ABSTRACT
本文针对遗传规划在符号回归中收敛性能低的问题,提出了一种新的算子 —— 语义聚类算子。陡峭收敛(steep convergence)的主要策略是缩小搜索空间,并使用语义聚类库对缩小的搜索空间进行检查。为了证明这一想法的成功,将本文开发的算子的计算时间和后代适应度与穷举搜索进行了比较。该算子的计算时间约为穷举搜索的 6%,其子代适应度在穷举搜索的所有子代中位于前 0.5%。在两个应用问题中,使用该算子的算法得到的模型显示出与人工神经网络、随机森林和支持向量机相媲美的高预测精度。
1. INTRODUCTION
近年来,机器学习在解决工程问题中的应用得到了广泛的研究。深度学习 [1]、模糊[2]、贝叶斯方法[3]、随机森林[4] 和遗传规划 (Genetic Programming,GP) [5]等各种算法被用于优化、建模和计算机视觉。在这些算法中,GP [6] 被用于符号回归来解决经验建模问题[7-9],并得到结构设计规范[10、12],因为它可以提供可解释和数学上易于处理的模型[13]。图 1 给出了使用 GP 进行符号回归的示意图。如图 1 所示,该算法创建多个程序(即公式)表示为表达式树,并重复执行评估、选择、交叉和变异[6]。经过这些迭代,推导出了一个简单而精确的数学模型。

GP 的目标之一是开发一种能够以较低的计算成本提供更精确解的算法。尽管由于 no free lunch theorems for optimization (NFLT)[ 14 ],无法开发出通用算法,但研究人员正努力通过克服 GP 的缺点来最大化算法的性能。例如,显著降低 G P训练效率的早熟收敛[15],已经通过 randomizing、restarting[16]、multi-objective methods [17、18] 等多样性管理技术解决。此外,使用原始 GP 很难实现不断优化[6];然而,在进化过程中应用 Nelder-Mead [19]或 evenberg –Marquardt [20、21] 方法 [22] 解决了这一问题。
在过去的十年中,原始 GP 中使用的 syntax-based 的运算符问题被提出[23],其中 syntax 是指程序的表面形式[ 24 ]。由于 GP 是进化驱动的优化器,父代(即行为或语义)的遗传性状必须由子代遗传才能实现陡峭收敛。为了达到这个目的,原始 GP 通过交换适应度好的两个父代的语法部分来产生后代[6]。然而,这种方法在一些问题中很难传递遗传性状,其中轻微的句法变化就会导致遗传性状的较大变化。这类问题被称为复杂基因型-表型映射问题 [25]。符号回归属于这些问题,因为函数的微小修改会使函数行为发生显著变化。作为回应,建立了语义的定义,即关于输入的程序行为[24],并开发了可以适当传递遗传性状的基于语义的操作符 (SBO)。它们的使用显著提高了 GP 的收敛性能,目前已成为一个重要的研究课题[26]。
在 SBOs 中,随机期望算子 (RDO) [27] 由于其陡峭的收敛性能受到了广泛的关注。该算子由随机节点选择、语义反向传播(SB)、库搜索 (LS) 和替换组成。 SB 是一种计算节点的期望语义的方法,其中期望语义是子程序为了使子代成为精确程序而应该具有的语义。库是一组子程序,LS 是在库中寻找语义与期望语义最相似的子程序。RDO 选择一个随机节点,并对该节点执行 SB。之后,它利用从 SB 中导出的期望语义执行 LS,并将节点替换为从 LS 中导出的子程序。通过这个过程,RDO 能够实现陡峭的收敛性能。同时,考虑多个节点而不是一个随机节点有利于得到一个好的子代。图 2 解释了这个简单的假设。

问题是找到一个精确的程序 y = 9 x ( x + 1 ) y = 9x( x + 1) y=9x(x+1),在这种情况下提供了适应度案例(即由输入和输出组成的训练数据), { ( 1 、 18 ) , ( 2 、 54 ) , ( 3 , 108 ) } \{(1、18),( 2、54),( 3,108)\} {(1、18),(2、54),(3,108)}。每个节点的期望语义用虚线表示,每个程序(或子程序)的程序语义用实线表示。由五个子程序组成的库显示在图的底部,子程序的程序语义显示在图的右下方。如图中粗体箭头所示,由于每个节点具有不同的期望语义,因此它偏好不同的子程序。因此,子代的适应度(例如,绝对误差或均方误差)可以根据所选节点的不同而变化,并且可以更多的适应子代通过在搜索过程中考虑多节点而不是一个随机节点得到。同时,这种方式大大增加了计算量。
在此动机下,本文开发了语义集群操作符 (Semantic Cluster operator,SCO),它在操作中使用多节点,同时减少搜索次数。SCO 的主要思想是使用语义聚类库 (SCL) 来缩小搜索空间,其中程序根据其语义形状进行聚类。具体来说,在初步搜索中,SCO 根据每个节点的期望语义和每个集群的代表性程序的语义之间的语义形状匹配来确定最佳匹配(即,一个有前景的节点和集群),从而缩小搜索空间。之后,在详细搜索中,SCO 通过将选定的节点替换为选定集群的子程序来获得最佳子代,从而对缩小的搜索空间进行仔细检查。由于 SCO 使用聚类,与大多数现有算子相反,它是一种介于监督和非监督学习之间的混合算子。此外,SCO 是一个知识使用算子,因为从初步搜索中获得的关于有希望的节点和集群的信息被用于详细搜索。
本文的主要贡献是展示了如何利用这些思想来实现陡峭的收敛,并提供了一个符号回归算法,可以有效地应用于解决经验建模问题。在下一节中,介绍了背景和以前的研究。第 3 节详细介绍了 SCO 以及基于 SCO 的迭代局部搜索算法 (ILSS)。第 4 节给出 SCO 和 ILSS 的验证。第 5 节给出了两个在土木工程中的应用实例,第 6 节总结了本文的结论和未来的研究方向。
2. BACKGROUND AND PREVIOUS RESEARCH
SCO 是一种利用语义和聚类的算子。因此,在本节开头介绍了语义和聚类的背景。此外,由于 SCO 的目的是实现陡峭的收敛性能,因此其目标与基于语义的算子相同。相应地,在本节的最后,介绍了 SBOs 迄今为止是如何取得陡峭的收敛性能的。
2.1. Background
2.1.1. Syntax and semantics
在计算机科学中, syntax 指程序的表观形式,而 semantics 指程序的行为 [24]。例如,对于一个程序 y = x × x y = x × x y=x×x,其中输入 { 1 , 2 , 3 } \{1,2,3\} { 1,2,3} 提供给 x x x,该程序的语法为 y = x × x y = x × x y=x×x,语义为 1 , 4 , {1,4, } 1,4,。语义的精确数学定义如下 24、28]:
定义 1 设程序为 p p p,其输入为 IN = { i n 1 , i n 2 . . i n n } = \{in_1,in_2 .. in_n\} ={ in1,in2..inn},输出为 s ( p ( i n ) ) s(p(in)) s(p(in)), s ( p ) s(p) s(p) 为所有输入(在 ∀ i n ∈ \forall in∈ ∀in∈ IN 中)的输出集合。
s ( p ) = s ( p ( i n 1 ) ) , s ( p ( i n 2 ) ) , . . . s ( p ( i n n ) ) (1) s(p)={ s(p(in_1)), s(p(in_2)),... s(p(in_n))} \tag{1} s(p)=s(p(in1)),s(p(in2)),...s(p(inn))(1)
句法和语义之间的一个重要关系是它们是一对多的关系。举个简单的例子,一个语义为 { 1 , 4 , 9 } \{1,4,9\} { 1,4,9} 的程序的语法就是无数个(即 y = x × x , y = x / x × x × x , y = 1 × x × x . . . y = x × x , y = x / x × x × x , y = 1 × x × x ... y=x×x,y=x/x×x×x,y=1×x×x...。)。
具有输入 (IN) 和输出 (OUT) 的训练适应度案例可以用来计算程序的语义。在这种情况下,将 s ( p ) s(p) s(p) 和 OUT 输入到距离度量中,如曼哈顿距离或欧氏距离,得到的值与程序的适应度 ( f ( p ) ) (f(p)) (f(p)) 相同,并且这个特性允许语义空间呈现凸形状 [28]。或者,程序语义可以使用随机生成的输入 (INr) 来计算[24]。然而,由于 INr 对应的 OUT 未知,因此该方法计算的 s ( p ) s(p) s(p) 不能直接用于估计 f ( p ) f(p) f(p)。尽管如此,使用这种方法,用户可以生成所需的输入数量,并用于计算语义等价或语义距离 [24]。
2.1.2. Clustering
聚类是一组具有相似属性的对象,聚类是指根据一组对象的相似性对其进行分组的任务 [29]。使用人工神经网络 (artificial neural networks,ANNs) [30] 和决策树 [31] 对数据进行分类的分类器,由于为训练分配了标签,因此属于监督学习的范畴。同时,由于没有分配标签进行学习,聚类属于无监督学习的范畴。
在聚类之前,选择适合该数据类型的相似性度量。例如,如果数据包含连续特征,则一般采用构成闵可夫斯基距离族 ( L p L_p Lp 范数) [32] 的曼哈顿距离 ( L 1 L_1 L1 范数)和欧氏距离 ( L 2 L_2 L2 范数)。此外,在聚类之前需要对数据进行归一化处理。这样可以防止由于每个特征的相似度被不同尺度扭曲而得出错误的聚类结果 [33]。
聚类方法可以分为层次聚类方法和划分聚类方法 [34]。凝聚聚类和分裂聚类等概念已被用于层次聚类,而基于距离、密度和模型的聚类已被用于划分聚类 [34]。由于聚类可以看作是一个优化问题,根据 NFLT [14],并不存在在任何问题中都表现出最佳性能的通用算法,因此应该使用适当的聚类方法来考虑数据特征。
为确定适用于某一问题的聚类方法或参数,应客观评价聚类结果。评价聚类结果的方法分为内部和外部评估,内部评价是一种利用相似性来评价簇的紧凑性的方法,其中可以使用误差平方和 [35] 和轮廓系数 [36]。外部评价是一种基于先验信息(即具有已知标签的数据)评估聚类准确性的方法,该方法使用了Jaccard 指数 37]、Rand 指数[38] 和混淆矩阵 [39]。
2.2. Previous research
表 1 给出了基于 operator 主要概念的 SBOs 发展历程。

2.2.1. Semantic control operator
在布尔问题中,Beadle 和 Johnson[40、41] 试图通过保证种群的语义多样性来提高 GP 的收敛性能。为此,他们开发了语义驱动的交叉(SDC) 和语义驱动的变异 (SDM),产生与父代不同语义的后代。算子使用降序二元决策图(reduced-ordered binary decision diagrams,ROBDD) 来检查父代和子代之间的语义等价性。之后,他们只向种群中添加来自父代的语义不同的子代。通过这种方法,他们能够改善 GP 的收敛和膨胀控制性能。Nguyen 等人提出了语义感知交叉(SAC),它是 SDC 从布尔问题到实值问题的扩展。此外,Uy 等人设计了基于语义相似度的交叉(SSC) [43],限制了用于交叉的目标子树的语义距离。由于在进化过程中能够保证语义的局部性,它们比标准的交叉 (SC)表现出更好的收敛性和泛化性能 [44]。SCC 的发展导致了自适应技术 [45] 和最相似语义交叉 (MSSC) 的发展,可以提高 SCC 的收敛性能 [46]。
2.2.2. Approximating geometric semantic operator
Krawiec 和 Lichocki [23] 试图利用语义空间的凸性来提高 GP 的收敛性能。更具体地说,他们试图产生位于父代语义之间的子代,因为这样的子代比适应度低的父代具有更好的适应度。因此,他们发展了近似几何交叉 (Approximate Geometric Crossover,AGX) [23],从交叉中产生多个子代,然后选择距离片段最近的子代。在 AGX 开发之后,通过修改父程序的一个语法部分来创建具有两个父程序平均语义的子代的部分中间交叉 (Partial Medial Crossover,PMX) [47]被开发出来。虽然这并没有应用到符号回归中,但它在解决一个滑动谜题中表现出了优异的性能。随后,出于与 PMX 相同的目的开发了局部几何语义交叉 (LGX) [48],并将其应用于符号回归。LGX 选择父代的一个公共节点作为交叉点,并用库搜索 (LS) 派生的程序替换该节点。次年,Krawiec and Pawlak[49] 开发了语义反向传播 (SB),可以直接计算目标节点的期望语义,以创建具有用户自定义语义的子代。基于语义反向传播的近似几何交叉算法 (AGXB),利用 SB 和 LS 产生具有两个父代平均语义的子代,其收敛性能明显优于 AGX 和 LGX。Pawlak [50] 开发了一种算子,将 SDC 的概念与 AGX 相结合,使得 AGX 不会产生与父代相同语义的后代。
2.2.3. Geometric semantic operator
Moraglio 等人 [51] 开发了一种几何语义交叉 (GSC),它基于父代的线性组合创建位于父代语义之间的子代。例如,
当 T 1 T_1 T1 和 T 2 T_2 T2 为父程序, α \alpha α 为 0 到 1 之间的实数时,GSC 产生的子代 ( T 3 T_3 T3) 为
T 3 = α T 1 + ( 1 − α ) T 2 (2) T_3 = αT_1 + ( 1-α ) T_2 \tag{2} T3=αT1+(1−α)T2(2)
虽然 GSC 的缺点是子代规模因父代程序的线性组合而呈指数增长,但其优越的收敛性能引起了众多研究者的关注。Moraglio and Mambrini [52] 开发了几何语义变异 (GSM)。由 GSM 导出的子代 ( T m T_m Tm) 表示为
T m = T 1 + m s ( T R 1 − T R 2 ) (3) T_m = T_1 + ms(T_{R1} - T_{R2}) \tag{3} Tm=T1+ms(TR1−TR2)(3)
其中 T 1 T_1 T1 为父程序, T R 1 T_{R1} TR1 和 T R 2 T_{R2} TR2 为共域为 [0 , 1] 的随机实函数, m s ms ms (变异步长)为随机实数。Castelli 等 [53] 设计了局部搜索的几何语义变异 (GSM-LS),是 GSM 的扩展版本。由 GSM-LS 衍生的子代 ( T m − l s T_{m-ls} Tm−ls)表示为
T m − l s = α 0 + α 1 T 1 + α 2 ( T R 1 − T R 2 ) (4) T_{m-ls} = α_0 + α_1T_1 + α_2(T_{R1} - T_{R2}) \tag{4} Tm−ls=α0+α1T1+α2(TR1−TR2)(4)
其中 α 0 , α 1 , α 2 α_0,α_1,α_2 α0,α1,α2 为随机实数. 由于该算子优化了 α 0 , α 1 α_0,α_1 α0,α1 和 α 2 α_2 α2,使得子代语义逼近目标语义,因此表现出比 GSM 和 GSC 更好的收敛性能。Castelli et al. 等 [54 ] 开发了一种能够自调整几何语义遗传规划 (GSGP、采用 GSC 和 GSM 的 GP) 的交叉和变异率的算法,该算法有助于减少 GSGP 中参数优化所需的时间。Nguyen 等[55] 设计了子树级别的几何语义算子来解决 GSGP 的指数级代码增长问题,Chen 等 [56] 开发了角度感知的交配方案,使得 GSC 能够在目标语义附近产生后代。此外,Francisco等 [57] 提出了扩张和聚合方案来减小 GSGP 的子代规模。
2.2.4. Guiding to target semantics
Pawlak 等 [27] 试图直接将程序语义引导到目标语义而不是父代的平均语义。为此,他们设计了随机期望算子 (RDO)。如第 1 节所述,RDO 选择一个随机节点,然后执行 SB 来计算节点的期望语义。这里,在执行 SB 时使用目标语义而不是父代的平均语义。随后,执行 LS,得到语义与期望语义最相似的子程序,并将节点替换为子程序。与 LGX 和 AGX 相比,RDO 具有更好的收敛性能。Pawlak 等人观察到 RDO 的性能依赖于库的特性。这一观察表明,一个库的语义多样性越得到保障,收敛性能越好。同时,随着待搜索子程序数量的增加,RDO 的计算时间也随之增加。Ffrancon and Schoenauer [58] 在搜索过程中考虑了多个期望语义(多节点),与本文类似。为此,他们计算了所有节点和所有子程序的局部误差(即期望语义与子程序语义之间的差异),以得出最佳匹配。Virgolin 等 [59] 发展了一种新的使用线性缩放的 LS 方法 [61]。该方法调整附加在目标节点上的缩放参数,使得所需的语义与备选子程序的语义相似。Nguyen 和 Chu [60] 试图提高 GP 的膨胀控制性能。因此,他们的算子从一个大的程序中选择一个随机的节点,然后用包含与目标节点的期望语义相似的较小的子程序替换子程序。虽然子代的适应度低于 RDO,但程序规模要小得多。
3. METHODS
该部分介绍了语义聚类算子 (SCO) 和基于 SCO 的迭代局部搜索 (ILSS)。 SCO 的目的是在减少搜索次数的同时,通过考虑多节点来实现陡峭的收敛性能。为此,SCO 使用语义聚类库 (SCL) 来缩小搜索空间,其中程序根据其语义形状进行聚类。因此,本节开始讨论 SCL 的生成方法。随后,SCO 和 ILSS 如下进行了详细的阐述。
3.1. Generation of SCL
图 3 给出了 SCL 的生成方法,其中库是用于替代的程序集合,与总体分开管理。SCL 生成的第一步是创建用于估计程序语义的随机输入 (INr)。在该步骤中,设定特征的范围等于适应度案例的范围,并创建 NIN 随机输入。
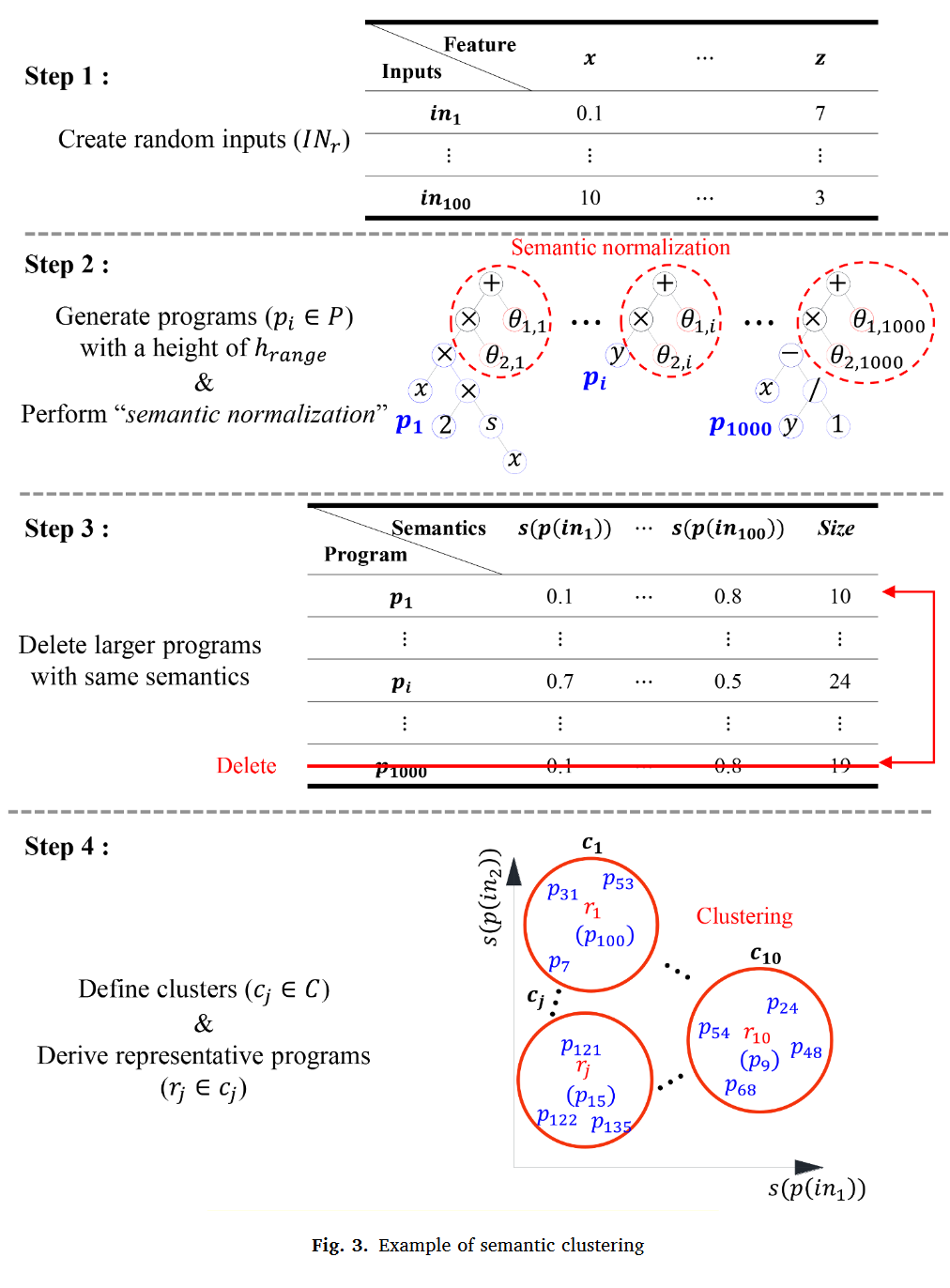
第二步是生成构成 SCL 的程序 ( p p p)。与 RDOp 类似 [27],首先生成高度在 h r a n g e h_{range} hrange 内的 Np 个随机程序,然后从中抽取所有子程序,生成若干个程序 p p p。生成若干个程序 p p p 后,进行语义归一化处理。语义归一化定义如下:
定义 2 设所有可能方案的集合为 P P P,其中 p ∈ P p∈P p∈P; s ( p ) s(p) s(p) 为程序的语义; θ 1 \theta_1 θ1 和 θ 2 \theta_2 θ2 为归一化常数。语义归一化 ( f S N : P → P f_{SN} : P→P fSN:P→P) 是将 s ( p ) s(p) s(p) 的值域缩放为 [0 , 1] 的函数,即
f S N ( p ) = p × θ 2 + θ 1 = p − m i n { s ( p ) } m a x { s ( p ) } − m i n { s ( p ) } f_{SN} (p)= p × θ_2 + θ_1 = \frac{p - min\{s(p)\}}{max\{s(p)\} - min\{s(p)\}} fSN(p)=p×θ2+θ1=max{
s(p)}−min{
s(p)}p−min{
s(p)}
其中, θ 1 = − m i n { s ( p ) } m a x { s ( p ) } − m i n { s ( p ) } \theta_1 = \frac{-min\{s(p)\}}{max\{s(p)\} - min\{s(p)\}} θ1=max{ s(p)}−min{ s(p)}−min{ s(p)}, θ 2 = 1 m a x { s ( p ) } − m i n { s ( p ) } \theta_2 = \frac{1}{max\{s(p)\} - min\{s(p)\}} θ2=max{ s(p)}−min{ s(p)}1
如 2.1.2 节所述,语义归一化可以防止聚类结果被一些大的语义扭曲。此外,语义归一化有助于在后一步减少库大小,因为它使不同规模或位置的程序具有相同的语义。例如, y = x + 1 y = x + 1 y=x+1 和 y = 3 x + 2 y = 3x + 2 y=3x+2 具有不同的语义规模和位置,因为对于 IN = { 1 , 2 , 3 } \{ 1,2,3\} { 1,2,3},语义规模和位置分别为 { 2 , 3 , 4 } \{2,3,4\} { 2,3,4} 和 { 5 , 8 , 11 } \{5,8,11\} { 5,8,11}。通过语义归一化将其转换为具有相同语义的程序 { 0 , 0.5 , 1 } \{0,0.5,1\} { 0,0.5,1},下一步将删除其中一个。
语义规范化完成后,具有相同语义的较大程序优先删除,如步骤 3 所示。其次,基于语义进行程序聚类,从每个聚类 ( c ∈ C c∈C c∈C) 中派生出代表性程序 ( r ∈ c r∈c r∈c),如步骤 4 所示。
值得注意的是,SCL 中的聚类是基于语义形状进行的。例如,当 IN = { i n 1 , i n 2 , i n 3 , i n 4 , i n 5 } = { 0 , 1 , 2 , 3 , 4 } \{in_1,in_2,in_3,in_4,in_5\} = \{ 0,1,2,3,4\} {
in1,in2,in3,in4,in5}={
0,1,2,3,4}时,语义规范化前的程序具有非常广泛的语义,如图 4 (a) 所示,其中每一行表示库中每个程序的语义。但是,经过语义归一化后,程序的语义范围(即 [0,1] )有限,且每个程序的语义用语义空间中有限范围内的点表示,如图 4 (b) 所示。由于程序之间的语义距离具有形状差异,基于距离的聚类方法根据语义形状形成程序簇,如图 4 (c) 所示。

本文采用欧氏距离作为相似性匹配进行聚类,因为语义是连续的特征。由于搜索时需要有代表性的程序而非代表值,因此采用能够导出代表性对象的基于距离的 k-medoids [62] 进行聚类。同时,k-中心的聚类质量根据聚类数目 ( N k N_k Nk)的不同而不同。因此使用在一定范围内产生最大轮廓系数 [36] 的 N k N_k Nk 来生成最终的簇。
3.2. SCO
算法 1 描述了 SCO 的过程。
I Preliminary search:
第 1-12 行表示初步搜索,它是根据每个节点的期望语义和每个集群的代表性程序语义之间的语义形状匹配,通过发现最佳匹配(即,一个有前景的节点和集群)来缩小搜索空间的阶段。第一步,初始化程序存储 ( P ′ P^′ P′) (第一行),将待搜索节点存储在 N N N (第二行)中。这里,第 2 行的 “GET NODES” 是一个函数,它随机且无重叠地返回包含在父程序中的 r n r_n rn% 的节点,其中 r n r_n rn 为节点搜索率。将每个聚类的代表性程序 ( r r r) 输入 R R R (第 3 行)。之后,将一个节点 ( n ∈ N n∈N n∈N) 替换为具有代表性的程序 ( r ∈ R r∈R r∈R) (第 6 行),并使用 Levenberg–Marquardt 方法(LM) 对子代进行常数优化,该方法通常比其他常数优化方法更快 [63] (第 7 行)。将适应度、节点和簇的信息保存在(第 8 ~ 10 行)中,并将子代加入 P ′ P^′ P′(第 11 行)。对所有的 N N N 和 R R R 重复执行第 6 到 11 行。最后,基于适应度得到最优子代 ( p b e s t ∈ P ′ p_{best}∈P^′ pbest∈P′) (第 12 行)。也就是说,以上是一个利用集群的代表性程序得出最佳节点和集群(即 p b e s t . n o d e p_{best}.node pbest.node和 p b e s t . c l u s t e r p_{best}.cluster pbest.cluster) 的过程

II Detailed search:
第 13 至 20 行表示详细的搜索,它是仔细检查最佳匹配的步骤。将 P ′ P^′ P′ 清空(第 13 行),并将 p b e s t . c l u s t e r p_{best}.cluster pbest.cluster 中的程序保存到 S ′ S^′ S′ (第 14 行)。与初步搜索类似,对所有的 s ∈ S ′ s∈S^′ s∈S′ 和一个 p b e s t . n o d e p_{best}.node pbest.node,重复替换(第 16 行)、LM 不断优化(第 17 行)、评估(第 18 行)和添加 P ′ P^′ P′ (第 19 行)。最后,基于适应度(第 20 行)得到最优子代 ( p b e s t p_{best} pbest)。
SCO 的优势如下:
I. 具有更好适应度的子代的衍生:
- i SCO 在搜索时可以考虑多节点。因此,通过一个保证适应度提升最高的有希望节点的可能性降低。
- ii 不同于 RDO 在推导出最佳匹配后进行不断优化,SCO 在寻找最佳匹配的过程中进行不断优化。因此,通过考虑常数的可变性,SCO 可以找到更好的匹配。
Ⅱ.搜索次数的减少:
-
i SCO 可以通过缩小搜索空间来减少搜索次数。例如,父程序 ( p p a r e n t p_{parent} pparent) 包含的节点数为 N p a r e n t N_{parent} Nparent;库中所有程序的数量为 N L P N_{LP} NLP;一个库中的聚类数目为 N C N_C NC;每个集群的平均程序数为 N C P N_{CP} NCP; N L P 、 N C 、 N C P N_{LP}、N_C、N_{CP} NLP、NC、NCP 三者之间的关系如下:
N L P = N C × N C P (6) N_{LP} = N_C × N_{CP} \tag{6} NLP=NC×NCP(6)
在穷举搜索(即全搜索)中,搜索 N p a r e n t × N L P N_{parent} ×N_{LP} Nparent×NLP对,而 SCO 只搜索 N p a r e n t × N L P ( 1 N C P + 1 N p a r e n t × N C ) N_{parent} × N_{LP} ( \frac{1} {N_{CP}} + \frac{1}{N_{parent}× N_C}) Nparent×NLP(NCP1+Nparent×NC1)对, 如下:
N p a r e n t × N C + N C P = N p a r e n t × N L P N C + N L P N C = N p a r e n t × N L P ( 1 N C P + 1 N p a r e n t × N C ) (7) N_{parent}× N_C + N_{CP} = N_{parent} × \frac{N_{LP}}{N_C} + \frac{N_{LP}}{N_C} = N_{parent} × N_{LP} ( \frac{1} {N_{CP}} + \frac{1}{N_{parent}× N_C}) \tag{7} Nparent×NC+NCP=Nparent×NCNLP+NCNLP=Nparent×NLP(NCP1+Nparent×NC1)(7) -
ii 如 3.1 节所述,由于通过语义归一化可以使库大小 (Library size,NLP) 更小,因此可以减少搜索次数。
3.3. Iterated local search with SCO (ILSS)
如算法 1 所示,与原始的交叉或变异算子相比,SCO 需要更多的搜索量 [6]。例如,令 N p a r e n t N_{parent} Nparent 为 30; N C N_C NC 为 30; N C P N_{CP} NCP 取 30;SCO 每次运行需要 930 次计算,与一代原始 GP 的计算量相当。因此,SCO 难以适用于种群规模较大的算法,因此将其用于种群规模为 1 的迭代局部搜索 (ILS)。 ILS 最早是由 Johnson 为解决旅行商问题 (Travelling Salesman Problem,TSP) 而提出的 [64],是一种类似于遗传算法 (Genetic Algorithm,GA) 和模因算法 (MA) 的元启发式算法。ILS 的演化过程是由扰动(突变)和局部搜索组成,而不是选择,交叉、变异。ILSS 遵循 ILS 的算法模式,但在一次进化过程中进行多次局部搜索以增强收敛性能。ILSS 的伪代码在算法 2 中描述,并进行详细说明:
I. Initialization:
- i Program creation: 创建初始程序(第 2 行)。这里,线性缩放被应用到初始程序中,因为具有缩放参数(常量)的程序在不断优化后可以具有高适应度 [63]。
- ii Library preparation: SCL is prepared (第 3 行)。
- iii Initial evaluation: 评估当前程序的训练适应度 ( p i p_i pi) (第 4 行)
II. Evolution :
- i Update p b e s t p_{best} pbest: 根据训练适应度(第 6 行)更新最佳程序 ( p b e s t p_{best} pbest)
- ii Perturbation (Mutation): 由于树表示的结构限制,可达程序依赖于程序的上层结构。这使得算法难以获得较好的程序 [65]。特别地,由于 SCO 基于适应度的改进来修改一个最优节点,因此它更倾向于逐步修改程序的下级结构。因此,上合组织很难修改方案的上层结构或逃避其影响。同时,由于 ILSS 的种群仅由一个程序组成,因此不能使用具有多种上层结构的程序进行进化。因此,ILSS 中使用了具有局部搜索的几何语义变异 (GSM-LS) [53],它可以引入新的上层结构,从而使 SCO 可以利用各种上层结构(第 8 行)。如算法 3 所示,本文中的 GSM-LS 使用一个带有线性缩放参数的随机程序 ( p r a n d o m p_{random} prandom) 而不是 ( T r 1 − T r 2 T_{r1}-T_{r2} Tr1−Tr2)。式 (4) 中,其中 α 1 \alpha_1 α1 为 1.
- iii Preparation of early stopping: 由于 ILSS 执行多个局部搜索,因此需要一个合理的规则来停止局部搜索并防止过拟合。因此在 ILSS 的演化过程中使用早期停止 [66]。在多次局部搜索开始之前,创建一个空列表 ( I v a l I_{val} Ival) 来记录验证适应度的改进(第 9 行);随后,记录 p i p_i pi 的验证适应度和验证集 ( p b e s t , v a l ) (p_{best, val} ) (pbest,val) 的最佳程序(第 10~11 行)。
iv Multiple local searches:

SCO and iterated pruning (IP): 进行多次局部搜索,直到验证适应度的提高连续 P m a x P_{max} Pmax 次失败(第 13 行)。在多次局部搜索过程中,交替执行 S C O 0 SCO_0 SCO0(SCO , rn = 0% ,一次随机节点搜索) 和 S C O 1 SCO_1 SCO1(SCO 以 rn = 100 % ,所有节点搜索)以防止过度贪婪行为 [58] (第 14 ~ 18 行)。此外,由于内含子(非有效节点)通过增加程序规模增加搜索次数,因此在 S C O 0 SCO_0 SCO0 (第 16 行)之后应用迭代剪枝 (IP)。如算法 4 所述,IP 是一个操作符,它重复执行剪枝直到剪枝变得不可能。
B. Recording and update: 在 SCO1 或 IP 完成后,评估子代程序的验证适应度(第 19 行)。随后,在 I v a l I_{val} Ival (第 20 行)记录验证适应度的改进,并更新 p b e s t , v a l p_{best,val} pbest,val 为(第 21 ~ 22 行)。为了进行下一次局部搜索,将 p o f f s p r i n g p_{offspring} poffspring 代入 p i p_i pi (第 23 行),更新 SCL (第 24 行)。只有当一个新的程序被添加到 SCL 时,聚类才会再次执行。
v Elitism: 当多个局部搜索终止时,将 p b e s t , v a l p_{best,val} pbest,val 写入 p i p_i pi 进行下一次进化(第 26 行)。
4. VALIDATION
本部分介绍了实验设置和结果。在 4.1 节和 4.2 节中,验证了在不搜索所有可能解的情况下,SCO 是否得到优秀的子代。此外,还分析了参数对 SCO 搜索性能的影响。在 4.3 节和 4.4 节中,将 ILSS 与其他算法的性能进行了比较。
4.1. Experimental setup for parametric research and validation of SCO
4.1 节和 4.2 节要观察的要点是是否 SCO 能够产生良好的子代,减少穷举搜索的计算负担。据此,对最优程序 ( R p R_p Rp , %) 和计算次数 (T , sec) 的相对适应度排序进行了度量。在这种情况下, R p R_p Rp 表示 SCO’s 子代在穷举搜索得到的方案中的相对适合度排名。用于测量 T T T 的计算平台规格如下:RAM,40.0 GB;Cpu,Intel ® core ™ I5-9400F Cpu @ 2.90 Ghz。
虽然 R p R_p Rp 可以用来验证 SCO 是否可以找到好的子代,但是这并不能告诉我们 SCO 是否通过遵循设计目的产生好的子代。因此,有必要对作为 SCO’s 核心步骤的初步搜寻进行验证。为此,对有前景节点 ( E n E_n En , %) 的估计误差进行了如下度量:
E n = r e x − 1 N p a r e n t − 1 × 100 ( % ) E_n = \frac{r_{ex} - 1}{N_{parent} - 1} × 100(\%) En=Nparent−1rex−1×100(%)
式中: r e x r_{ex} rex 表示基于穷举搜索的有希望节点的实际排名,分子中的 1 表示有希望节点的估计排名。因此,分子表示估计误差,分母表示最大误差。此外,为了确定 SCO 是否也评估了所有节点的优先级,还测量了所有节点的估计排名与实际排名之间的皮尔逊相关系数 ( ρ ρ ρ)。
表 2 给出了用于验证的实验装置汇总。
由于 SCO 是基于聚类的算子,维数灾难 [67] 会影响其性能。因此,使用投入数量 ( N I N N_{IN} NIN) 作为检验变量,将其设置为 10、100、1000。此外,由于聚类数目 ( N k N_k Nk) 影响聚类结果,将其设置为 10、30、50 作为第二个测试变量。为了观察特征数量的影响,实验中使用了具有 1 个、4 个和 7 个特征(Septic, Faculty salaries, Compressive strength)的基准数据集。最后,根据节点搜索率 ( r n r_n rn) 检查性能变化, r n = 0 r_n = 0 % rn=0 (随机节点搜索, SCO0)、50% ( SCO0.5)、100% (SCO1)用于测试。每个参数进行 30 次实验。

6. CONCLUSIONS
6.1. Conclusion
遗传规划下的符号回归在结构工程等工程领域中用于推导经验模型是有用的,但由于收敛性能低,其应用受到了阻碍。为了克服这一局限性,本文设计了一种新的搜索策略——基于语义簇的搜索。开发了使用该策略的算子 (SCO) 和算法 (ILSS),并对其行为和性能进行了实验验证。由于该算法提供了一个简洁的模型,在少量的搜索中具有较高的精度,因此有望在需要可解释模型的工程领域中发挥作用。本研究得到以下结论:
- 1 陡峭收敛的主要思想是在考虑多节点的同时通过缩小搜索空间来减少搜索次数。为了缩小搜索空间,在 SCO 的运行过程中,程序个体被基于语义聚类的 SCL 使用。在初步搜索中,SCO 通过推导节点和簇的最佳匹配来缩小搜索空间,在详细搜索中,SCO 对最佳匹配进行仔细检查。
- 2 在 SCO 的实验中,发现 SCO 的计算时间是穷举搜索的 6%,并且 SCO 的子代适应度在穷举搜索的所有子代中位于前 0.5%。
- 3 在参数研究中,证实了 r n r_n rn 和 N K N_K NK 提高了 SCO 的性能,但提高 T. N I N N_{IN} NIN 的影响不一致,每个问题的最优 N I N N_{IN} NIN 不同。
- 4 在基准测试中,ILSS 分别在收敛性、泛化性和膨胀控制上表现出第 2、第 2 和第 1 的最佳性能。ILSS 也被应用于土木工程中的两个经验建模问题。所得模型简单,且与 SVM、ANN 和 RF 等黑箱模型相比具有较高的精度。
6.2. Future research and limitations
在本研究中,通过 SCO、early stopping, and IP 可以获得高精度的简洁模型。然而,由于早期停止和 IP 严格禁止程序增长,因此很难训练出高复杂度的问题。虽然这个问题可以通过调整提前停止的耐心来解决,但它需要关于复杂性的先验知识。为了克服这种局限性,在未来的研究中需要实现一种新的 bloat control method。
另一个局限性是由于程序中常量的变化,SCO 的初步搜索受到语义变化的影响。假设代表性程序中的某个程序可以通过改变其常量而具有非常多样的语义形状。当这样的程序显著改变其语义形状,并被选为初步搜索中的最佳匹配时,从图 5 和 7 中的异常值可以观察到搜索可能会失败。这是因为同一集群中的程序很难与变化后的代表程序具有相同的语义形状。因此,在未来的研究中,有必要发展选择语义可变性有限的代表性程序的方法。
7. DATA AVAILABILITY STATEMENT
The algorihms can be found online at https://github.com/HoseongJeong.
References
Jeong H, Kim J H, Choi S H, et al. Semantic Cluster Operator for Symbolic Regression and Its Applications[J]. Advances in Engineering Software, 2022, 172: 103174.