分组求TopN是大数据领域常见的需求,主要是根据数据的某一列进行分组,然后将分组后的每一组数据按照指定的列进行排序,最后取每一组的前N行数据。
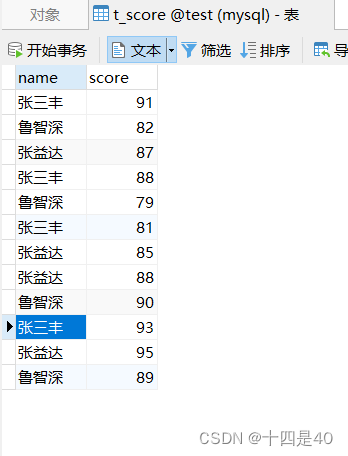
数据表t_grade
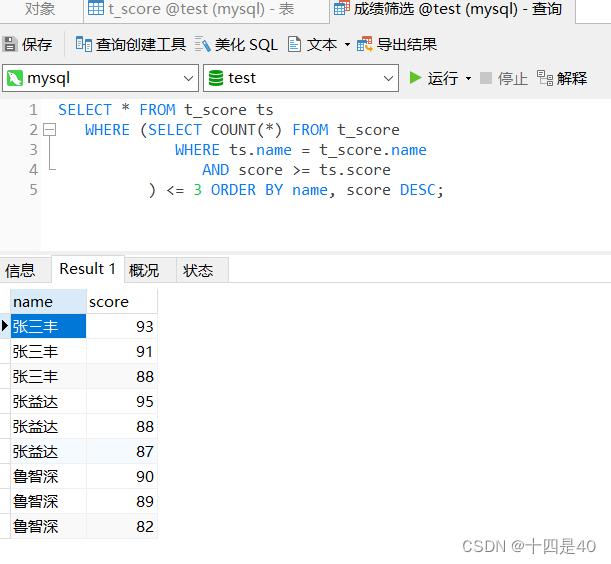
执行查询
SELECT * FROM t_grade tg
WHERE ( SELECT COUNT ( * ) FROM t_grade
WHERE tg. name = t_grade. name
AND score >= tg. score
) <= 3 ORDER BY name, score DESC ;
点击Finish创建项目
<?xml version="1.0" encoding="UTF-8"?>
< projectxmlns = " http://maven.apache.org/POM/4.0.0" xmlns: xsi= " http://www.w3.org/2001/XMLSchema-instance" xsi: schemaLocation= " http://maven.apache.org/POM/4.0.0
http://maven.apache.org/xsd/maven-4.0.0.xsd" > < modelVersion> </ modelVersion> < groupId> </ groupId> < artifactId> </ artifactId> < version> </ version> < dependencies> < dependency> < groupId> </ groupId> < artifactId> </ artifactId> < version> </ version> </ dependency> < dependency> < groupId> </ groupId> < artifactId> </ artifactId> < version> </ version> </ dependency> < dependency> < groupId> </ groupId> < artifactId> </ artifactId> < version> </ version> </ dependency> </ dependencies> < build> < sourceDirectory> </ sourceDirectory> < plugins> < plugin> < groupId> </ groupId> < artifactId> </ artifactId> < version> </ version> < configuration> < descriptorRefs> < descriptorRef> </ descriptorRef> </ descriptorRefs> </ configuration> < executions> < execution> < id> </ id> < phase> </ phase> < goals> < goal> </ goal> </ goals> </ execution> </ executions> </ plugin> < plugin> < groupId> </ groupId> < artifactId> </ artifactId> < version> </ version> < executions> < execution> < id> </ id> < phase> </ phase> < goals> < goal> </ goal> < goal> </ goal> </ goals> </ execution> < execution> < id> </ id> < phase> </ phase> < goals> < goal> </ goal> </ goals> </ execution> </ executions> </ plugin> </ plugins> </ build> </ project>
创建日志属性文件 log4j.properties
log4j.rootLogger=ERROR, stdout, logfile
log4j.appender.stdout=org.apache.log4j.ConsoleAppender
log4j.appender.stdout.layout=org.apache.log4j.PatternLayout
log4j.appender.stdout.layout.ConversionPattern=%d %p [%c] - %m%n
log4j.appender.logfile=org.apache.log4j.FileAppender
log4j.appender.logfile.File=target/spark.log
log4j.appender.logfile.layout=org.apache.log4j.PatternLayout
log4j.appender.logfile.layout.ConversionPattern=%d %p [%c] - %m%n
在scala目录下创建net.xxx.sql包
在net.xxx.sql包里创建GradeTopNBySQL.scala
package net. xjx. sql
import org. apache. spark. sql. {
Dataset, SparkSession}
object GradeTopNBySQL {
def main( args: Array[ String ] ) : Unit = {
val spark = SparkSession. builder( )
. appName( "GradeTopNBySQL" )
. master( "local[*]" )
. getOrCreate( )
val lines: Dataset[ String ] = spark. read. textFile( "hdfs://master:9000/input/grades.txt" )
import spark. implicits. _
val gradeDS: Dataset[ Grade] = lines. map(
line => {
val fields = line. split( " " )
val name = fields( 0 )
val score = fields( 1 ) . toInt
Grade( name, score)
} )
val df = gradeDS. toDF( )
df. createOrReplaceTempView( "t_grade" )
val top3 = spark. sql(
"""
|SELECT name, score FROM
| (SELECT name, score, row_number() OVER (PARTITION BY name ORDER BY score DESC) rank from t_grade) t
| WHERE t.rank <= 3
|""" . stripMargin
)
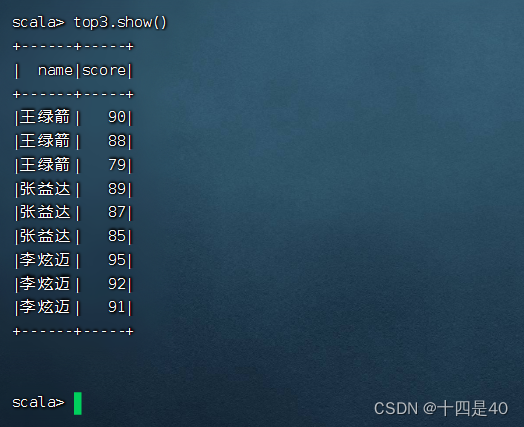
top3. show( )
top3. foreach( row => println( row( 0 ) + ": " + row( 1 ) ) )
spark. close( )
}
case class Grade( name: String , score: Int )
}
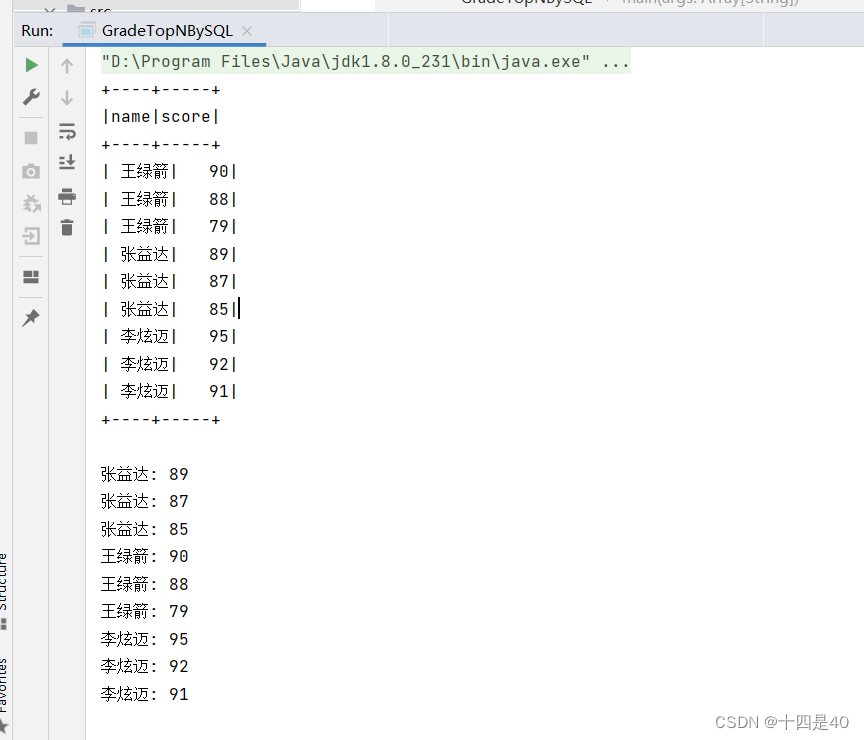
在控制台查看输出结果
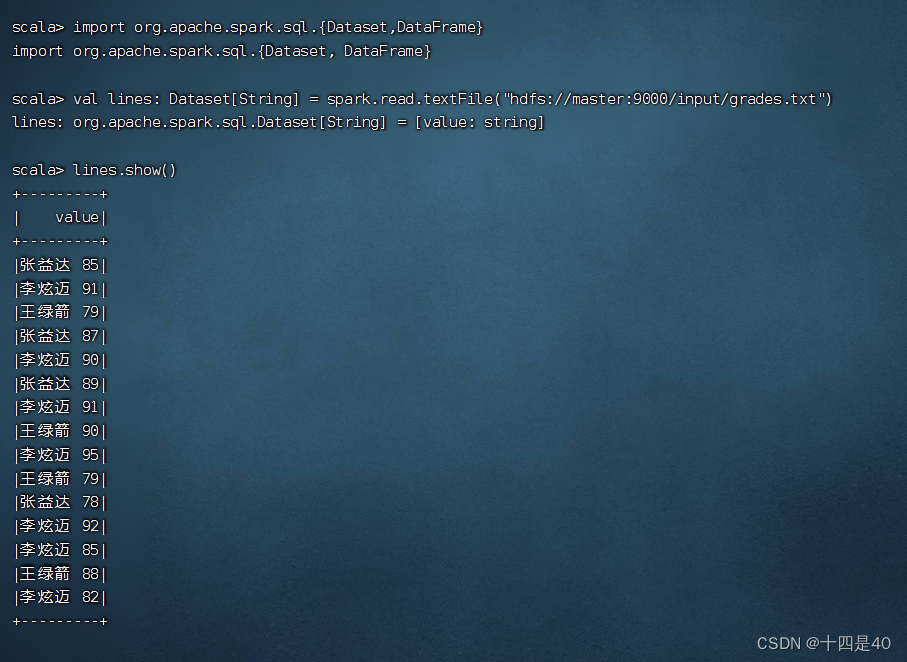
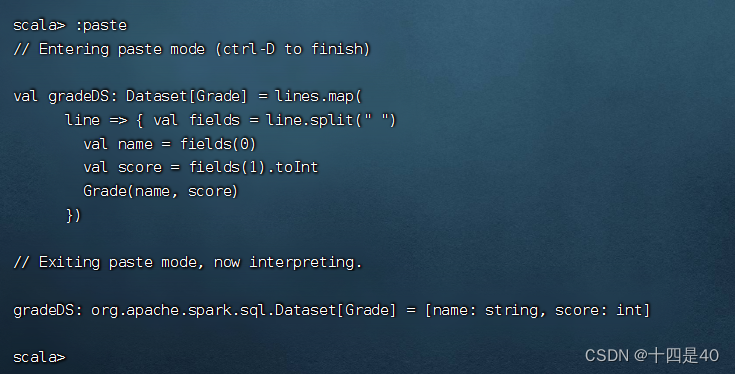
执行命令:val lines: Dataset[String] = spark.read.textFile("hdfs://master:9000/input/grades.txt")
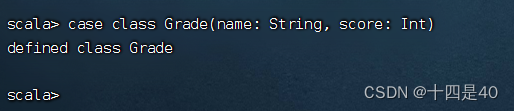
执行命令:case class Grade(name: String, score: Int)
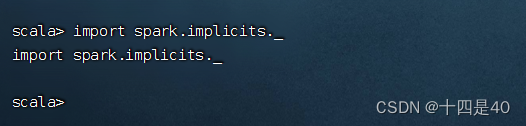
执行命令:import spark.implicits._
val gradeDS: Dataset[ Grade] = lines. map(
line => {
val fields = line. split( " " )
val name = fields( 0 )
val score = fields( 1 ) . toInt
Grade( name, score)
} )
执行上述语句
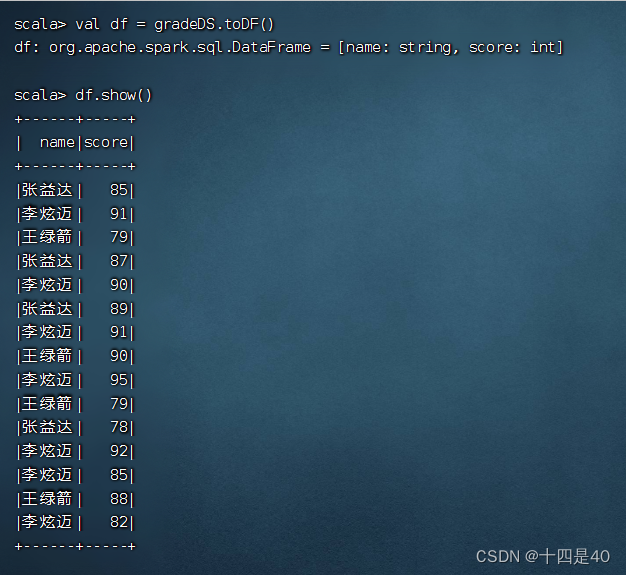
执行命令:val df = gradeDS.toDF()
执行命令:df.createOrReplaceTempView("t_grade")
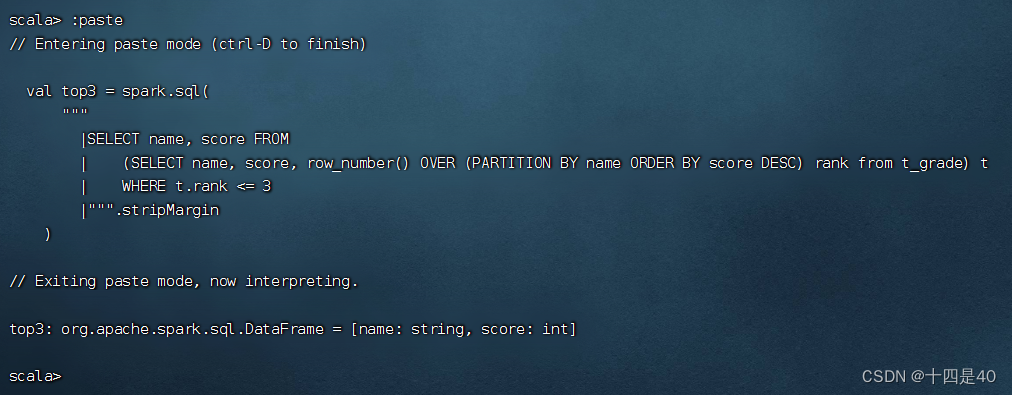
val top3 = spark. sql(
"""
|SELECT name, score FROM
| (SELECT name, score, row_number() OVER (PARTITION BY name ORDER BY score DESC) rank from t_grade) t
| WHERE t.rank <= 3
|""" . stripMargin
)
执行上述语句
执行命令:top3.show()