Gitee 源码: https://gitee.com/futurelqh/symbolic-regression
Abstract
问题:
几何语义遗传规划最近引起了人们的广泛关注。关键创新点在于在语义空间中诱导出单峰适应度景观,为设计几何语义算子提供了理论框架。几何语义算子旨在通过产生有界的语义影响来操纵程序的语义,并生成具有类似或优于其父代的行为的子程序。这些性质被证明与遗传编程中一个显著的泛化改进高度相关。然而,这些几何算子中潜在的无效性和约束变化的困难仍然限制了它们对泛化的积极作用。
我们的方法:
本工作试图进一步探索几何算子的几何和搜索空间,以期在符号回归遗传规划中获得更大的泛化性改进。为此,提出了一种新的角度驱动选择算子和两种新的角度驱动几何搜索算子。角度感知为这些几何算子带来了新的几何性质,有望在每次操作中为逼近目标语义提供更大的杠杆,更重要的是能够抵抗过拟合。
我们做的还不错
实验表明,与两种最先进的几何语义算子相比,我们的角度驱动几何算子不仅能更有效地驱动进化过程以拟合目标语义,而且能提高泛化性能。进一步比较演化后的模型发现,新方法生成的模型通常更简单、尺寸更小,更有可能朝着目标模型的正确结构演化。
I. INTRODUCTION
标准遗传规划 (GP) [1] 一般允许交叉、变异等搜索算子考虑 syntax ,但忽略了 swapping/replacing elements 的 semantic 特征。在 GP 中,semantics 是指对 GP 程序或子程序做了什么的描述 [2]。GP 中 semantics 的定义是 domain dependent(领域独立的,即不同领域有不一样的定义)。这项工作主要集中在符号回归,其任务是寻找输入变量和输出变量之间的潜在关系,并将这种关系用数学或符号模型来表达。在符号回归中,程序 F F F 的 semantics 被定义为向量 S S S [2]。The elements of S S S 是对应该程序关于一组输入 X X X 的输出: S ( F ) = { F ( X 1 ) , F ( X 2 ) , . . . , F ( X n ) } S(F) = \{F(X_1), F(X_2), ..., F(X_n)\} S(F)={ F(X1),F(X2),...,F(Xn)}
与传统的遗传程序设计不同,语义遗传程序设计 (Semantic Genetic Programming,SGP) [2][3] 是最近发展起来的遗传程序设计的变体,它利用 semantics awareness 产生在行为上与父母高度相关的后代。SGP 假设考虑解的详细行为信息可以提高 GP 的有效性。
作为 SGP 的一个特殊分支,几何语义 GP (Geometric Semantic GP,GSGP) [2],[4],[5] 进一步利用了 GP 个体的 semantics 。SGP 将 semantics 作为进化过程的指导,向性能令人满意的程序进化,而 GSGP 旨在直接操作 semantics ,产生最优或接近最优 semantics 的程序的目标。在 GSGP 中,可能解的 semantics 构成了一个 semantics 空间,可以使用不同的距离度量来衡量 GP 个体的适应度。根据距离度量的性质,semantics 空间的曲面可以是不同的圆锥曲线形式。这种性质导致 semantics 空间是单峰的,即最小 error 只能在目标点处获得,不存在 plateaus 。因此,当可以直接操纵 semantics 时,在这样的空间上搜索原则上比在 GP 的搜索空间上搜索要容易得多。然而,在实际中这并不容易,因为程序空间而不是 semantics 空间是被搜索的空间。程序中的变化(互换或替换)与 semantics 空间中的期望移动不对应。几何语义算子试图使直接在 semantics 空间中进行搜索成为可能。
语义空间的几何结构对于增强 GP 是有吸引力的。然而,直接在语义空间中进行搜索是困难的。因此,GSGP 为设计几何搜索算子[4]提供了一个形式化的理论框架 。该框架定义了几何语义算子生成的子代趋向的语义属性。具体来说,语义空间中的几何要求是,geometric semantic crossover 产生的子代点位于连接两个父代点的线段中 (即子程序的语义是父语义的中介) 。并且 geometric semantic mutation 生成的子程序位于父代定义的区间范围内 (即子代的语义与父代的语义差别不大)。
在理论框架的指导下(见 II-A 节),提出了若干为形式化几何性质的实现算法,并提出了各种形式的几何语义算子(简称几何算子)。GSGP 在 [6],[7] 上表现出良好的泛化能力。泛化性反映了学习到的模型的预测能力,在符号回归的 GP 中尤为重要。几何算子所带来的令人印象深刻的泛化增益已经通过它们的几何性质表现出来,这导致了更有建设性的 reproduction (更能够创造出比父代更好适应度的子程序) 和语义空间的微小变化。在这些几何算子的作用下,进化过程更加平滑,保持了更高的语义局部性 (即结构的微小变化导致语义的微小差异)。所有这些方面都有助于提高 GP 的通用性。
然而,这些几何算子都有一定的局限性,可能会限制它们对 GP 的推广作用。需要注意的是,geometric semantic crossover 可能是无效的。只有当目标语义介于两个父代的语义之间时,geometric crossover 才能产生优于两个父代的子代程序。不仅在训练数据上如此,在测试数据上也是如此。此外,随着数据实例数量的增加,geometric crossover 变得更加无效,因为它导致了更高维的语义空间。对于 geometric semantic mutation ,很难确定变异的步长以及变异应该有多紧的界限。过大的变异步长可能导致训练误差减小而测试误差增大 (过拟合),而过小的变异步长会降低 GP 的探索/搜索能力,从而可能导致欠拟合和泛化性能变差。许多研究致力于寻找最优的变异步骤,如自适应几何变异 [6]。然而,这些几何突变对增强 GP 泛化能力的效果仍然有限。
本文的总体目标是针对上述问题开发新的几何算子,提高 GSGP在 符号回归中的泛化能力。新的几何运算符将被设计来进一步利用语义空间的几何性质并结合角度感知。具体来说,本研究有以下三个研究问题/目标:
- 与现有的GSGP方法相比,所提出的几何算子能否提高GSGP对符号回归的学习性能。
- 所提出的几何算子是否以及如何能够比现有的 GSGP 方法进一步提高 GP 对符号回归的泛化能力
- 提出的几何算子是否以及如何影响 GP 中演化程序的大小和可解释性。
这项工作是基于我们的初步调查 [8],[9]。然而,这两项研究均依赖于现有的 GSGP 方法,具有各自的局限性。这项工作通过开发一种新的选择算子和一种新的方法来形式化语义需求,显著地扩展了 [8],[9]。本文对演化后的程序进行了更多实验和深入分析。
II. RELATED WORK
本节介绍与本工作相关的概念,并对当前最先进的 GSGP 方法和最近提出的改进 GP 泛化的方法进行综述。
A. Geometric Semantic Genetic Programming (GSGP)
近年来,GSGP [4] 因其 conic fitness landscape 受到越来越多的关注。关键的是,这个 conic landscape 是单峰的,即最小误差值只在目标语义点处获得。GSGP 中反映几何算子几何性质的理论框架定义如下 [4]。
定义1 Geometric Semantic Crossover (geometric crossover): 给定两个父代个体 P 1 P_1 P1 和 P 2 P_2 P2,以及通过 geometric crossover 产生的子代 O j ( j ∈ 1 , 2 ) O_j(j\in1, 2) Oj(j∈1,2),其在父代的语义片段之间的具有的 semantic 为 O ⃗ j ( j ∈ 1 , 2 ) \vec{O}_j(j\in1, 2) Oj(j∈1,2). i . e . ∣ ∣ P ⃗ 2 − P ⃗ 1 ∣ ∣ = ∣ ∣ O ⃗ j − P ⃗ 1 ∣ ∣ + ∣ ∣ P ⃗ 2 − O ⃗ j ∣ ∣ i.e. ||\vec{P}_2 - \vec{P}_1|| = ||\vec{O}_j - \vec{P}_1|| + ||\vec{P}_2 - \vec{O}_j|| i.e.∣∣P2−P1∣∣=∣∣Oj−P1∣∣+∣∣P2−Oj∣∣
几何算子的实现可以分为两类:exact geometric operators [4] 和 the approximated geometric operators [2],[10],[11]。这些几何算子都有各自的优点和缺点。The exact geometric operator 依靠父代基因型的凸组合直接操作程序的语义,保证了子代在语义空间中的几何性. 文献 [4] 提出了一种几何交叉和变异的实现方法。这种实现是父程序和一个或两个随机程序的凸或线性组合,其结果是为新一代获得所需的语义。The exact geometric operators 使得 GP 具有直接在语义空间进行搜索的能力,而不是仅以语义作为进化搜索的指导. 然而,The exact geometric operators 的一个重要缺点是产生大小难以控制的子代,即 the exact geometric semantic crossover 导致子代大小呈指数增长,而 the geometric mutation 导致子代大小呈线性增长. 过度生长的后代在记忆和时间上都很昂贵。这不可避免地导致演化模型的可解释性较低和无法承受的计算成本,这是 GSGP 应用于具有大量实例数据的障碍。
文献 [7] 给出了精确 GSGP 的改进实现,它没有显式地生成子代。它存储了构建 GP 个体所需的参考信息,即初始种群和一组随机树。在进化过程的最后,可以从参考中产生最佳运行个体。这种实现使得 GSGP 更好地适用于现实问题. 然而,最终演化的模型仍然过于复杂,难以剪枝和解释。在 [12],[13]中,提出了一种新的精确 GSGP 方法,叫 Error Space Alignment GP (ESAGP)。ESAGP 引入了基于语义的 error vectors 和 error space 两个概念,其目的是寻找两个对齐的个体,即在 error space 中 error vectors 夹角最小的两个个体。ESAGP 假设如果能够找到两个最优的对齐个体,那么通过一个比例因子,就能够生成一个具有目标语义的子个体。他们工作的角度定义与本工作类似。然而,这项工作考虑了各种类型的角度,引入角度意识的目的不同。
近似几何算子在 genotype space 中工作,在相应的 semantic space 中对行为进行几何近似。局部几何语义交叉 (LGX) [10]、近似几何语义交叉 (AGX) [14]、随机期望算子 (RDO) (变异) [11] 等近似几何算子不会导致子代过度生长,因为它们一般依靠语义反向传播 [11] 等各种机制近似满足语义要求。下面将对这些算子进行简要综述。
B. Semantic Backpropagation, Approximately Geometric Crossover and Random Desired Operators
设计在 genotype space 中工作并在相应的语义空间中进行几何行为的搜索算子并不简单,因此,与其保证几何行为,近似似乎更为明智。基于这一假设,各种近似几何算子被开发出来。Krawiec 等[14]提出了近似几何交叉 (AGX)。在 AGX 中,子代的期望语义被定义为两个父代片段上的中点。语义反向传播 (SB) 是为了获得想要的语义而提出的。SB的原理是,实现一组较为简单的子目标,从而形成原始目标,应该比直接完成整个目标更容易、更有效。具体来说,SB 在父代树中随机选择一个节点 (即AGX中的交叉点),将树分为后缀和前缀。后缀是包含根节点的子树,而前缀是根在所选节点的子树。相应地,整个树的期望语义也被拆分为两部分,分别是后缀的语义和前缀的期望语义,即子目标语义。为了生成具有期望语义的子树,SB在保留后缀的同时,用具有子目标语义的新子树替换前缀,SB中的关键部分是获取新子树的子目标语义并找到这个新子树。为了计算子目标语义,算法需要通过从根节点到所选节点的一系列节点进行反向传播。从 GP 树的种群中收集具有不同语义的子树构成语义库(semantic library)。The library 每隔几代维护一次。基于一定的距离度量,SB 然后从该语义库中搜索并选择具有(近似)子目标语义的新子树, 随后,作者进一步发展了 SB,提出了一种名为随机期望算子 (RDO) 的几何变异算子 [11],程序运行时,RDO旨在显式地使用目标语义,而目标语义被认为是训练集中最有用的信息。目标语义被认为是新一代所特有的期望语义。AGX和RDO演化出的程序比 the exact geometric operators 产生的程序小很多。然而,这些程序仍然太大而无法解释,并且 RDO 中独特的语义有一个潜在的缺点,即导致语义多样性低和在拟合目标语义时具有贪婪性,这限制了其在提高 GP 泛化能力方面的潜力。
C. Generalisation of GP for Symbolic Regression
泛化能力是指学习到的模型能够在看不见的测试数据上获得良好的预测结果的能力。它是期望的能力之一,也是衡量学习算法有效性的关键性能指标。尽管泛化在机器学习的许多领域已经得到了深入的研究 [15],[16],但在过去相当长的一段时间内,符号回归在 GP 中的情况并非如此。在 2000 年之前,符号回归大多被当作一个普通的优化问题来处理,其中所有可用的数据都被用于演化模型,而模型在未知数据上的泛化性能则完全不被考虑。最近,越来越多的算法被提出来提高 GP 对符号回归 [17-20] 的泛化能力。
由于过拟合是泛化的反常现象,即泛化性差,因此大多数针对符号回归的 GP 泛化研究都致力于降低/控制模型复杂度或避免过拟合。Gon ̧ calves 等 [19] 提出了一种多目标GP算法来增强GP的泛化能力。多目标GP采用演化模型的一阶导数作为模型复杂度的度量。将进化模型的一阶导数与目标模型的一阶导数之间的均方根误差 (RMSE) 作为一个目标,模型的训练误差作为第二个目标。结果表明,它们的方法比标准 GP 具有更好的通用性。Gonçalves and Silva 等[19]提出了一种使用交错采样策略训练数据的GP方法,以实现控制过拟合和为进化过程提供足够信息之间的权衡。训练数据的交错采样分别以确定性和概率性两种方式进行处理。实验表明,所提出的方法的大多数变体可以一致地提高GP的泛化性和减少过拟合。
III. THE PROPOSED ANGLE-DRIVEN GSGP
GSGP 中的理论框架被证明对增强 GP 的普适性具有积极意义。然而,该框架定义的几何算子仍存在一些潜在的局限性,这可能会限制其在获得更好的泛化能力方面的有效性。这项工作试图进一步探索这些搜索算子的几何结构,使其更具建设性。为此,我们将角度感知纳入 GSGP 中,使角度感知成为驱动 GSGP 演化过程的主要力量。因此,提出的 GSGP 方法被称为角度驱动的几何语义 GP ( ADGSGP )。角度感知有望使几何算子更有效,帮助进化过程更准确、更快速地收敛到目标语义。
我们的前期工作 [8] 表明,将角度感知融入 GSGP 对促进其学习和泛化性能具有显著的效果。文献 [8] 在几何交叉中引入了角度感知的匹配方案。给定已赢得锦标赛选择的候选父代集合,交配方案驱动对父代进行几何交叉操作,这些父代与目标的相对语义之间的角度距离最大。这些相对语义之间较大的角度距离有助于减少子代中的语义重复,提高交叉的有效性。具有较大角度距离的个体之间的交配增加了GP的探索能力,使进化过程更快地收敛到目标语义。然而,交配方案存在潜在的局限性。在进化过程中,获得锦标赛选择的候选父代集合在语义空间中越来越容易相互重叠。相应地,寻找大角度距离的父代变得越来越困难。为了解决这一限制并进一步利用 angle-awareness 选择更好父代,本文提出了一种新的角度驱动的几何交叉选择算子(见节 III-B)。新的选择算子直接从整个种群中选择语义空间角度距离大的父代对,而不是从一组优胜者中进行锦标赛选择。此外,我们提出了两种新的几何语义算子,即垂直交叉(PC)和随机片段变异( RSM )。PC 和 RSM 提出的理由是有两个几何算子,它们不仅在学习上更有效,而且在推广上也更有效。更具体地说,PC 是通过进一步探索几何属性来解决几何交叉的无效性,而 RSM 是通过生成与父代高度相关的子个体并在正确的方向上逼近目标语义来解决确定变异步骤的困难。目标语义被假定为数据集中信息量最大的方面。显式地利用这些信息可以进一步提高几何算子的性能。对两种算子的效果的初步考察已在[9]中给出.然而,角度感知几何算子的实现依赖于语义反向传播(SB),而本文将开发一种新的实现算法来解决 SB 的潜在缺陷。新几何算子的细节将在节 III-C–III-E 中给出.
A. Angle-Distance Measurement
在介绍所提方法的细节之前,有必要简要介绍如何度量两个个体的语义之间以及两个相对语义之间的角度距离。由于用于符号回归的GSGP中个体的语义被定义为向量,因此两个个体的语义之间的角度距离被定义为两个向量之间的夹角。在 n n n 维空间 (例如,具有 n n n 个训练实例的符号回归问题的语义空间)中,两个向量 V ⃗ 1 \vec{V}_1 V1 和 V ⃗ 2 \vec{V}_2 V2 之间的夹角 γ \gamma γ 是它们的归一化向量的点积的反余弦函数。其定义如下:
γ = a r c c o s ( V 1 → ∣ ∣ V 1 → ∣ ∣ ⋅ V 2 → ∣ ∣ V 2 → ∣ ∣ ) \gamma = arccos (\frac{\overrightarrow{V_1}}{||\overrightarrow{V_1}||} · \frac{\overrightarrow{V_2}}{||\overrightarrow{V_2}||}) γ=arccos(∣∣V1∣∣V1⋅∣∣V2∣∣V2)
其中,规范化向量或语义为:
V ⃗ j ∣ ∣ V ⃗ j ∣ ∣ = ∑ i = 1 n v j , i ∑ i = 1 n v j , i 2 , j ∈ { 1 , 2 } (1) \frac{\vec{V}_j}{||\vec{V}_j||} = \frac{\sum_{i=1}^n {v_{j, i}}}{\sqrt{\sum_{i=1}^n v_{j, i}^2}}, ~~~~~~~~ j \in \{1, 2\} \tag{1} ∣∣Vj∣∣Vj=∑i=1nvj,i2∑i=1nvj,i, j∈{
1,2}(1)
对于相对向量(相对向量是一个父语义和目标语义之间的向量)之间的夹角,定义上唯一的变化是将归一化向量替换为归一化相对向量。给定三个向量 V ⃗ 1 , V ⃗ 2 , V ⃗ 3 \vec{V}_1, \vec{V}_2, \vec{V}_3 V1,V2,V3,两种相对语义之间的角度 ( V ⃗ 3 − V ⃗ 1 ) (\vec{V}_3 - \vec{V}_1) (V3−V1) 和 ( V ⃗ 3 − V ⃗ 2 ) (\vec{V}_3 - \vec{V}_2) (V3−V2) 定义为:
γ r = a r c c o s ( ( V 3 → − V 1 → ) ∣ ∣ V 3 → − V 1 → ∣ ∣ ⋅ ( V 3 → − V 2 → ) ∣ ∣ V 3 → − V 2 → ∣ ∣ ) (2) \gamma_r = arccos(\frac{(\overrightarrow{V_3} - \overrightarrow{V_1})}{||\overrightarrow{V_3} - \overrightarrow{V_1}||} · \frac{(\overrightarrow{V_3} - \overrightarrow{V_2})}{||\overrightarrow{V_3} - \overrightarrow{V_2}||}) \tag{2} γr=arccos(∣∣V3−V1∣∣(V3−V1)⋅∣∣V3−V2∣∣(V3−V2))(2)
其中规范化的相对语义为:
V ⃗ 3 − V ⃗ k ∣ ∣ V ⃗ 3 − V ⃗ k ∣ ∣ = ∑ i = 1 n ( v 3 , i − v k , i ) ∑ i = 1 n ( v 3 , i − v k , i ) 2 \frac{\vec{V}_3 - \vec{V}_k}{||\vec{V}_3 - \vec{V}_k||} = \frac{\sum_{i=1}^n (v_{3, i} - v_{k, i})}{\sqrt{\sum_{i=1}^n (v_{3, i} - v_{k, i})^2}} ∣∣V3−Vk∣∣V3−Vk=∑i=1n(v3,i−vk,i)2∑i=1n(v3,i−vk,i)
v 3 , i v_{3, i} v3,i 和 v k , i v_{k, i} vk,i 是向量 V ⃗ 3 \vec{V}_3 V3 和 V ⃗ k \vec{V}_k Vk 在第 i i i 个维度上的值。
B. Angle-Driven Selection
在 ADGSGP 中,提出了一种新的选择算子, angle-driven selection( ADS )来选择用于几何交叉的双亲。ADS 的伪代码如算法所示。ADS 根据锦标赛选择第一个父代 p 1 p_1 p1。根据第二个父代 p 2 p_2 p2 与 p 1 p_1 p1 的角度距离,迭代选择第二个父体 p 2 p_2 p2。在此过程中,通过锦标赛选出每个候选 p 2 p_2 p2 ,然后计算其与 p 1 p_1 p1 的角度距离。当达到最大迭代次数 n t nt nt 或找到角度大于预定义阈值 t a ta ta 的候选者时,此过程将终止。为了在寻找最优父代 (例如,角度距离接近180 度的父代)和高计算成本之间取得折衷,经过初步考察,将这两个参数设置为 n t = 10 nt = 10 nt=10 和 t a = 90 ta = 90 ta=90。

与常用的选择算子(例如,锦标赛选择和截断选择)仅根据适应度值选择父代不同,ADS 选择一对不仅具有良好适应度值,而且在语义空间中相对语义(到目标语义)的角度距离相距较远的父代。将 angle-awareness 引入到选择算子中,选择具有大角度距离的父代给进化过程带来了好处。首先,它有助于减少语义重复。由于这些相距较远的父代一般具有不同的语义,且其语义之间的间隔,即语义空间中两个父代点之间的线段远大于相距较近的父代。站在这个更大的片段上的两个子代的语义更可能与父代不同,也更可能与对方不同。这可以潜在地维持/增加群体的语义多样性。其次,远父代的凸包变大,会增加覆盖目标语义的概率,对目标语义的拟合更加准确。双亲之间较大的角度距离对进化过程的益处已经在我们的前期工作中被调查和证实 [8]。与 [8] 中的角度感知交配方案相比,ADS的优势在于增加了寻找大角度父代的概率。ADS直接从种群中选择父代。这些父代对同时满足角度距离和适应度要求,而 [8] 中的交配方案从锦标赛选择的获胜者中选择满足的父对。
C. Perpendicular Crossover 垂直交叉,PC
现有几何算子中子代的期望语义与其父代的语义高度相关。在精确几何交叉中,子代的语义位于父代的片段中,而在 AGX 中,子代的语义位于该片段的(近似)中点。两者都没有考虑通过引入目标语义的几何来提高几何交叉的有效性。较好的几何交叉可以产生不仅与父语义高度相关而且能有效逼近目标语义的子代。为此,本文提出了垂直交叉(PC)。PC 比精确的几何交叉提出了更精确的语义要求。通过这种方式,它旨在驱动搜索更快地收敛到目标语义。给定两个父代个体,PC生成一个子点站在横跨两个父代的直线上,遵循 GSGP 的理论框架。并且,该子点与目标语义给出的相对向量垂直于两个父代定义的向量。假设目标语义为 T ⃗ \vec{T} T ,并且两个父代的语义都是 P ⃗ 1 , P ⃗ 2 \vec{P}_1, \vec{P}_2 P1,P2, 如图 (a-c ) 所示,3 个点定义了一个三角形, α α α 是相对语义 P ⃗ 2 − P ⃗ 1 \vec{P}_2 - \vec{P}_1 P2−P1 和 T ⃗ − P ⃗ 1 \vec{T} - \vec{P}_1 T−P1 之间的夹角, β β β 是 P ⃗ 2 \vec{P}_2 P2 的对应项,给定 T ⃗ , P ⃗ 1 , P ⃗ 2 \vec{T}, \vec{P}_1 , \vec{P}_2 T,P1,P2 ,根据式 (2),可以直接得到这两个角度的值:
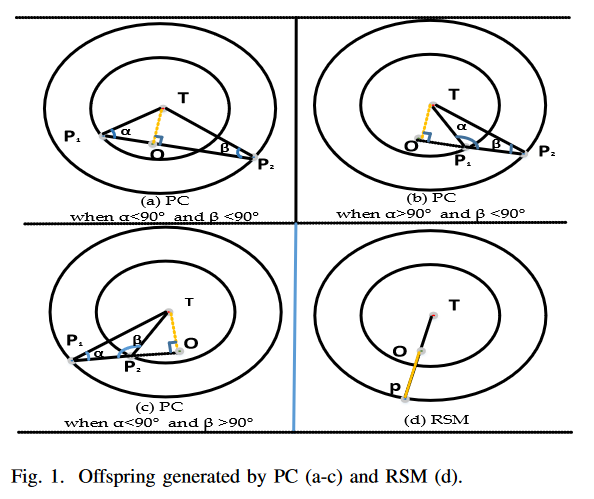
获取子代 O ⃗ \vec{O} O 的语义就是计算 O ⃗ \vec{O} O 的位置,这是垂直从 T ⃗ \vec{T} T 下降到相对语义 ( P ⃗ 1 − P ⃗ 2 \vec{P}_1 - \vec{P}_2 P1−P2) 的基础。如图 (a-c) 所示,根据 α α α 和 β β β 的值, O ⃗ \vec{O} O 有三种可能的位置。第一种情况(如图 (a) 所示) ),当 α α α 和 β β β 都小于 90 度, 子代 O ⃗ \vec{O} O(由图中绿色点表示)位于 ( P ⃗ 1 − P ⃗ 2 \vec{P}_1 - \vec{P}_2 P1−P2) 段。在 α α α 或 β β β 大于 90° 的另外两种情况下,子代沿着 P ⃗ 1 \vec{P}_1 P1 或 P ⃗ 2 \vec{P}_2 P2 一侧的节段站立。为了计算 O ⃗ \vec{O} O 的位置,即直线中某一特定点穿过两个父点的位置,我们采用参数方程来表示这条直线。参数方程是定义 n n n 维空间中直线的最通用的方程。具体来说,假设直线由 n n n 维空间中的两点 P ⃗ 1 \vec{P}_1 P1 和 P ⃗ 2 \vec{P}_2 P2 给出,其中特殊点 O ⃗ \vec{O} O 由 (3) - (5) (对应图 (a-c)) ) 定义如下:
- 当 O ⃗ \vec{O} O 位于 P ⃗ 1 \vec{P}_1 P1 和 P ⃗ 2 \vec{P}_2 P2 之间时,即 α < 90 , β < 90 α < 90,β < 90 α<90,β<90
O ⃗ = P 1 ⃗ + ∣ ∣ P 1 ⃗ − O ⃗ ∣ ∣ ∣ ∣ P 1 ⃗ − P 2 ⃗ ∣ ∣ ⋅ ( P 1 ⃗ − P 2 ⃗ ) , ∣ ∣ P 1 ⃗ − O ⃗ ∣ ∣ = ∣ ∣ P 1 ⃗ − T ⃗ ∣ ∣ ⋅ c o s ( α ) (3) \vec{O} = \vec{P_1} + \frac{||\vec{P_1} - \vec{O}||}{||\vec{P_1} - \vec{P_2}||} · (\vec{P_1} - \vec{P_2}), ||\vec{P_1} - \vec{O}||=||\vec{P_1} - \vec{T}|| · cos(α) \tag{3} O=P1+∣∣P1−P2∣∣∣∣P1−O∣∣⋅(P1−P2),∣∣P1−O∣∣=∣∣P1−T∣∣⋅cos(α)(3)
- 当 O ⃗ \vec{O} O 在 P ⃗ 1 \vec{P}_1 P1 侧的段外时,即 α > 90 α > 90 α>90
O ⃗ = P 1 ⃗ − ∣ ∣ P 1 ⃗ − O ⃗ ∣ ∣ ∣ ∣ P 1 ⃗ − P 2 ⃗ ∣ ∣ ⋅ ( P 1 ⃗ − P 2 ⃗ ) , ∣ ∣ P 1 ⃗ − O ⃗ ∣ ∣ = ∣ ∣ P 1 ⃗ − T ⃗ ∣ ∣ ⋅ c o s ( 180 − α ) (4) \vec{O} = \vec{P_1} - \frac{||\vec{P_1} - \vec{O}||}{||\vec{P_1} - \vec{P_2}||} · (\vec{P_1} - \vec{P_2}), ||\vec{P_1} - \vec{O}||=||\vec{P_1} - \vec{T}|| · cos(180-α) \tag{4} O=P1−∣∣P1−P2∣∣∣∣P1−O∣∣⋅(P1−P2),∣∣P1−O∣∣=∣∣P1−T∣∣⋅cos(180−α)(4)
- 当 O ⃗ \vec{O} O 在 P ⃗ 2 \vec{P}_2 P2 侧外侧时,即 β > 90 β > 90 β>90
O ⃗ = P 2 ⃗ + ∣ ∣ P 2 ⃗ − O ⃗ ∣ ∣ ∣ ∣ P 1 ⃗ − P 2 ⃗ ∣ ∣ ⋅ ( P 1 ⃗ − P 2 ⃗ ) , ∣ ∣ P 2 ⃗ − O ⃗ ∣ ∣ = ∣ ∣ P 2 ⃗ − T ⃗ ∣ ∣ ⋅ c o s ( 180 − β ) (5) \vec{O} = \vec{P_2} + \frac{||\vec{P_2} - \vec{O}||}{||\vec{P_1} - \vec{P_2}||} · (\vec{P_1} - \vec{P_2}), ||\vec{P_2} - \vec{O}||=||\vec{P_2} - \vec{T}|| · cos(180-β) \tag{5} O=P2+∣∣P1−P2∣∣∣∣P2−O∣∣⋅(P1−P2),∣∣P2−O∣∣=∣∣P2−T∣∣⋅cos(180−β)(5)
- 注: 所有的 P ⃗ 1 \vec{P}_1 P1、 P ⃗ 2 \vec{P}_2 P2、 O ⃗ 、 T ⃗ \vec{O}、\vec{T} O、T
其中 ( P ⃗ 1 \vec{P}_1 P1 - P ⃗ 2 \vec{P}_2 P2 ) 给出了直线的方向,其元素定义为 ( p 2 , 1 − p 1 , 1 ) , ( p 2 , 2 − p 1 , 2 ) , . . , ( p 2 , n − p 1 , n ) { ( p_{2,1}-p_{1,1}),( p_{2,2}-p_{1,2}),..,( p_{2 , n}-p_{1 , n}) } (p2,1−p1,1),(p2,2−p1,2),..,(p2,n−p1,n)。 ‖ P ⃗ 1 − O ⃗ ‖ ‖\vec{P}_1- \vec{O}‖ ‖P1−O‖ 和 ‖ P ⃗ 2 − O ⃗ ‖ ‖\vec{P}_2- \vec{O}‖ ‖P2−O‖ 是 P ⃗ 1 ( P ⃗ 2 ) \vec{P}_1 ( \vec{P}_2 ) P1(P2) 和 O ⃗ \vec{O} O 之间的相对距离。
由于GSGP中程序的评价一般定义为与目标语义的距离,当采用欧几里得度量时,精确的几何交叉产生的子代不会比较差的父代差,但PC保证子代程序优于其两个父代。
D. Random Segment Mutation, RSM
受 RDO 的启发,为了更好地控制几何突变引起的语义变化,我们旨在利用目标语义。我们提出了一种角度驱动的几何变异算子,称为随机片段变异 (RSM)。通过操作 RSM,子代期望的语义是站在语义空间中连接父代和目标点的线段上。在 RSM 中获得所需语义的过程的伪代码如算法 2 所示。给定一个父语义 P ⃗ \vec{P} P,RSM 首先需要找到目标语义 T ⃗ \vec{T} T 和 P ⃗ \vec{P} P 之间的分段。然后沿着该段得到一个随机点,将其作为子代 O ⃗ \vec{O} O 的期望语义。期望的语义根据公式 (6) 计算,其原理与公式 (3)-(5) 相同。
O ⃗ = P ⃗ + k ⋅ ( T ⃗ − P ⃗ ) , k ∈ ( 0 , 1 ) \vec{O} = \vec{P} + k·(\vec{T}-\vec{P}), k \in (0, 1) O=P+k⋅(T−P),k∈(0,1)
这种对子代语义的要求遵循了几何变异中的理论要求,同时使得 ( O ⃗ − P ⃗ \vec{O} - \vec{P} O−P) 和 ( T ⃗ − O ⃗ \vec{T} - \vec{O} T−O) 的相对语义之间的夹角恰好为 180 度。这样,RSM对子代的语义控制比精确的几何变异更加精确,从而驱动目标语义在’右’方向的拟合。与 RDO 相比,RSM 生成的子代具有不同的期望语义,是站在父代和目标语义之间间隔上的随机点。这有助于增加种群的语义多样性,并导致 ADGSGP 比 AGSGP 具有更好的探索能力。

E. Semantic Context Replacement 语义语境置换
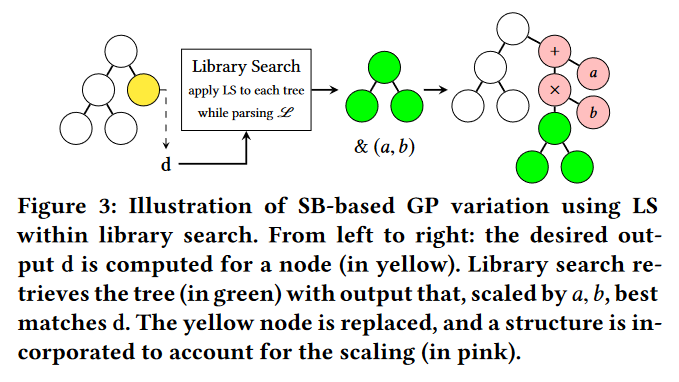
一旦得到了两个几何算子中子代的期望语义,进一步就是生成满足这些语义的子代。在我们的前期工作 [9] 中,语义反向传播(SB)被使用,其目的是通过用子目标语义替换前缀子树来实现所需的语义。在SB中,父树被树中的一个随机选择的节点拆分为后缀和前缀两部分。然后SB保留后缀,后缀一般包含树的根节点。同时,SB将根植于所选节点的子树表示的前缀替换为语义库中具有(近似)子目标语义的新子树。SB的思想虽然合理,但一般会产生过于复杂的模型(但这些模型比精确GSGP中的模型小得多/简单得多)。通过这些复杂的树向后传播来获取子目标语义仍然过于昂贵。同时,过于复杂的模型往往容易过拟合训练集,不能很好的泛化在看不见的数据上。这些限制使得SB无法应用于语义空间较大的问题。
为了避免SB潜在的局限性,本文提出了一种新的近似语义算子,Semantic Context Replacement (SCR) 来满足语义需求。在 SB 和 SCR 中实现所需语义的过程如图 2 所示。SCR 和 SB 的主要区别在于 SB 维护父个体的后缀/上下文并替换前缀,而 SCR 旨在提供更好的后缀/上下文,由一个新的根节点(从一组二元算子中选取)和一个新的具有子目标语义的子树组成,并将前缀的语义保留给子代。做出这种改变的动机是 the context of GP individual 对其适合度的重要性,这已被以往的研究证实[24]。同时,我们预期这种微小但重要的变化在实现预期语义的过程中会带来诸多益处。首先,相比于在SB中反向传播来获得想要的子树语义,SCR更直接地为上下文计算想要的语义。如图 2 所示,SB需要后向传播(从所选节点的父节点到根节点)的几个后续步骤,而SCR只需要一个步骤。一旦确定了新的根节点 R,SCR 将新的根节点 R 的执行反转,得到子目标语义。求逆运算符的规则非常简单,即 + 与 -、* 与 %p (保护除法)相互求逆。此外,用新构造的上下文替换上下文,通常比原来的上下文小,可以潜在地降低后代程序的复杂度。
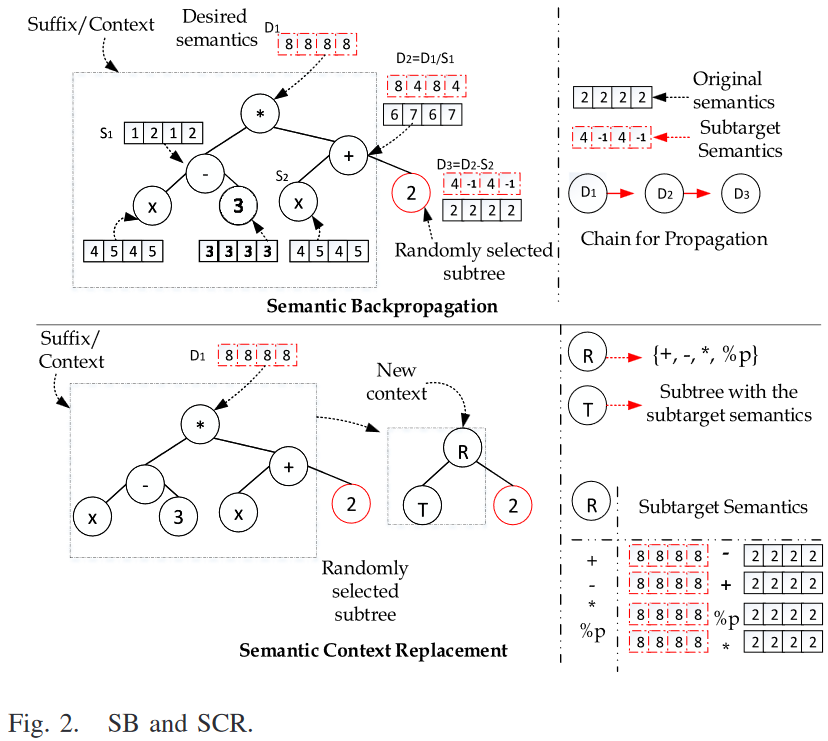
如算法 3 所示,在将树拆分为上下文/后缀和前缀后,SCR通过两步替换树的上下文/后缀,第一步选择根节点,第二步从语义库中选择具有子目标语义的子树。根据候选树(根据公式(1)) )的语义与子目标语义之间的角度距离进行选择。SCR选择相对角距最小的树 T R TR TR。本文使用动态语义库,它包含从当前代中所有个体收集到的所有语义唯一的子树。每一代都需要维护和更新。

我们假设与子目标语义角度距离最近的子树最有可能具有期望的结构,而不是拟合的系数。线性缩放[25]的简单形式已被证明可以有效地找到一组更好的系数。通过对所选子树的输出进行线性缩放,可以帮助找到更好的系数到所选子树以更好地拟合子目标语义。因此,在找到 T R TR TR 后,对 T R TR TR 进行线性缩放[25],即对 T R TR TR 引入两个系数 a 和 b,将其缩放到 ( a + b ⋅ T R ) (a + b · TR ) (a+b⋅TR),其中 a 和 b 分别为线性缩放的截距和斜率。根据 [25],a 和 b 的值定义如下:
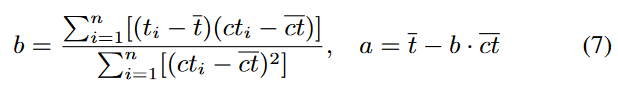
b = ∑ i = 1 n [ ( t i − t ‾ ) ( ( c t i − c t ‾ ) ] ∑ i = 1 n [ ( c t i − c t ‾ ) 2 ] , a = t ‾ − b ⋅ c t ‾ b = \frac{\sum^n_{i=1}[(t_i - \overline{t})((ct_i - \overline{ct})]}{\sum^n_{i=1}[(ct_i - \overline{ct})^2]}, a = \overline{t} - b ·\overline{ct} b=∑i=1n[(cti−ct)2]∑i=1n[(ti−t)((cti−ct)],a=t−b⋅ct
式中: t i t_i ti 为第 i i i 维子目标语义的值, t t t 为所有 t i t_i ti 值的均值, c t i ct_i cti 为 T R TR TR 在第 i i i 维的语义值, c t i ‾ \overline{ct_i} cti 是所有 c t i ct_i cti 的平均值。
IV. EXPERIMENT DESIGN
为了研究和证实我们的新方法ADGSGP的有效性,我们进行了一组实验来比较ADGSGP与两种最先进的GSGP方法和标准GP。三种基准GP方法如下。
- 1) GSGP是指利用精确几何交叉和几何变异的精确GSGP方法。实验采用改进的 GSGP 实现[7]。
- 2) AGSGP [11] 使用了两种最先进的几何算子:1) AGX 和 2) RDO。这两个算子都是基于SB 的。
- 3) 采用标准交叉和变异的标准 GP 也被用作比较的基线。
4 种 GP 方法均在 Python 分布式进化算法 (DEAP) [26]提供的 GP 框架下实现。
A. Benchmark Problems
根据前面对几何算子的研究,我们在一组合成数据集上考察了GP方法的性能。我们在十个合成数据集上测试了GP方法。目标函数和采样策略如表 1 所示。它们取自文献[8],[ 11 ]和[ 27 ] .此外,我们也有兴趣在真实数据集上测试所提出的方法,这些数据在 GSGP 的研究中尚未得到广泛的应用。数据集的详细信息如表 II 所示。训练集和测试集在 DLBCL 中给出,而其他三个数据集在每个GP运行中随机拆分 70% 的数据用于训练,其余 30% 用于测试。这是机器学习[6]、[7]、[28]、[29]中广泛接受的一种数据集拆分方式。在每个独立的GP运行中分裂是不同的,但在一个运行中的四个GP方法是相同的。为了进一步比较,我们还研究了使用五折交叉验证的方法,这些方法显示了几乎相同的模式。有兴趣的读者可参阅在线补充资料进行详细分析。
B. Parameter Settings
表 III 总结了四种 GP 方法的参数设置。这些参数大多是 GP 和 GSGP 中常见的设置 [1],[4]。GP 和 GSGP 中交叉率和变异率不同。标准 GP 通常具有较高的交叉概率,因为交叉被认为比变异对进化过程的进展更重要。GSGP方法需要较高的变异率,才能更有效地促进语义空间的搜索。精确GSGP没有深度限制。对于其他3种GP方法,最大树深度是 17,采用 RMSE 作为适应度函数。每个GP方法在每个问题上进行了 50 次独立运行。值得注意的是,正如之前的研究 [30] 所指出的,在某些情况下,在GP文献中占主流的相同代数下的比较可能不是公平的比较。采用可变大小表示的算法之间的比较需要考虑计算量。
V. RESULTS AND DISCUSSION
本节对四种GP方法得到的结果进行比较和讨论。将从GP方法的训练性能、泛化能力和进化程序的大小等方面进行比较。计算成本也将显示出来。主要比较GSGP方法。采用非参数统计显著性检验- - Wilcoxon检验,显著性水平为0.05,比较最佳运行模型的训练 RMSE 和测试 RMSE。进行了两组统计学显著性检验。一种是介于 GP 和三种 GSGP 方法之间。另一种是三种 GSGP 方法中的一种,即比较 ADGSGP 与另外两种 GSGP 方法。
A. Overall Results
由最佳运行方案得到的 RMSE 在训练集上的分布及其对应的测试 RMSE 如图 3 所示。红色方框为训练集,绿色方框为测试集。表四给出了两组统计显著性检验的结果,’ - ’ 表示 ADGSGP (GP) 显著优于对比方法,‘+’ 表示ADGSGP (GP) 显著差于对比方法,’ = ’ 表示无显著差异。
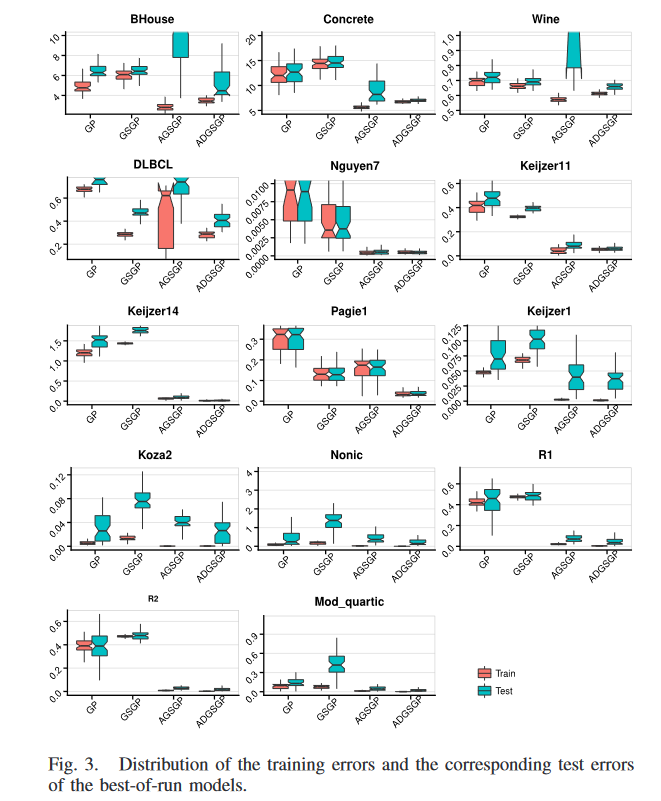
在前 4 个合成数据集(除了 Keijzer14)中的 3 个数据集上,训练实例和测试实例来自相同的分布,3 种 GSGP 方法在训练集和测试集上的 RMSE 普遍远低于标准 GP。在 Keijzer14 和其他 6 个合成数据集上,精确 GSGP 方法产生了比标准 GP 更高的训练和泛化误差。在这 7 个训练集上,有 6 个训练差异显著,泛化差异均显著。在大多数合成数据集上,AGSGP 和 ADGSGP 在学习能力和泛化性能方面都明显优于标准 GP。在所有的合成数据集。ADGSGP 在学习和泛化性能上均优于精确 GSGP。ADGSGP 在 Pagie1 和 Keijzer14 上的训练误差显著小于 AGSGP,在其他训练集上的训练表现没有显著差异。更重要的是,在所有的合成数据集上,ADGSGP 比 AGSGP 具有更低的测试误差,其中在 10 个测试集(除了 Nguyen-7 和 R2 )中的 8 个上优势显著。同时, ADGSGP 在学习和泛化性能上都比其他两种 GSGP 方法有更强的鲁棒性,表现在箱线图中晶须更短。总体而言,新提出的方法 ADGSGP 在合成数据集上无疑是赢家。
真实数据集上的模式与合成数据集上的模式不同。GSGP方法的优越性(特别是在AGSGP中)超过标准GP的情况不如合成数据明显。GSGP在 Concrete 上的训练和测试表现均差于标准 GP。在 BHouse 上,GSGP 也获得了远高于标准 GP 的训练误差,但两者的测试表现没有显著差异。在 Wine 和 DLBCL 上, GSGP 相对于标准 GP 的优势在训练集和测试集上都很显著。在四个真实问题上,AGSGP 获得了明显优于标准 GP 的训练增益。然而,它在两个测试集( BHouse 和 Wine) 上的泛化性能明显差于 GP,而在 DLBCL 上的泛化性能与 GP 相当,仅在 Concrete 上的泛化性能优于标准 GP。与这两个方法不同的是,我们提出的方法ADGSGP在真实问题的所有训练集和测试集上都取得了明显小于标准 GP 的 RMSE。
关于三种GSGP方法在真实世界数据集上的比较,AGSGP在学习性能上的优越性与其在真实世界问题上较差的泛化性能形成鲜明对比,预示着过拟合的发生。ADGSGP并不总是训练性能的赢家,但它在所有情况下的泛化性能都优于其他两种GSGP方法。ADGSGP是唯一一个在所有测试数据集中始终优于标准GP的GSGP方法。ADGSGP的箱线图中明显较短的晶须显示了性能的鲁棒性。统计显著性检验证实ADGSGP在所有真实世界数据集上的泛化能力在四种GP方法中最好。
总的来说,新提出的方法ADGSGP的训练性能与AGSGP相当,远远优于标准GP和GSGP。更重要的是,在泛化能力方面,ADGSGP无疑是四种GP方法中的佼佼者。除 Nguyen-7和 R2 外,它在所有情况下的性能都显著优于其他三种 GP 方法,其中它的性能与 AGSGP 相似。
B. Learning Performance
为了更直观地观察训练效果,图 4 (由于篇幅限制,最后 6 个合成数据集上的进化树如图 1 所示)给出了进化训练图。这些图是使用每一代最优方案得到的 RMSE 的中位数绘制的。
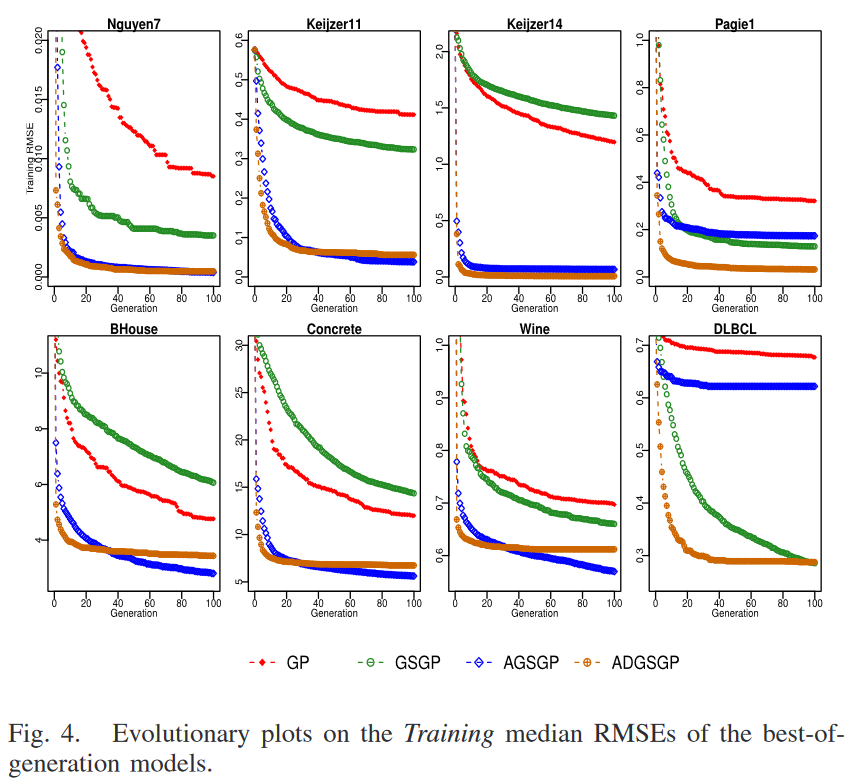
从这些进化训练图可以看出,AGSGP 和 ADGSGP 通常是拟合训练数据最有效的方法。进化的进展是由于有效育种的百分比,即比父代学习表现更好的孩子的数量增加了。在所有的训练集中,ADGSGP始终如一地实现了更快的训练误差下降,这表明它比GSGP和AGSGP学习得更快。PC的几何特性使得ADGSGP在演化过程的早期收敛速度远远快于其他3种GP方法。随着进化过程的进行,ADGSGP越来越难以接近目标语义,训练误差在第20代左右后下降得非常缓慢,这一点很明显。这可能是由于很难找到关于它们的角度-距离较远的双亲,这限制了新的几何交叉的有效性。此外,这是由于PC和RSM的几何结构导致的一个不可避免的现象。当整个群体越接近目标语义时,父代与目标语义的距离越小。较小的相对距离导致向目标语义的移动较小。在大多数训练集中,AGSGP 与 ADGSGP 具有相同的难度。然而,在三个真实数据集(即BHouse、Concrete 和 Wine )上的情况有所不同。在这些数据集上,训练实例的数量远远高于其余 5 个训练集。因此,与其他数据集相比,它们的语义空间在维度上要大得多。在这种场景下,逼近目标语义更加困难。AGSGP中的 RDO 旨在产生与目标语义高度相关的子代,贪婪地逼近目标语义,在该场景下能够比其他GP方法更好地拟合目标语义。在其他数据集上,这种优势并不十分明显。精确GSGP一般比AGSGP和ADGSGP学习速度更慢,产生的训练误差也更大。特别地,在几乎所有的训练集上,GSGP比ADGSGP更慢地拟合目标语义。在DLBCL中,GSGP从很早的几代开始就优于AGSGP和标准GP,并且这种优势随着代数的增加而增加。
综上所述,在进化过程中引入语义信息并不总能带来改进,表现为在14个数据集上,精确GSGP的学习速度远慢于标准GP。语义信息的利用是影响学习速度和学习效果的重要因素。具有角度感知功能的ADGSGP探索搜索算子在语义空间中的几何性质,通常比GP和精确GSGP更快更准确地拟合目标语义。
C. Generalization Performance
与训练性能相比,我们更感兴趣的是GSGP方法的泛化能力。图5 (以及补充材料中的图1)为最佳世代模型在测试集上泛化误差中值的进化图。如图所示, GSGP 仅在14个测试集中的 5 个测试集上延续了标准GP的优势。而在其他9个训练性能较差的数据集上,GSGP也表现出比标准GP更差的泛化性能。在 BHouse 和 R1 上,随着代数的增加,GSGP 与标准 GP 的泛化性能差异有所减小。在进化过程的最后,它们具有几乎相同的泛化误差
对于AGSGP和ADGSGP,在合成的测试集上,整体模式与在训练集上非常相似。两者在这些测试集上都能很好的泛化。同时,ADGSGP在10个测试集上泛化效果最好。它在所有测试集上都显著优于GSGP,在10个合成测试集上有8个显著优于AGSGP。然而,对于AGSGP,在真实数据集的测试集上的整体模式与在训练集上的整体模式有很大的不同。AGSGP失去了优势,难以在四个真实世界问题的未知数据上很好地推广。在AGSGP中,四个问题都出现了过拟合,其中 BHouse 和 Wine 出现了严重的过拟合,DLBCL 和 Concrete 出现了微弱的过拟合。与 AGSGP 不同的是,提出的 ADGSGP 方法在所有测试集上都能很好地泛化并抵抗过拟合。可能的原因是,与 AGSGP 中的 RDO 相比,ADGSGP 中的 RSM 产生了与亲本高度相关的后代。随着进化的进行,当 AGSGP 中的 AGX 和 ADGSGP 中的 PC 都有困难导致搜索过程进一步进展时,RSM 比 RDO 给后代带来的变异更小。因此具有限制泛化误差恶化的潜力。换句话说,RSM在逼近目标语义时更少贪婪,从而驱动ADGSGP具有良好的泛化性和抗过拟合性。这可以通过AGSGP在训练集上向ADGSGP推进的阶段正好是AGSGP发生过拟合的时刻来说明。对泛化的另一个可能贡献是 SCR,这是我们为满足语义要求而提出的新方法。与AGSGP中的SB相比,SCR诱导了更简单的程序,这些程序更有可能在看不见的数据上更好地泛化。这将在后文第六节对演化程序的分析中得到证实。
总体而言,在大多数测试集上,3种GSGP方法的泛化性都远远优于标准GP,这证实了几何算子的几何性质,即子程序所犯错误以最差的(或ADGSGP最佳)个父代为界,同样适用于未见数据。特别是对于合成数据集,该问题在一定程度上比具有大量实例的现实世界问题更容易。这些较小的语义空间具有较少或没有噪声,因此训练集中目标语义的模式可以代表问题的实际模式。这也解释了为什么在合成数据集和DLBCL (其中实例数量远小于其他三个真实数据集)的测试集上的整体模式与训练集几乎相同。
另一方面,GSGP中的几何算子也会给GP个体带来负变异,增加后代的泛化误差。当这些算子产生的大部分变异为负值时,就会出现过拟合。与RDO相比,RSM中施加给父代的变化是有界的且更小,这使得泛化误差的恶化(增加)更慢,从而导致ADGSGP具有更好的泛化性。
D. Comparisons on Program Size and Computational Time
表 V (补充材料见表 1)显示了最佳运行GP个体中节点数量的平均和最小程序大小。计算成本也以进化训练过程中一个GP运行的平均和最小计算时间(以秒为单位)的形式表示,其中 N/A 表示我们没有考虑精确 GSGP 的计算成本,因为 GSGP 的实现方法没有显式地生成 GP 树。
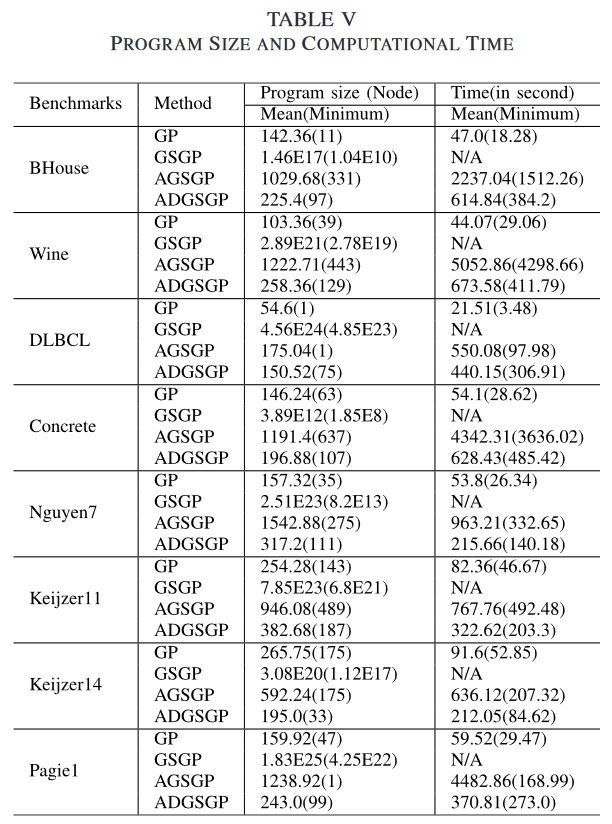
可以清楚地看到,在大多数数据集上,精确GSGP和AGSGP的程序规模明显大于标准GP。与其他3种GP方法不同,精确GSGP对GP树的最大高度没有限制。精确的几何算子导致子代规模呈指数或线性增长。因此它比其他三种GP方法具有更大的程序规模。在实际问题中,精确GSGP的平均程序规模在数百万。在这种情况下,进化出的程序不可能被人类专家解释,也就失去了 GP 相对于传统机器学习算法如支持向量回归 [31 ]等执行黑箱回归的优势。在AGSGP中,演化程序的大小比标准GP中的程序大3 ~ 10倍。这可能是由于SB容易找到更复杂的具有期望(或近似)语义的树来替换树的原始前缀。新的子树与原始前缀之间的复杂度差异会随着代数的增加而累积,这将导致一个更大的GP个体。正如预期的那样,在所有的测试案例中,ADGSGP的程序规模都比AGSGP小得多。这证实了我们的假设,即用SCR替换树的上下文比用SB更有利于限制程序规模的增加。另一方面,ADGSGP中演化程序的平均规模是标准GP的 1.3~3 倍左右。在 Keijzer14 上,它甚至比标准GP具有更小的平均程序大小。这表明ADGSGP不会过多降低GP程序的可解释性,计算开销的增加也是可以接受的。更重要的是,程序简化方法[ 32 ],[ 33 ]可能适用于ADGSGP (这对于AGSGP中的超大规模程序来说并非易事)。这将有助于解决GSGP方法中程序规模过大这一开放性问题。程序大小的另一个规律是,与GP和AGSGP相比,ADGSGP中程序的大小更加稳定。这表现为平均程序规模与最小程序规模之间的差异要小得多。ADGSGP不产生规模极大/极小的程序。
一个有趣的现象是,GSGP方法中的这些超大/复杂程序通常比标准GP中的程序在看不见的数据上泛化得更好。这与被广泛接受的最小描述长度原则 [34] 和Occam’s razor [35] 等理论相冲突,认为复杂程序难以很好地泛化。对这一现象的一个可能的解释是,不仅程序的大小/复杂性很重要,而且它们是如何产生的也很重要。这些理论在以不同方式产生的模型中可能并不成立。以往的研究将这些超大规模程序视为程序的集合 [6]。他们声称在最终演化的程序(与集合中相同)中可能存在一些过度拟合的子程序。然而,它们对泛化误差增加的贡献可以被泛化性能好的程序中的对应程序减少/消除。
考虑到标准GP、AGSGP和ADGSGP的计算成本比较,AGSGP和ADGSGP的计算成本远高于标准GP。AGSGP和ADGSGP中语义库的维护和搜索过程所需的时间较长。此外,随着程序规模的增长,AGSGP中的SB和ADGSGP中的SCR计算期望语义的过程变得更加昂贵,尤其是需要从根节点向树中的选定节点反向传播的SB。在最坏的情况下,它需要通过几乎整个树反向传播。在SCR中,上下文的根节点确定后只需要一步传播。这就解释了为什么ADGSGP中的计算成本远小于AGSGP。另一个重要原因是ADGSGP比AGSGP的程序规模小得多。ADGSGP在选择和育种过程中需要额外的角度感知费用。然而,相对于搜索所需上下文(或者AGSGP中的期望子树)的成本要高得多,这个额外的成本可以忽略不计。
E. Analysis of Evolved Models
进一步对 3 种 GP 方法演化出的模型进行(由于GSGP演化出的模型过于庞大,不便于展示和分析,故在分析中略去)检验。我们从 50 个 GP 运行中随机抽取一个运行,并在该运行中检查三种GP方法的演化模型,我们重复两次这个过程来检查Keijzer14上的两组(随机)模型,其中目标函数已知,并且AGSGP和ADGSGP都取得了良好的学习和泛化性能。为了使分析更加清晰,我们还给出了这些模型的数学简化形式。两种形式的模型分别显示在表 VI 的第二列和第三列。
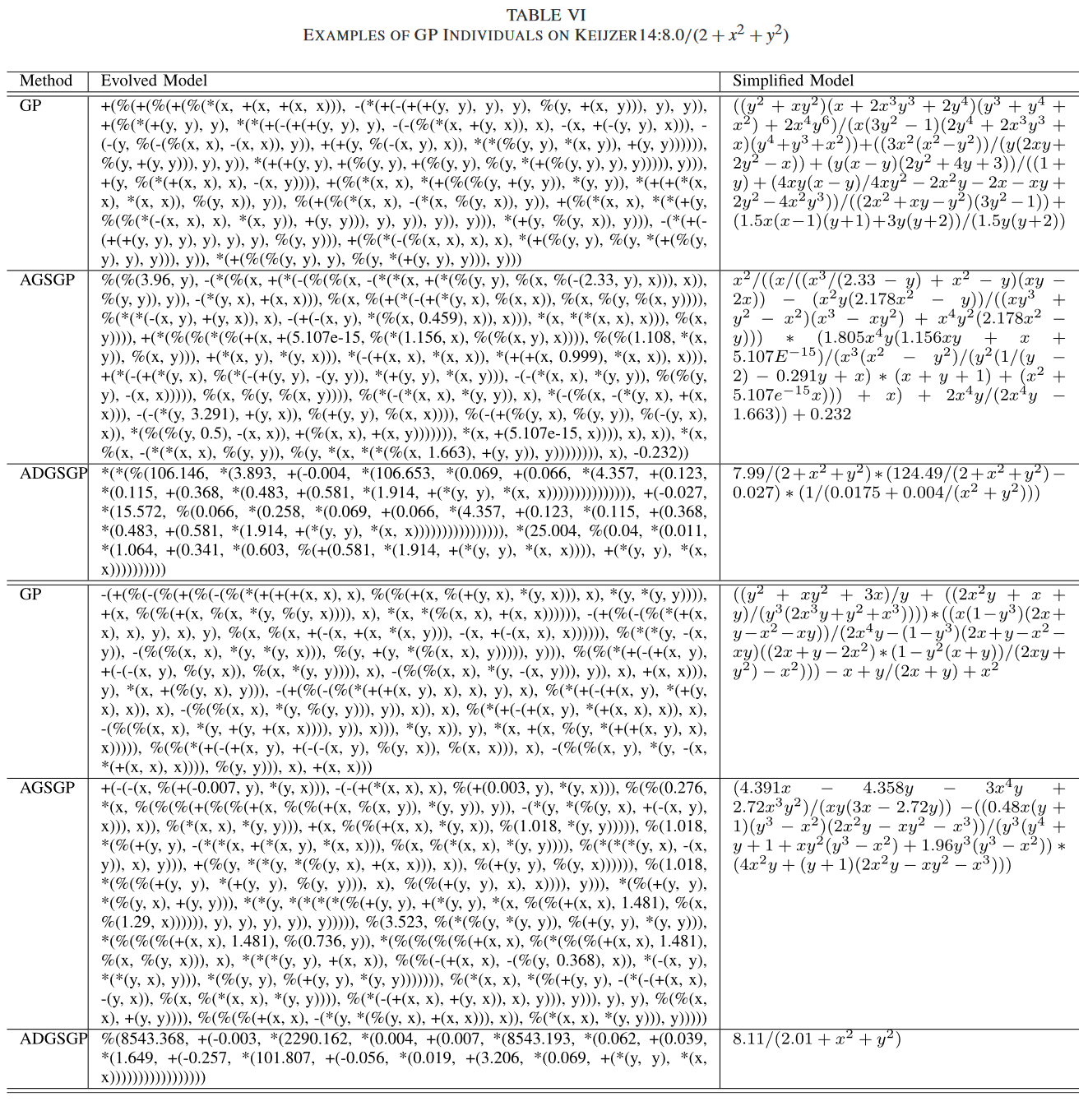
显然,ADGSGP中的演化模型比AGSGP中的演化模型要简单得多。反映演化模型行为的简化模型之间的差异更为明显。在两个例子中,ADGSGP中模型的行为不仅比标准GP和AGSGP中模型的行为更加平滑,而且与目标函数( ADGSGP实际上在Keijzer14上找到了最重要的积木块 x 2 + y 2 x^2 + y^2 x2+y2,与目标函数唯一的区别在于模型的参数)的行为更加相似。AGSGP相对于标准GP的优势可能来自与集成学习相同的强度,而ADGSGP能够找到目标模型,不仅具有更好的学习性能,而且具有很好的泛化性。
VI. FURTHER ANALYSIS
为了进一步考察本文提出的 3 种角度驱动算子的效果,分别在选取的8个数据集上测试了标准选择算子(即,锦标赛) (记为 PC-SS) 的 PC、提出的 ADS(PC)的 PC 和 RSM。并与精确GSGP和AGSGP进行比较。因此,本部分测试的GSGP 方法有:GSGP、AGSGP、PC-SS、PC 和 RSM。
如图6所示,在四个合成数据集上,PC - SS、PC和RSM都具有明显优于GSGP的训练性能。与AGSGP相比,在 Keijzer11 上,PC-SS 和 PC 的训练均方根误差明显较大,RSM 的训练均方根误差略大。在另外 3 个合成数据集上,PC-SS、PC 和 RSM 都比 AGSGP 具有更好的训练性能。在 Nguyen7 上,它们之间的差异不显著,而在另外两个训练集上,PC-SS、PC 和 RSM 都具有显著优于 AGSGP 的训练性能。
在四个真实数据集(DLBCL除外)中的三个数据集上,PC-SS、PC 和 RSM 在训练性能上都比 GSGP 有显著的提升,但比 AGSGP 差很多。在 DLBCL 上,PC-SS 和 PC 的训练误差略大于 GSGP,但均不显著。RSM 的训练性能明显优于 GSGP。在 DLBCL 上,PC-SS、PC 和 RSM 均比 AGSGP 有更好的训练表现。PC-SS性能略优,但 PC 和 RSM 较 AGSGP 优势明显。
图 7 中关于泛化性能的演化图表明,在四个合成测试集上的整体模式与在训练集上的模式非常相似。PC-SS、PC 和 RSM 均比 GSGP 和 AGSGP 具有更好的泛化性能。在 Keijzer11 上,AGSGP 失去了泛化性能上的优势。PC 与 AGSGP 具有相似的泛化性能,而 RSM 的泛化性能最好。在四个真实数据集上,该模式与训练集上的模式差别很大。在 AGSGP 存在严重过拟合的四个数据集上,PCSS、PC 和 RSM 总体上泛化效果较好。在五种 GSGP 方法中, PC 在 BHouse 和 Wine 上的测试性能最好,而在另外两个数据集上,RSM 是胜者。
总之,在大多数测试的数据集上,单独使用三种算子的 GSGP 在学习性能和泛化能力上都优于 GSGP。与 AGSGP 相比,它们具有相当的学习能力但泛化性能要好得多。PC 和 RSM 具有相当的训练和泛化性能,远远优于 PC-SS。PC-SS 与 PC 的唯一区别在于选择算子。采用所提 ADS 的 PC 比 PC-SS (其中使用标准的锦标赛选择)更能提高 GSGP 的性能。这是 ADS 有效性的一个很好的证据。此外,从图中可以看出。4~7 (以GSGP和AGSGP的性能为基准进行比较),与单独使用 PC 或 RSM 相比,组合使用(即 ADGSGP )对提高 GP 的训练和泛化性能都有更好的效果。
GPAGLX 的性能,即我们前期工作中提出的方法 [8],也已经过测试。由于篇幅限制,结果和详细分析见补充材料。简要地总结一下,GPAGLX 在大多数测试的数据集上具有与 ADGSGP 相当的训练性能,但泛化性明显差于 ADGSGP。
VII. CONCLUSION
总结:
实现了进一步探索几何算子的几何性质以在 GP 中获得更大的符号回归泛化增益的目标。所提出的角度驱动几何算子为GP提供了一个令人印象深刻的泛化改进。在角度感知的情况下,PC产生的子程序的错误受其最佳父代的约束,RSM对父代程序提供了较小的变异,但不断向目标语义移动。这些新的几何性质为在每个操作中逼近目标语义提供了有效的杠杆
为了验证ADGSGP方法的有效性,本文对ADGSGP、精确GSGP和近似GSGP (Approximate GSGP,AGSGP)进行了全面的比较。据我们所知,这是第一个填补这两个GSGP变体之间比较空白的工作。以标准GP作为基线进行比较。与GP相比,GSGP方法一般能进化出具有更好学习性能和泛化能力的模型。然而,精确GSGP在一些数据集上较差的学习和泛化性能(高于标准GP)以及AGSGP在真实世界数据集上的过拟合趋势也表明将语义引入进化过程并不总是带来好处。语义信息的利用方式对GP的性能影响很大。角度感知的几何算子消除了GSGP潜在的无效性,增加了有效繁殖的机会,使得ADGSGP以更快的学习速度大幅提高了精确GSGP和AGSGP的学习性能。更重要的是,在ADGSGP中,RSM在逼近目标语义方面比RDO更不贪婪,给父程序带来的变化更小。语义上下文替换持续产生更简单/更小的程序,它们比两种最先进的GSGP方法更有可能包含正确的结构。所有这些特性使得解更耐过拟合,在看不见的数据上泛化性更好。
另一个有趣的发现是GSGP方法中的模型通常泛化性较好但过于复杂,这与复杂程序难以泛化的共同主张相冲突。这些复杂模式较好的泛化增益可能来自与集合相同的强度。此外,ADGSGP中演化模型的简化形式更接近目标模型(例如,包含最重要的积木),代表了正确的模式,因此对未见数据具有很好的泛化性
综上所述,四种GP方法(包括两种最先进的GSGP方法)的比较表明,本文提出的方法具有更快的收敛速度,良好的解释能力,并且需要较少的计算工作量。对于需要快速的责任和目标是对底层数据生成过程有良好的洞察力的真实应用时适合的。
未来展望:
对于未来的工作,我们计划通过降低计算成本和提高计算效率来进一步改进ADGSGP。如前所述,该方法的主要开销在于语义库的维护和搜索。与ADGSGP中使用的穷举搜索不同,将探索一种启发式搜索方法,在不降低搜索所需子树过程有效性的同时,提高搜索效率。此外,ADGSGP中的选择算子是基于间接的方式。未来我们将考虑度量种群的分布,并根据GP个体在目标语义周围的角度分布来选择GP个体。
Reference
[1] Chen Q, Xue B, Zhang M. Improving generalization of genetic programming for symbolic regression with angle-driven geometric semantic operators[J]. IEEE Transactions on Evolutionary Computation, 2018.
算法原理
在第 III 部分介绍的很详细,其中线性缩放部分的原理见下图: