Lseg(Language -driven semantic segmentation)ICLR2022

第一行图中,能够完美的将狗和树分开,为了验证模型的容错能力,加一个汽车vehicle的标签,模型中也并没有出现汽车的轮廓。另一方面,模型也能区分子类父类,标签中不再给出dog而是给出pet,dog的轮廓同样可以被分割开来。
第三行图中,椅子、墙壁甚至地板和天花板这种极为相似的目标也被完美的分割开来。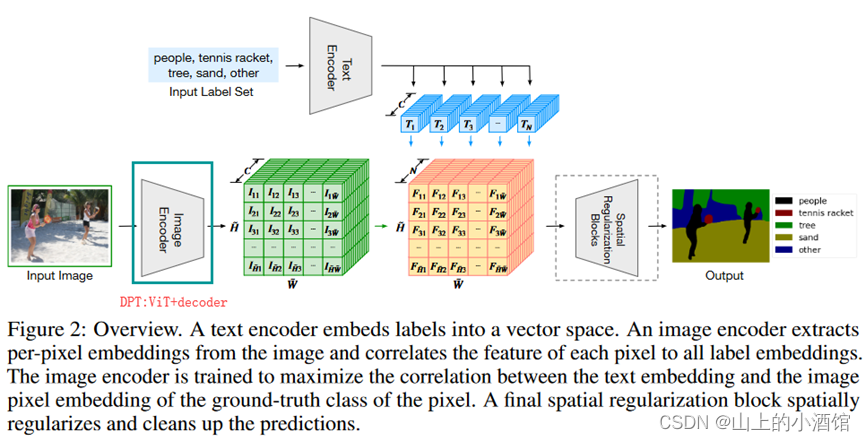
如上图,与CLIP结构非常像,模型总览图中图像和文本分别经过图像编码器(Image Encoder)和文本编码器(Text Encoder)得到密集dense的图像文本特征。此处密集的图像特征需进一步放大(up scaling)得到新的特征的图与原图大小一致,这一步也是为分割任务的实现。然后模型的输出与ground true的监督信号做一个交叉熵损失就可以训练起来了。Image Encoder的结构就是ViT+decoder,其中decoder的作用就是把一个bottleneck feature慢慢upscale上去。

这里的Loss不像CLIP使用对比学的loss,而是跟那些Ground True mask做的cross entropy loss,并非一个无监督训练。这篇论文的意义在于将文本的分支加入到传统的有监督分割的pipeline模型中。通过矩阵相乘将文本和图像结合起来了。训练时可以学到language aware(语言文本意识)的视觉特征。从而在最后推理的时候能使用文本的prompt任意的得到分割的效果。

本文中文本编码器的参数完全使用的CLIP的文本编码器的参数,因为分割任务的数据集都比较小(10-20万),为保证文本编码器的泛化性,就直接使用并锁住CLIP中文本编码器的参数。图像编码器使用Vit / DEit的预训练权重,使用CLIP的预训练权重效果不太好。
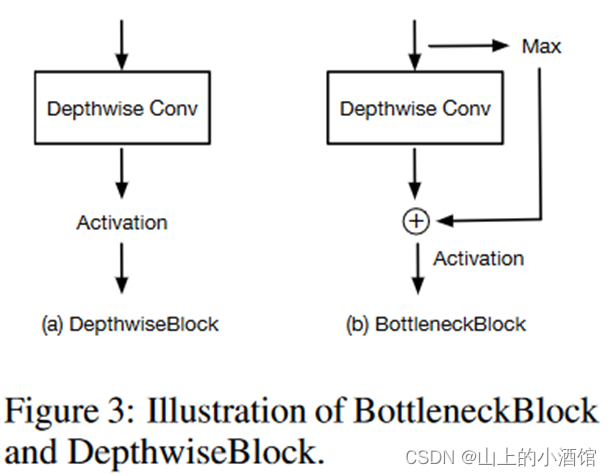
Spatial Regularization Blocks这个模块是简单的conv卷积或者DWconv,这一层进一步学习文本图像融合后的特征,理解文本与图像如何交互。后边的消融实验证明,两层Spatial Regularization Blocks效果最好,但是四层Spatial Regularization Blocks突然就崩了。其实Spatial Regularization Blocks这个模块对整个性能没有多大影响,可以先不去考虑。

PASCAL数据集上的结果,LSeg在zero-shot 上效果要好不少,但是对于1-shot来说还是差了15个点左右。如果使用大模型(ViT-L)也还是差了6个点左右。

本质上再算图像特征和文本特征之间的相似性,并不是真的再做一个分类,就会把dog识别成toy玩具狗。
python的学习还是要多以练习为主,想要练习python的同学,推荐可以去看,他们现在的IT题库内容很丰富,属于国内做的很好的了,而且是课程+刷题+面经+求职+讨论区分享,一站式求职学习网站,最最最重要的里面的资源全部免费。
他们这个python的练习题,知识点编排详细,题目安排合理,题目表述以指导的形式进行。整个题单覆盖了Python入门的全部知识点以及全部语法,通过知识点分类逐层递进,从Hello World开始到最后的实践任务,都会非常详细地指导你应该使用什么函数,应该怎么输入输出。
牛客网(牛客网 - 找工作神器|笔试题库|面试经验|实习招聘内推,求职就业一站解决_牛客网)还提供题解专区和讨论区会有大神提供题解思路,对新手玩家及其友好,有不清楚的语法,不理解的地方,看看别人的思路,别人的代码,也许就能豁然开朗。
快点击下方链接学起来吧!
牛客网 - 找工作神器|笔试题库|面试经验|实习招聘内推,求职就业一站解决_牛客网
参考: