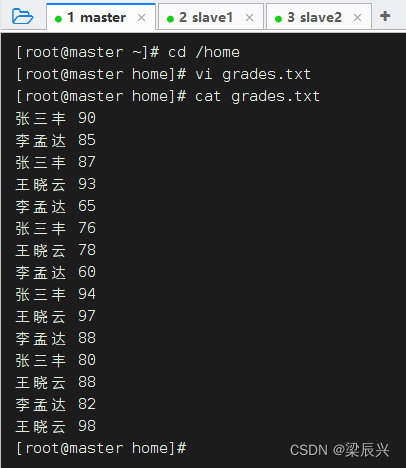
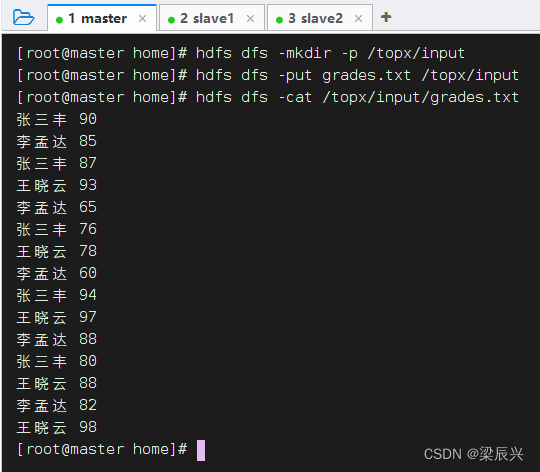
2、将成绩文件上传到HDFS上指定目录
将grades.txt上传到HDFS的/topx/input目录
四,完成任务
1、在Spark Shell里完成任务
(1)读取成绩文件得到RDD
执行命令:val lines = sc.textFile("hdfs://master:9000/topx/input/grades.txt")
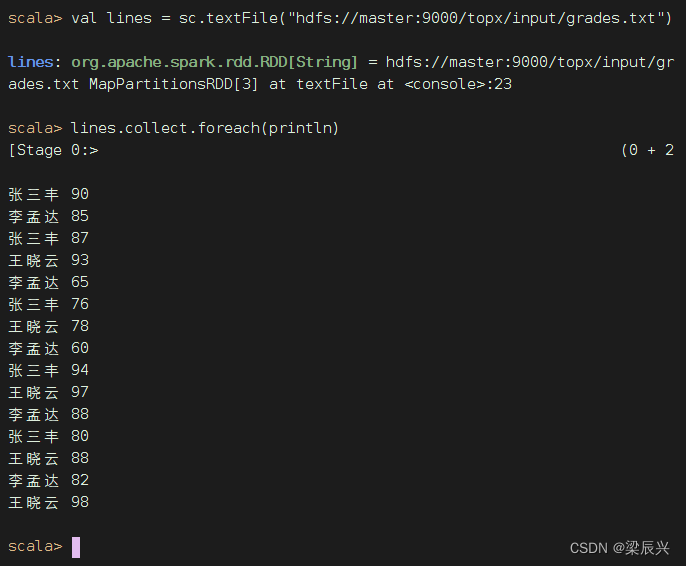
(2)利用映射算子生成二元组构成的RDD
val grades = lines.map(line => {
val fields = line.split(" ")
(fields(0), fields(1))
}
)
grades.collect.foreach(println)
执行上述代码
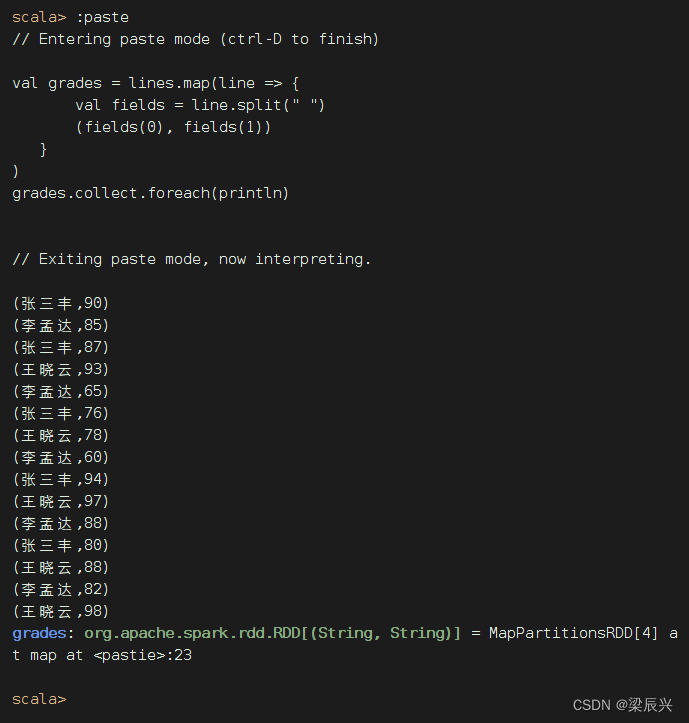
(3)按键分组得到新的二元组构成的RDD
执行命令:val groupGrades = grades.groupByKey()
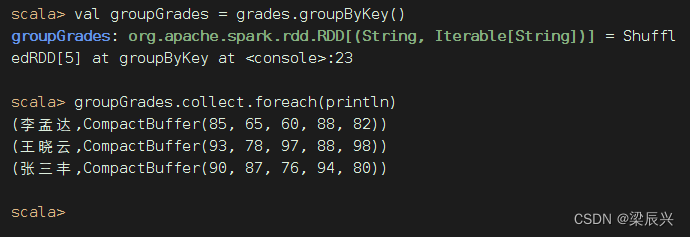
(4)按值排序,取前三
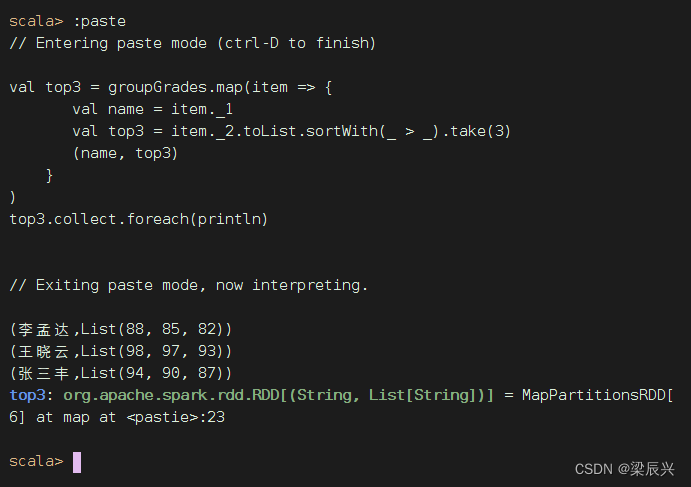
val top3 = groupGrades.map(item => {
val name = item._1
val top3 = item._2.toList.sortWith(_ > _).take(3)
(name, top3)
}
)
top3.collect.foreach(println)
执行上述代码
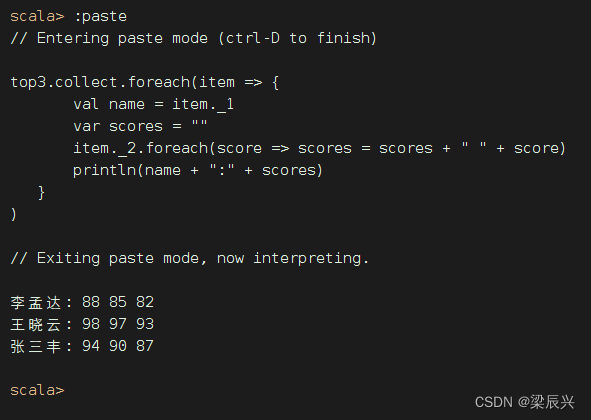
(5)按指定格式输出结果
top3.collect.foreach(item => {
val name = item._1
var scores = ""
item._2.foreach(score => scores = scores + " " + score)
println(name + ":" + scores)
}
)
执行上述代码
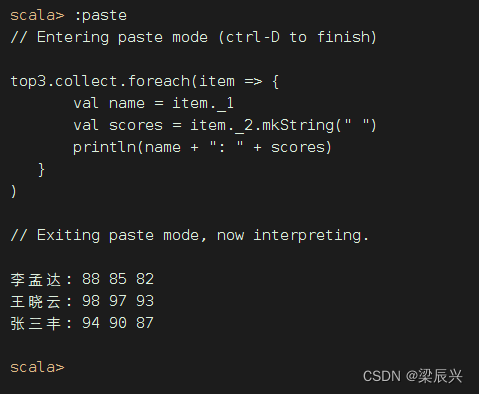
其实,代码可以优化
top3.collect.foreach(item => {
val name = item._1
val scores = item._2.mkString(" ")
println(name + ": " + scores)
}
)
执行代码,查看结果
2、在IntelliJ IDEA里完成任务
(1)打开RDD项目
SparkRDDDemo
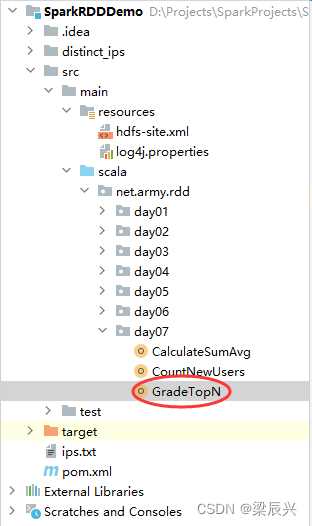
(2)创建分组排行榜单例对象
在net.army.rdd.day07包里创建GradeTopN单例对象
package net.army.rdd.day07
import org.apache.spark.{
SparkConf, SparkContext}
/**
* 作者:梁辰兴
* 日期:2023/6/6
* 功能:成绩分组排行榜
*/
object GradeTopN {
def main(args: Array[String]): Unit = {
// 创建Spark配置对象
val conf = new SparkConf()
.setAppName("GradeTopN") // 设置应用名称
.setMaster("local[*]") // 设置主节点位置(本地调试)
// 基于Spark配置对象创建Spark容器
val sc = new SparkContext(conf)
// 实现分组排行榜
val top3 = sc.textFile("hdfs://master:9000/topx/input/grades.txt")
.map(line => {
val fields = line.split(" ")
(fields(0), fields(1))
}) // 将每行成绩映射成二元组(name, grade)
.groupByKey() // 按键分组
.map(item => {
val name = item._1
val top3 = item._2.toList.sortWith(_ > _).take(3)
(name, top3)
}) // 值排序,取前三
// 输出分组排行榜结果
top3.collect.foreach(item => {
val name = item._1
val scores = item._2.mkString(" ")
println(name + ": " + scores)
})
// 停止Spark容器,结束任务
sc.stop()
}
}
(3)运行程序,查看结果
在控制台查看输出结果
