ABSTRACT
语义反向误差传播网络 (SB) 是最近在基于树的遗传编程中促进有效变异的技术。SB 的基本思想是通过使用沿途遇到的函数的倒数将期望的根节点输出传播回指定的节点,从而提供关于指定树节点期望输出的信息。然后,变异算子通过在预先计算的库中搜索,将位于指定节点的子树替换为输出最接近期望输出的树。本文结合 Keijzer’s Linear Scaling (LS) 的原理,针对符号回归提出了两个增强 SB。特别地,我们展示了 SB 如何与比例均方误差协同使用 (synergy with the scaled mean squared error) ,以及 LS 如何在库搜索中使用。我们使用著名的变异算子随机期望算子 (Random Desired operator,RDO) 来测试我们的适应性,并与它的基线实现以及传统的交叉和变异进行比较。我们在真实数据集上的实验结果表明,LS 增强的 SB 显著提高了 RDO 的性能,从而在整体上获得了所有测试 GP 算法中最好的性能。
1 INTRODUCTION
语义反向误差传播网络 (SB) 是基于树的遗传编程 (GP) [14、20] 中的一项新技术,它可以设计新的变异算子 [19、26]。对于任意树节点,给定树的目标输出,SB 决定该节点的期望输出。如果将节点替换为传递期望输出的子树,那么祖先节点的输出也会发生变化,最终使得根节点传递目标输出。基于SB的GP算法的应用已被证明在 Boolean circuit synthesis 和符号回归[8、15、19] 等监督学习应用中特别有效。
基于SB的变异算子通过将节点替换为与期望输出尽可能匹配的子树来修改树。随机期望算子 (Random Desired operator,RDO) 也许是其中最有名的,因为它已被证明在各种问题 [19、26] 上表现最好。RDO 的关键部分是使用具有预计算输出的树库(library of trees),以及一个库搜索过程来检索与期望输出最匹配的树。
对于库 (library) 而言,有两种传统的构建方式 [19]。第一种方式是在一个最大树高内生成所有可能的树,并为每个唯一输出保留一棵树(保留的为节点较少的树)。显然,这种方法不能随维数的多少而缩放,也不能随实值常数的采样而缩放。在文献 [19] 中,对于具有单一特征的问题,最大高度为 3 已经产生了数十万棵树。第二种方式是每一代动态刷新库 (dynamically refresh the library every generation),通过包含种群中观察到的所有具有唯一输出的子树。这种方法的缺点是,库 (library) 的表现力可能是有限的,因为它是以种群如何演变为基础的。
线性缩放 (Linear Scaling,LS) 是一种有趣的现有技术,通过对树 [12、13]的输出应用最优线性变换来最小化 GP 树的均方误差。虽然通常用于提高适应度,LS 可以更普遍地应用于需要最小化两个输出之间的距离的场景(欧氏空间的单调变换)。由于基于 SB 的 GP 通过匹配期望的输出来运行,因此有理由认为某种形式的 LS 可以集成到算法中。这正是本文的主题:我们研究如何最好地集成以及如何最好地观察 LS 对基于 SB 的 GP 的影响。
我们首次提出使用 LS 作为
- (i) 单独但协同的机制与 SB 一起工作;
- (ii) 一个联合机制,在基于 SB 的 GP 中使用,即在库 (library) 搜索过程中。
以前的许多工作只考虑了少变量的合成基准函数 (synthetic benchmark functions),以及 generational computation budgets (见 Sec.3)。与其他形式的 GP 相比 (例如, 传统的 GP 随机交换和变异子树),后者可能更倾向于基于 SB 的 GP,因为它不考虑 SB 本身、库构建和库搜索所花费的计算时间 [19]。因此,在我们的实验中,我们从 generations 和 time 两个方面评估了所提出的 LS 增强的基于 SB 的 GP 的有效性。此外,我们在真实的中小型回归问题上对算法进行了测试,使用了十个 real-world benchmark datasets.
2 SEMANTIC BACKPROPAGATION,SB
给定树中 root 的目标输出 t (i.e., for its root),SB 计算一个特定节点 N N N 的期望输出 d N d^N dN。然后可以使用这些信息将 N N N 替换为输出尽可能接近 d N d^N dN 的子树。预期子树的输出越接近 d N d^N dN ,根的输出越接近 t。
设 D D D 为 N N N 的深度. 那么 N N N 有 D D D 个祖先。设 A k A_k Ak 是 N N N 在深度 k k k 的祖先. 类似地,设 S k = { S k 1 , S k 2 , . . . } S_k = \{S^1_k,S^2_k,... \} Sk={ Sk1,Sk2,...} 是 A k A_k Ak 的兄弟节点集合(可能是空的)。为了简洁起见,我们现在使用与指一个节点相同的符号来标识该节点实现的功能。例如: A k ( x , S k + 1 ) A_k( x , S_{k + 1}) Ak(x,Sk+1) 表示节点 A k A_k Ak 的函数在 x x x 上的应用,和在节点 S k + 1 S_{k + 1} Sk+1 上的输出。因此,SB 计算如下:

- 注: N N N 为特定节点、 d N d^N dN 为特定节点 N N N 的期望输出、 A k A_k Ak 是 N N N 在深度 k k k 时的祖先节点, S k = { S k 1 , S k 2 , . . . } S_k = \{S^1_k,S^2_k,... \} Sk={ Sk1,Sk2,...} 是 A k A_k Ak 的兄弟节点
式中: A k − 1 A^{-1}_k Ak−1 表示函数 A k A_k Ak 求逆或倒置 (inversion)。SB 通过将期望的 output 设置为目标从 root 开始 (即 d A 0 : = t ) d^{A_0} := \text{t}) dA0:=t)。N (在深度 D 处)的期望输出的递归计算如下: d N = A D − 1 − 1 ( d A D − 1 , S D ) d^N = A^{-1}_{D-1}(d^{A_{D-1}},S_D) dN=AD−1−1(dAD−1,SD)。图 1 给出了一个实例。

- 图 1:SB 为黄颜色节点的例子。各节点的当前输出均为粉红色。期望输出为蓝色。root 的期望输出是目标输出(给定的),其余的通过递归求逆计算到黄叶节点的路径。右上角的操作描述了这个例子中使用的 inversion.
注意到,如果函数集中包含非内射函数 (例如:abs()),则每个期望输出向量都将增长以表示不同的可能结果,即 d ∈ R γ × n ∈\Bbb{R}^{γ × n} ∈Rγ×n 和 di = { d i 1 , . . , d i γ } = \{d^1_i,..,d^γ_i\} ={ di1,..,diγ},其中 i = 1 , . . , n i = 1,..,n i=1,..,n 为训练样本的索引 (为了简单起见,我们将上标 N N N 从 d N d^N dN 中删除)。注意到 γ γ γ 可以是 ∞ ∞ ∞,例如对于 sin(). 类似地,任意值可以满足一些逆定理 (inversions):例如,对于 x = × − 1 ( 0 , 0 ) , 0 × x = 0 , ∀ x ∈ R x = ×^{-1}( 0,0 ), 0 × x = 0, \forall x∈ \Bbb{R} x=×−1(0,0),0×x=0,∀x∈R. 在这种情况下,我们将指出任意值在 * 下是都是表现良好的. 我们在下面的 2.1 节中描述了在库搜索过程中如何处理具有多个 * 值的 d i d_i di。反之,某些函数某些点在 R \Bbb{R} R 中处不可逆 (例如, ( ⋅ 2 ) − 1 ( − 1 ) = − 1 (·^2)^{-1}(-1)=\sqrt{-1} (⋅2)−1(−1)=−1) ,因此某些 d i j d^j_i dij 可能不存在。如果 SB 不可行,即 ∃ i : d i = ∅ \exist i:d_i = \empty ∃i:di=∅,则中止 SB (如文献 [19])。
2.1 Library and library search
给定期望输出 d,寻找具有相似输出的子树。为此,典型的基于 SB 的变异算子依赖于具有唯一输出的预计算树的可搜索库。正如在引言中提到的,构建库的一种方法是预先计算所有可能的树的最大高度,但这在有很少的 features (terminals) 中变得难以解决[19]。另一种典型的方法是收集种群中观察到的所有子树(每一代更新) [4,22]。
在所谓的 “population-based” 的库中,如果种群中存在多个具有相同输出的子树,则保留节点数最少的子树。此外,恒定输出的子树不考虑 (库搜索单独处理常量,见下文)。
库搜索过程对库进行解析,找到使其输出 o 与 d 距离最小的树,如修改 L1 或 L2 距离 (或者任意的 Minkowski 距离)。通过修改距离,我们意味着必须考虑 d i d_i di 的多值性。距离可以通过寻找使 ∣ d i j − o i ∣ w , ∀ w ∈ { 1 , 2 , . . } |d^j_i-o_i|^w, \forall w∈\{ 1, 2, .. \} ∣dij−oi∣w,∀w∈{ 1,2,..} 最小的一个 d i j d^j_i dij 来计算[19]。更进一步地,如果 ∃ j : d i j = ∗ \exist j:d_i^j = * ∃j:dij=∗,则 d i d_i di 的值无关紧要,定义为 ∣ ∗ − o i ∣ w = 0 | *-o_i|^w = 0 ∣∗−oi∣w=0 . 通过对 j j j 中的 d i j d^j_i dij 进行预排序,可以在 O ( ∣ l ∣ n l o g γ ) O( | l | n log γ) O(∣l∣nlogγ) 中解析出一个线性可寻址库 l \mathscr{l} l [19]。
当具有常数输出的树通常被排除在库之外时,库搜索进一步以单独的方式考虑常数值与期望输出之间的距离。在文献 [19] 中,d 的值被认为是候选的常量值,并从中选出最优的值。在库中找到的最佳树,或实现最佳常数的单个节点,最终由库搜索过程返回,这取决于最接近 d 的节点。
2.2 Random Desired Operator
RDO 通过在一个子树中生成与父树不同的子树来工作。RDO 的伪代码如算法 1 所示。首先,将子代 ( O O O) 创建为父代 ( P P P) 的克隆,并选择其中一个节点 N N N。文献 [19] 提出以等深度概率 (equal depth probability) 准则选取 N N N,先考虑采样深度 D D D,然后在深度为 D D D 的节点中随机均匀采样 N N N。其次,对 N N N 执行 SB,通过设定根到因变量的目标进行回归,即 t : = y t:= y t:=y。注意,一般情况下,t 可以不同(例如, 文献提出了一种交叉算子, 将一个父代的目标输出设置为另一个父代的输出)。如果 SB 因为计算了一个不可行的 d 而中止,RDO 返回父代的克隆。否则进行库搜索,得到与 d 距离最小的输出树 T。最后,RDO 返回子代,通过将 N N N 处的子树替换为 T 进行调整。

- 注: t 为目标输出
2.3 Intermediate output caching
如果子树的输出被缓存,基于 SB 的 GP 特别有效。特别地,SB 的每次递归迭代都需要知道兄弟节点的输出, 而库搜索需要库树(library trees)的输出。因此,文献 [19] 提出缓存中间树输出,即所有节点的输出。
中间输出缓存不仅加快了 SB 相关的方法,也加快了树的传统评估。事实上,如果一个节点被改变,仅仅沿着祖先链重新计算输出就足够了,即从该节点的父节点向上,得到根节点的输出。虽然这些部分评估可以是非常有效的,特别是对于高维输出,它们在内存方面付出了代价。(参见中关于可扩展性的讨论 [24] )
3 RELATED WORK
与本文相关的研究线主要有两条,即 LS 和 SB 。至于 LS,迄今为止被引用最多的工作是 [12],它展示了 LS 如何显著提高 GP 的性能,对于多达 3 个变量的合成函数。文献 [13] 给出了 LS 增加值的理论动因。LS 已成功用于实际应用,如 [1 , 21 , 23]。
据我们所知,目前还没有提出修改 LS 本身的贡献。这并不奇怪,因为 LS 是快速的(即 O ( n ) O(n) O(n) ),而伸缩和平移系数是因变量 y y y 的最优 w . r . t . w.r.t. w.r.t. (见 Sec 4.1 中对 LS 的描述), 也许更有趣的是,我们也找不到任何工作将 LS 与另一种方法以真正协同的方式结合起来,即让 LS 和或另一种方法彼此共享信息。例如,在 [5] 中,LS 与特定的匹配方案一起使用,但这两种方法相互独立地共存。在这里,我们首次考虑使用与另一种方法深度交织的 LS, eg SB.
对于 SB,它在文献 [26] 中首先与 RDO 一起被引入,随后大量的研究工作相继展开。也许最全面的贡献之一是 [19],它比较了几种变异算子,其中两种是基于 SB 的(RDO 和近似几何交叉)。在布尔问题和回归问题上,RDO 被证明优于大多数其他算子
而 RDO 使用 SB 替换子树,文献 [22] 提出的前向传播变异 (FPM) 算子则相反:保留子树,替换树的剩余部分,称为上下文。 通过确定一个新的根和附加到根上的另一个子树来构建一个新的上下文,该子树与保留的子树是一个同胞。这个新的子树通过使用余弦相似性的库搜索来检索,并通过一个最优常数(在O(n)中确定) )来重新调整。作者认为,在 FPM 的库搜索过程中,一种替代方法是使用 LS 来确定 translation coefficient 。对于 RDO 而言,这在我们的工作中确实得到了研究。
最近,在文献 [3] 中提出了 FPM 的一个变体,其中目标被设置为 y 和父代的输出之间的一个随机点,其中 LS 应用于库搜索后。虽然这提高了子树对上下文的拟合,但与在库搜索(正如文献)时考虑最优 translation coefficient 相比,它的效率较低(但速度更快)。
尽管前面提到的和基于SB 的 GP (例如 [8,11]) 的其他工作的新颖性和优势,正如我们在引言中提到的,到目前为止,在回归领域中考虑的大多是合成函数。这些函数最多只有三个变量。此外,比较只考虑了世代数,因此忽略了基于 SB 的 GP 的大部分计算开销。
据我们所知,仅在文献 [3] 和文献 [4] 中分别考虑了使用 RDO (和一个变体)和上述 FPM 变体的 GP 的 4 个和 2 个真实基准。再次,除了文献 [3] 的补充材料,只考虑了世代预算,其中使用了时间限制的实验,尽管这些结果不可否认地带来了额外的见解,但我们认为仍然很难评估使用基于 SB 的算子对计算时间的影响,因为有两个原因。首先,使用相对较小的种群规模 100,这意味着基于种群的 library 也将是小型和快速解析的。其次,所考虑的 GP 算法存在多个差异(例如,选择方案),且总是与基于 SB 的算法一起使用其他变异算子。
在本文中,我们不仅考虑了如何将 LS 与基于 SB 的 GP 相结合,还试图解决相关工作的主要局限性。我们采用了十个真实的基准数据集进行回归,其中有几十个特征,因为它们可以更多地代表实际问题,并且我们试图从代数和时间限制两个方面进行算法比较,以观察采用基于 SB 的 GP 的潜在开销。
4 LINEAR SCALING WITH SB-BASED GP
我们现在描述本文的第一个贡献,即 SB 如何与 LS 协同发挥作用。LS 的主要思想是通过提供最小化训练均方误差( Mean Squared Error,MSE )的平移和缩放系数 [12] (如图2),让 GP 专注于函数的"形状"进行逼近。
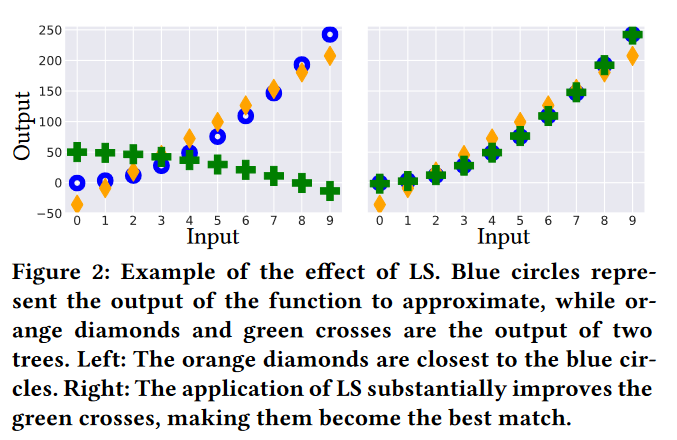
- 图 2: LS 效果示例。蓝色圆圈代表函数的输出来近似,而橙色菱形和绿色十字是两棵树的输出。左:橙色钻石最靠近蓝色圆圈。右:LS的应用使绿色组合得到了大幅度的提高,成为最佳搭配。
原则上,LS 和 SB 可以独立工作,不需要对两种方法进行更改,在 RDO 中,SB 通过设置目标 t(即根的期望输出) 到 y 来工作,反向传播这些信息意味着直接尝试优化树以准确地传递 y,而不利用 LS 有助于扩展根的输出这一事实。换句话说,在这种情况下,LS 在基于 SB 的 GP 上只充当"补丁",因为它试图修正算法通常产生的残差。
我们认为,试图使 LS 和 SB 协同发挥作用以减少误差是合理的,特别是通过告知 SB , LS 的效果如何。事实上,我们假设,如果 LS 应用的变换也被反向传播来确定期望输出,那么后续的变化将更加有效,因为它将试图修正 LS 应用后仍然存在的误差。
4.1 Linear scaling
LS 的工作原理如下。令因变量 y 与树输出 o 之间的 MSE 作为回归的适应度函数:
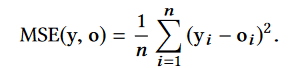
LS 引入了尺度化的均方误差,在均方误差的计算过程中分别使用平移系数 a 和缩放系数 b 来最小化均方误差:

使误差最小的最优 a 和 b 为(见 [12] ):

式 2 的实现。取 O ( n ) O(n) O(n) .
4.2 Linear scaling in synergy with semantic backpropagation
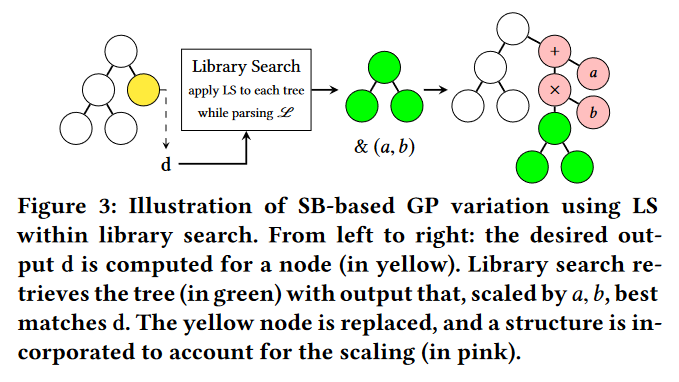
我们现在描述 LS 和 SB 如何协同发挥作用。首先,我们指出使用 MSE a , b ^{a,b} a,b 等价于在一棵树上使用传统的 MSE,其中 a 的加法和 b 的乘法都编码在树本身,合适的节点放置在根的顶端。例如,考虑图 3 中最右边的树:忽略白色的节点,并将加号的节点想象为实际的根。该树实质上是在其结构(粉红色节点)中包含 LS 效应的树。对于这样的树,计算 SB (如Sec . 2 )是很简单的。特别地,我们立即看到,对于一个目标输出 t,原根(顶端绿色节点)的期望输出为:

因此,每当需要执行 SB 时,我们可以根据 t 和当前树输出 o (或者, 如果 t = y 类似于 RDO ,那么 a 和 b 可以在计算出 MSE a , b ^{a , b} a,b (y , o) 后被缓存) )。然后我们可以利用公式 (3) 计算根的 d, 作为 SB 的起点,然后我们通常可以继续使用方程 1。
我们注意到以这种方式将 LS 包含在 SB 中的计算开销可以忽略不计。如果 D 是选择替换的节点的深度,那么 SB 需要计算 D 个反演。如果只考虑内射函数,则有 O ( D n ) O(Dn) O(Dn) (如果存在非内射函数,它是 O ( D γ D n ) O(DγDn) O(DγDn)) ,在典型的符号回归设定中, D D D 被一个很小的常数所限制, n n n 很大。即. D ≪ n D \ll n D≪n,即界为 O ( n ) O(n) O(n) .由于将 LS 与 SB 协同包含在计算方程 2 和计算方程 3,并且由于这些计算只带来额外的 O ( n ) O(n) O(n) 个贡献,因此该界保持为 O ( n ) O(n) O(n)。
5 LINEAR SCALING WITHIN SB-BASED GP
在执行库搜索时,寻找一个输出 o 接近期望输出 d 的树 T。这种情况类似于符号回归问题本身,即期望根节点的输出与 y 相匹配。由于已知 LS 在后一种场景 [12、13] 中有所帮助,因此可以合理地预期 LS 也可以提高库搜索的有效性,并考虑最优比例的树输出。
5.1 Linear scaling during library search
令 L 2 L2 L2 为库搜索过程中采用的距离度量。由于 L 2 L2 L2 是均方误差的单调变换,因此最优系数 a a a 和 b b b 可由公式 2 计算得出 (用 d 代替 y),减小 d 和 o 之间的距离。在实际中,d 需要在 R n \Bbb{R}^n Rn (而不是在 R γ × n \Bbb{R}^{γ × n} Rγ×n 中) 中才能有唯一的、定义良好的方式来计算 a 和 b。例如,如果存在多个值的 d i d_i di,则 d ˉ \bar{d} dˉ 是什么? 对于 d i d_i di (例如,考虑其他具有唯一值的 d j d_j dj 时给出的最接近均值的值),应采用一定的准则选择其中一个值。通过为每个 d i d_i di 选择一个值来限制期望输出的多维性,意味着不会搜索到库中可能存在的更好匹配输出。或者,可以计算多个缩放并取最佳缩放,但可能存在指数可能性。在本文中,我们在 GP 的函数集中包含一个关于零点对称的非内射函数。对于其反演,我们选择只返回正值(见Sec . 6 )。关于 * 值,我们假设,如果存在,它们很少,在计算 a 和 b 时可以忽略。
因此,我们评估了在图书馆搜索中使用 LS 的效果。每当执行库搜索时,对于库中的每棵树,我们计算最优的 a 和 b 系数,使得树的输出与期望输出之间的距离最小。库搜索然后返回最佳匹配树及其 a、b 系数。当这棵树需要通过变异算子进行追加时,在其根的上方添加 4 个节点,即两个分别为 a 和 b 值的常数,一个加法节点和一个乘法节点,以有效地将缩放纳入树的结构中。图 3 展示了这一过程。
LS 的计算时间为 O ( n ) O(n) O(n),与库中树的输出到 d d d 的距离计算时间 w.r.t 相加。因此,库搜索界保持为 O ( ∣ L ∣ n ) O(|\mathscr{L}|n) O(∣L∣n)。在实际应用中,可以做一些调整以减少计算量。一旦库被创建,每棵树输出 o ˉ \bar{o} oˉ 的均值可以被缓存,以及 ( o i − o ˉ ) ( o_i - \bar{o}) (oi−oˉ) (见 Eq.2 )项。此外,在开始库搜索之前,只需计算一次期望输出 d ˉ \bar{d} dˉ 的均值和 ( d i − d ˉ ) (d_i - \bar{d}) (di−dˉ) 项。这样,搜索时剩下的唯一代价为 n n n 的线性运算就是计算式 2 中 b 的分子。
最后,当在库搜索中使用 LS 时,我们也改变了计算竞争常数的方式:将常数设置为最优值,即 d ˉ \bar{d} dˉ。
6 EXPERIMENTAL SETUP
GP 的参数设置如表 1 所示,是文献 ([20] , Sec 3 的相关工作) 中使用的典型设置。函数 ÷ A Q ÷_{AQ} ÷AQ 为解析商[18],可实现无间断光滑划分(分母永远不能变为0)。所考虑函数的反演结果报告在表 2 中。注意,在 ÷ A Q ÷_{AQ} ÷AQ 对 a j a_j aj 求逆时,我们只返回正值。终端集包括一个短暂随机常数 (Ephemeral Random Constant,ERC) [20],具有产生具有随机常数输出的节点的作用。这些恒定输出在特征的最小值和最大值(在训练时可用)定义的区间内均匀采样。
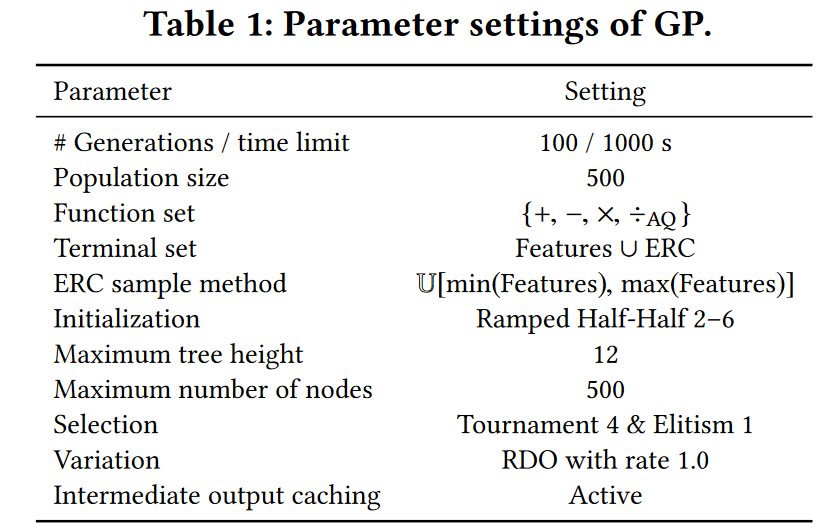
与使用 RDO 的 SB-GP 一起,我们考虑使用标准子树交叉和子树变异算子 (SGP) [14、20] 作为基线 GP,分别在每代 90% 和 10% 的种群上应用它们。与 RDO 一样,交换/变异的节点是以等深度概率选择的,如 [19]。
与 RDO (本质上是 O(1)) 相比,SGP 算子的计算时间要少得多,特别是后者需要构建树库,并执行 SB 和库搜索。因此,我们考虑了 100 代的极限和 1000 秒的时间相关极限。由于基于时间的比较在很大程度上依赖于实现细节,我们试图通过在同一个 C++ 代码库中开发所有算法来提高它们的保真度,代码地址: https://github.com/marcovirgolin/GP-GOMEA
我们考虑10个真实的基准回归数据集,其样例和特征的数量是可变的,如表 3 所示。文献 [25] 推荐数据集 Dow Chemical 和 Tower 作为基准。其余的常见于GP文献中,来源于UCI机器学习库1。这些数据集可以被认为是"行为良好"的,因为只有当学习到非常复杂的模型,或者使用具有不连续性的函数(例如,受保护的分割)时,才会出现对训练的过度拟合。对于给定的运行,我们采用典型的 75% ~ 25% 的随机分割将样本分为训练集和测试集。
每个实验由 30 个独立的实验组成。为了评估一个实验的结果是否显著优于或差于另一个实验,我们使用非参数 Wilcoxon 符号秩检验 [6],随机种子配对运行。随机种子决定了训练-测试分割和初始种群的抽样。我们说如果统计检验的 p 值小于,则结果是显著的一个阈值 τ τ τ. 我们取 τ = 0.05 τ = 0.05 τ=0.05,并进一步应用 Bonferroni 校正方法,以防止假阳性 [6]。
实验在两台 Intel ® Xeon ® CPU E5-2699 v4 @ 2.20GHz,内存 630GB 的机器上进行。使用中间输出缓存需要大量的内存,因为单次运行已经可以使用几GB的内存。
7 RESULTS
我们通过展示以下实验的结果来进行。首先考虑与单独使用 LS 相比,LS 与 SB 协同使用是否有利。其次,我们将 SB-based GP 的所有配置与 SGP 进行比较,固定最大代数,观察所花费的时间。第三,我们重复了之前的实验,但这次采用固定的时间预算,以考虑到计算代价。
7.1 Independent vs synergetic linear scaling with semantic backpropagation
表 4 给出了基于 SB 的 GP 在无 LS(noLS)、有 LS 但独立于 SB(iLS)、LS 与 SB 协同(sLS) 下找到的在运转 100 代后最佳树所得到的 median error 。 以方差的形式报告结果归一化均方误差( NMSE ),通过将 MSE 除以因变量 y 的方差,得到相似数量级的结果,并乘以 100。
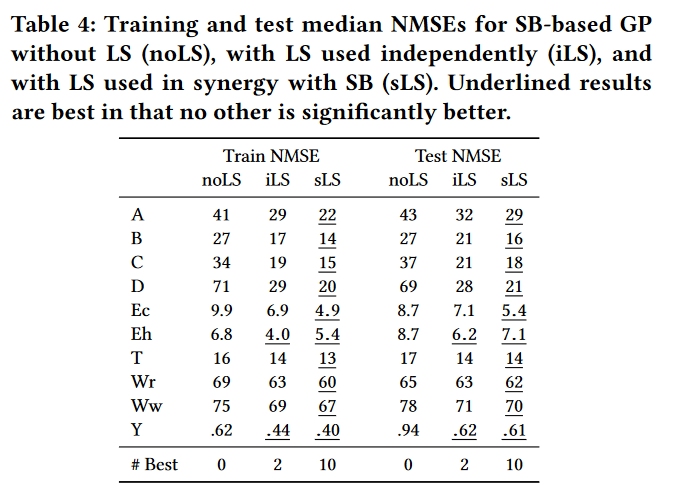
- 表 4: 不使用 LS(noLS)、单独使用 LS(iLS) 和 LS 与 SB 联合使用 (sLS) 的基于 SB 的 GP 的训练和测试 NMSE 中位数。下划线的结果最好的是没有其他明显更好。
显然,iLS 比 noLS 具有更好的训练和测试性能。这在训练 NMSE 时总是显著的,在除波士顿测试时间外的所有数据集上也是显著的。然而,LS 与 SB 协同使用的效果更好,在 8/10 的数据集上训练和测试时间都显著优于 noLS (所有情况)和 iLS。我们的假设,即使用 LS 协同 SB 是有益的,因此在实验上得到证实。
7.2 SB-based GP vs standard GP
接下来的结果展示了 SB-based GP 与 SGP、使用 LS 和不使用 LS 来衡量误差和库内搜索的。我们首先考虑一个 100 代的极限。
7.2.1 Budget of 100 generations.
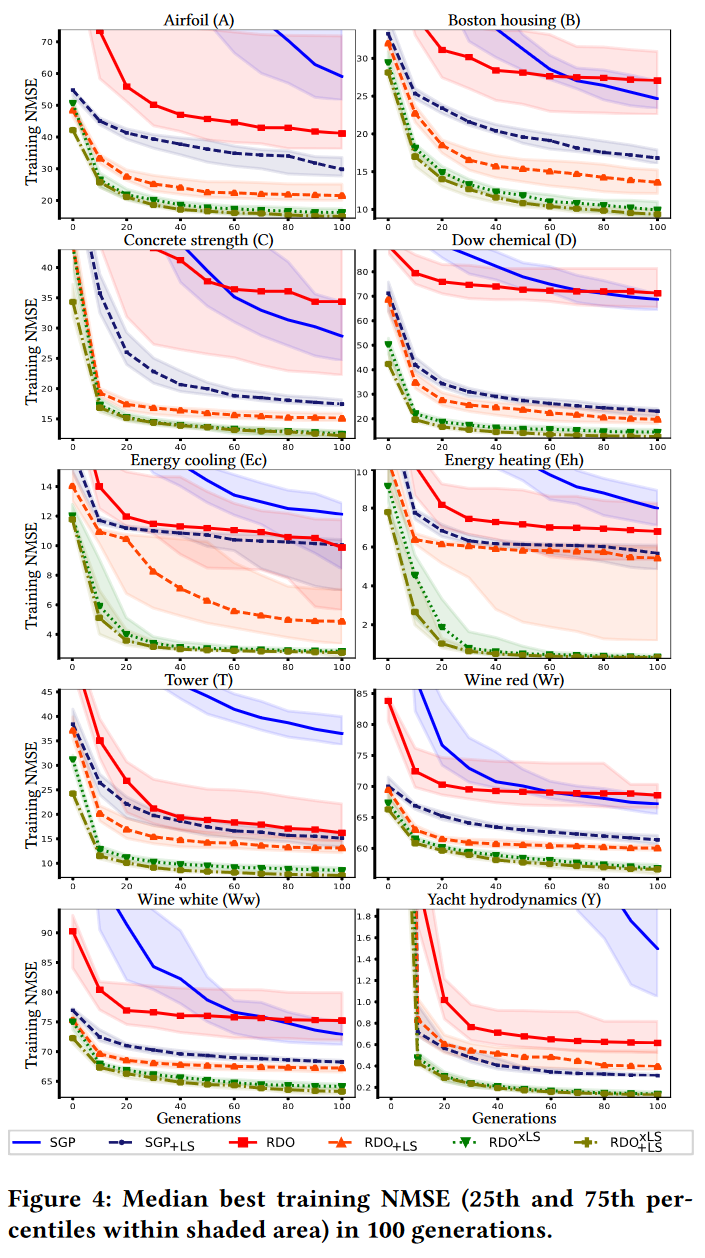
图 4 显示了对于每个数据集,SGP、SGP + LS ( SGP + L S _{ + LS} +LS )、基于 SB 的 GP + 传统 RDO ( RDO )、LS 协同反向传播的 RDO(RDO + L S _{+ LS} +LS)、LS 库内搜索的 RDO (RDO{xLS} )以及 LS 协同反向传播和库内搜索的 RDO( RDO + L S x L S ^{xLS}_{+LS} +LSxLS) 的最佳训练适应度的演化。
RDO 和 SGP 是互补的:一个在半个数据集上优于另一个。然而,在 Tower 和 Yacht 上,SGP 的误差要大得多。值得注意的是,在某些情况下(Airfoil, Boston, Concrete, Wine white, Yacht),SGP的误差水平比RDO的误差水平下降得更少,因此更大的世代预算可能有利于SGP。除Yacht外,RDO + LS 在所有数据集上都优于 SGP + LS。
RDO{xLS} 和 RDO + L S x L S ^{xLS}_{+LS} +LSxLS 的表现始终是最好的,第二个比第一个达到略小的误差。此外,两种算法均比 RDO + L S _{+ LS} +LS 具有更小的方差。这是因为在库内搜索 (xLS) 中使用 LS 动态地提高了库对搜索到的任何期望输出的表达能力。在没有 xLS 的情况下,库的表达能力更加随机,因为它只依赖于来自种群的子树。
表 5 展示了 run 结束了后最优树的训练和测试 NMSE。训练误差如图 4 所示。对于所有的算法,测试误差通常与训练误差相似。RDO + L S x L S ^{xLS}_{+LS} +LSxLS 表现最好,RDO{xLS} 次之。 Wine red 在测试期间,SGP + L S _{+ LS} +LS 优于 RDO + L S x L S ^{xLS}_{+LS} +LSxLS,表明后者略微过拟合。
7.2.2 Time taken by 100 generations.
图 5 显示了算法执行100代所需的时间。SGP 和 SGP + L S _{+ LS} +LS 所花费的时间与 RDO 的各种配置相差很大。对于有 308 个示例的 Yacht,RDO 比 SGP + L S _{+ LS} +LS 耗时约 20 倍;对于 Tower,有 4999 个例子,RDO 比 SGP + L S _{+ LS} +LS 长 100 倍左右。这一结果强烈地激发了在 SGP 和 RDO 配置之间进行基于时间的比较的必要性,以实现公平性。
他使用 LS 除了 RDO,或在库内搜索,平均而言,增加运行时间。但是,如果将这些运行时间与 SGP + L S _{+ LS} +LS 的运行时间相比较,两者相差不大。这是预期的,因为 +LS 和 xLS 不影响计算时限。RDO 和 RDO + L S _{+ LS} +LS 的变化幅度较大 (RDO的一些极端时间点被认为是异常值)。
7.2.3 Budget of 1000 seconds.
图 6 报告了每个数据集和算法的最佳训练适应度随时间的演化情况。从这些结果中可以得出的结论与基于世代限制的结论不同。对于 SGP 而言,使用 1000 秒的时间限制似乎比使用 100 代的时间限制更合适,因为在这种情况下,适应度更趋于平坦。
目前,RDO 的表现明显差于 SGP,RDO + L S _{+ LS} +LS 也差于 SGP + L S _{+ LS} +LS,后者的表现通常接近于 RDO{xLS}。而在基于时间的比较中 RDO 表现很差,但有趣的是,RDO{xLS} 和 RDO + L S x L S ^{xLS}_{+LS} +LSxLS 仍然表现很好。事实上,将 LS 包含在库搜索中使得变异变得如此有效,以至于即使库搜索本身变慢, fitter trees 也更早被发现。虽然 xLS 使变异得到改善也许并不奇怪,但看到这种改善的程度是有趣的。
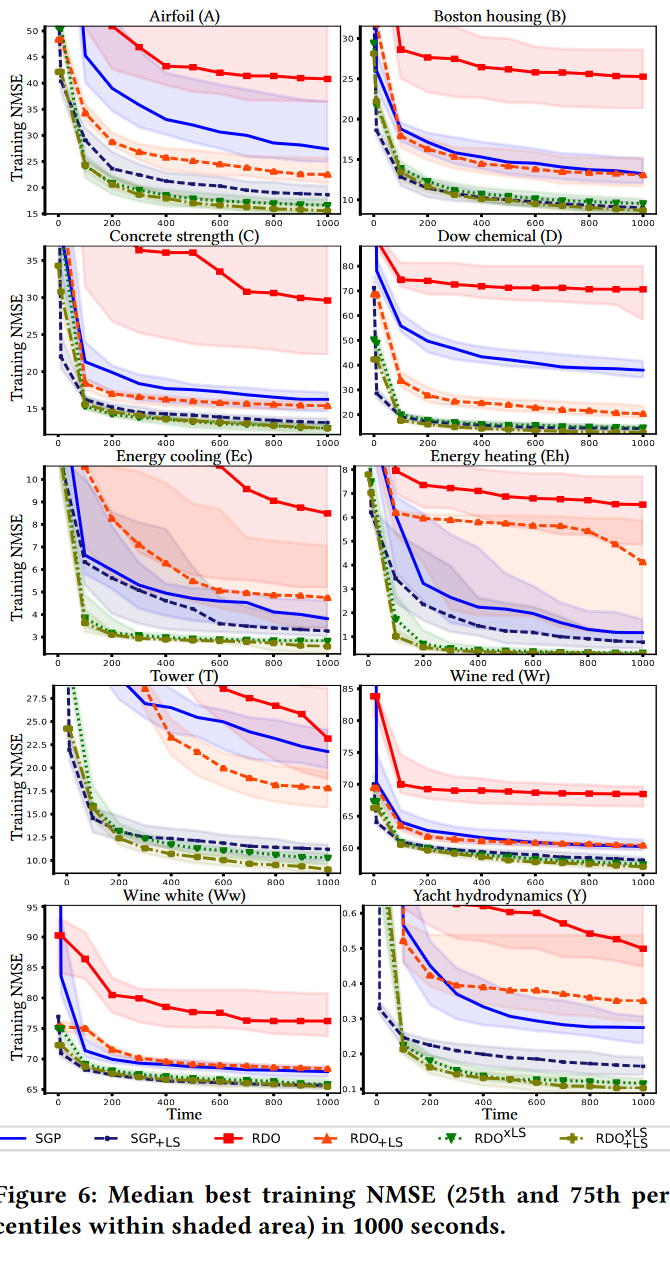
表 6 总结了 run 结束后最优树的训练和测试NMSE。统计显著性检验证实了图 6 训练适应度收敛图中已经看到的情况:RDO + L S x L S ^{xLS}_{+LS} +LSxLS 表现最好,其次是 RDO{xLS}。在误差大小方面,与 SGP 和 RDO w/o LS 相比,SGP + L S _{+LS} +LS 与 RDO{xLS} 和 RDO + L S x L S ^{xLS}_{+LS} +LSxLS (但往往显著恶化)较为接近。
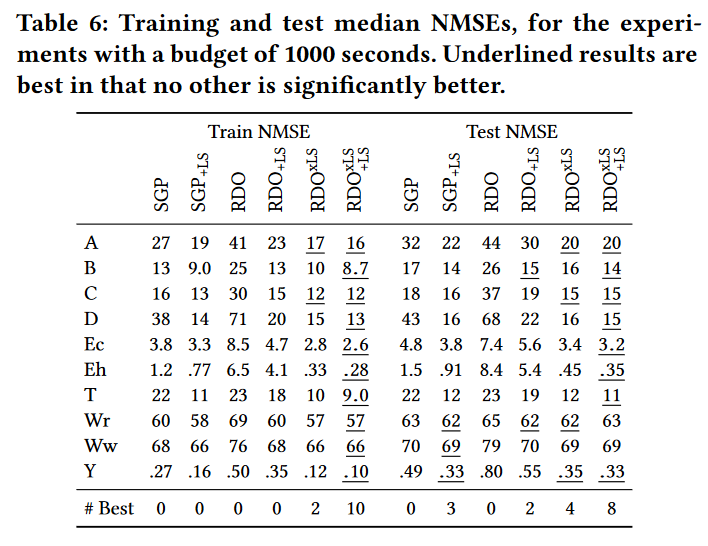
在泛化性方面,RDO + L S x L S ^{xLS}_{+LS} +LSxLS 仍然是可取的,因为它仅在 2个 数据集上显著差于另一个算法,幅度相对较小。SGP + L S _{+LS} +LS 在 10 个数据集中有 3 个数据集上取得了很好的泛化效果,说明在训练时间上表现较好的 RDO + L S x L S ^{xLS}_{+LS} +LSxLS 表现出了轻微的过拟合现象。
总而言之,我们的结果表明,在图书馆搜索过程中对树进行缩放对 RDO 来说是非常有价值的。此外,考虑反向传播时的 LS,即 RDO + L S x L S ^{xLS}_{+LS} +LSxLS,给出了进一步的边缘。
8 DISCUSSION
我们发现 RDO 和 SGP 在真实世界数据集上的比较强烈依赖于这种比较是如何被框定的。在典型的 100 代预算下,算法性能互补。相反,当比较以时间为框架时,RDO 比 SGP 表现更差。我们提出的在 RDO 机制中加入 LS 的方案,使得算法在发生额外计算的情况下仍然具有较高的效率,并且能够超越所有其他算法。
我们现在讨论本文的一些局限性。首先,我们对 GP 的参数进行了典型的设置。人们可能想知道我们的发现是否能推广到其他构型。种群规模也许是最有趣的考虑方面 [10],特别是在使用基于种群的库(由种群中所有具有唯一输出的子树组成)时。如果一个库足够大,即如果它有足够的代表性权力,采用 LS 可能会变得多余。然而,由于 LS 应用一个最优的线性变换,我们认为种群和库可能需要增长太大而无法实际可用来与 LS 竞争。至于其他参数,我们相信我们的结果的大小,以及在运行过程中发现的小方差,强烈表明在库搜索中使用 LS 将对许多其他参数设置仍然有益。
我们的方法的另一个限制,特别是在库搜索中使用 LS,是树大小的增长。任何时候从库中检索到一棵树,都会添加四个节点来合并 LS 的效果。较大的树评估(并且需要更多的内存来缓存中间输出)的速度较慢,也不太可能导致可解释的表达式。机器学习模型的可解释性可以作为实际应用的一个相关方面,例如在医疗 [16、23]中。通过在库搜索中加入 LS,我们确实发现了生长更大的树,在基于时间的比较中 RDO + L S x L S ^{xLS}_{+LS} +LSxLS 发现的最好的树比 SGP + L S _{+LS} +LS 发现的树平均大 1.1 倍。我们认为这种大小上的差异在很大程度上是不重要的。两种算法得到的树都很大,SGP + L S _{+LS} +LS 算法平均约 325 个节点,RDO + L S x L S ^{xLS}_{+LS} +LSxLS 算法平均约 360 个节点。从性能的角度来看,评估一个更大的树所花费的时间增量是有限的,但对于比我们所考虑的数据集大得多的数据集,可能会变得明显。在可解释性方面,算法提供的树等同于太大而不能产生可解释的表达式。
因此,未来的工作可以集中在减少树木的大小,例如,探索纳入膨胀控制方法[17],或者将对较小树木的偏好作为次要目标 [7]。然而,如果真正需要的是只有几十个节点的树,那么我们认为可能需要采取截然不同的GP方法,比如基于现代模型的 GP [ 23、24]。
另一个值得研究的方面是使用更高效的数据结构来实现库。在文献 [15] 中,k-d 树被使用 [2、9]。我们使用这种数据结构进行了实验,虽然对于很多实例的数据集,搜索 k-d 树可能并不快速 [9],但我们确实观察到了我们所考虑的数据集的加速。遗憾的是,LS 不能用于 k-d 树搜索。这是因为 k-d 树是利用树输出的固定分布来构建的,在搜索时可以切割探索分支。应用 LS 意味着动态地改变这样的分布。
我们采用 k-d 树结合只计算最优平移系数 a 的方法进行实验。这可以通过 (i)在构建 k-d 树之前减去每个库树的输出 o 的均值来实现;(ii) 在 k-d 树搜索之前减去期望输出 d 的均值;(iii) 在搜索返回的树上加上 a = d ˉ − o ˉ a = \bar{d} - \bar{o} a=dˉ−oˉ。实现了最优转换(见方程2)。然而,我们发现这比在传统的库搜索中使用 LS (其中也计算 b )效果差。为了找到一种能够使用 LS 或类似的强大方法的高效数据结构,以及研究代码并行化,可以允许使用基于 SB 的 GP 进行大规模符号回归。
9 CONCLUSION
我们介绍了线性缩放 (LS) 与语义反向传播 (SB) 的协同作用,以及在遗传编程 (GP) 中使用库搜索进行符号回归。我们在10个真实数据集上验证了所提出的适应性,并使用 generational 和 a time budget 比较了各种GP配置。我们发现在基于SB的GP中引入LS在两种情况下都会有更低的误差,并且优于使用传统的变异算子。最后,由于基于 SB 的GP的渐近时间界保持不变,我们的适应所产生的成本是有限的。这些时间上的变化与 fitness方面已经看到的变化有关 (例如,见图4中的 Energy 数据集)。
Reference
[1] Virgolin M, Alderliesten T, Bosman P A N. Linear scaling with and within semantic backpropagation-based genetic programming for symbolic regression[C]//Proceedings of the genetic and evolutionary computation conference. 2019: 1084-1092.
[2] Marcin Szubert, Anuradha Kodali, Sangram Ganguly, Kamalika Das, and Josh C Bongard. 2016. Semantic Forward Propagation for Symbolic Regression. In International Conference on Parallel Problem Solving from Nature. Springer, 364374.