文章目录
BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
标题

摘要

GPT考虑的是单向(用左边的上下文信息去预测未来),BERT同时使用了左侧和右侧的信息,它是双向的(Bidirectional)
ELMO用的是一个基于RNN的架构,BERT用的是transformer,所以ELMo在用到一些下游任务的时候需要对架构做一点点调整,但是BERT相对比较简单,和GPT一样只需要改最上层就可以了
导言
在语言模型中,预训练可以用来提升很多自然语言的任务
自然语言任务包括两类
句子层面的任务(sentence-level): 主要是用来建模句子之间的关系,比如说对句子的情绪识别或者两个句子之间的关系
词元层面的任务(token-level): 包括实体命名的识别(对每个词识别是不是实体命名,比如说人名、街道名),这些任务需要输出一些细腻度的词元层面上的输出
在使用预训练模型做特征表示的时候,一般有两类策略
- 一个策略是基于特征的,代表作是ELMo,对每一个下游的任务构造一个跟这个任务相关的神经网络,它使用的RNN的架构,然后将预训练好的这些表示(比如说词嵌入也好,别的东西也好)作为一个额外的特征和输入一起输入进模型中,希望这些特征已经有了比较好的表示,所以导致模型训练起来相对来说比较容易,这也是NLP中使用预训练模型最常用的做法(把学到的特征和输入一起放进去作为一个很好的特征表达)
- 另一个策略是基于微调的,这里举的是GPT的例子,就是把预训练好的模型放在下游任务的时候不需要改变太多,只需要改动一点就可以了。这个模型预训练好的参数会在下游的数据上再进行微调(所有的权重再根据新的数据集进行微调)
上述两个途径在预训练的时候都是使用一个相同的目标函数,都是使用一个单向的语言模型(给定一些词去预测下一个词是什么东西,说一句话然后预测这句话下面的词是什么东西,属于一个 预测模型,用来预测未来,所以是单向的)

结论

相关工作

在计算机视觉中这一块使用比较多:经常在ImageNet上训练好模型再去别的地方使用,但是在NLP这一块不是特别理想(可能一方面是因为这两个任务跟别的任务差别还是挺大的,另一方面可能是因为数据量还是远远不够的),BERT和他后面的一系列工作证明了在NLP上面使用没有标号的大量数据集训练成的模型效果比在有标号的相对来说小一点的数据集上训练的模型效果更好,同样的想法现在也在慢慢地被计算机视觉采用,就是说在大量的没有标号的图片上训练出的模型也可能比在ImageNet这个100万数据集上训练的模型可能效果更好!
BERT模型
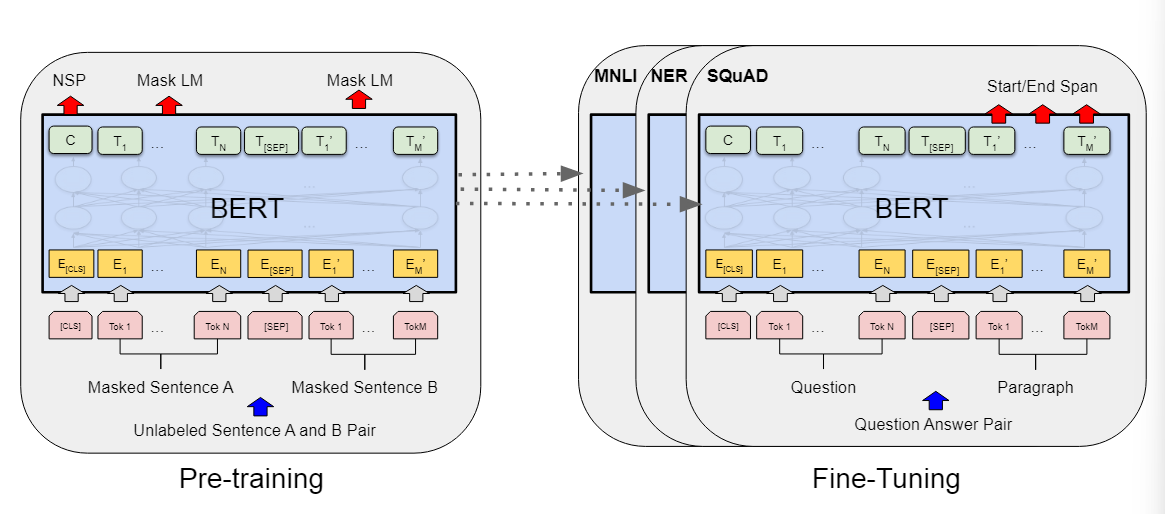
使用来自下游任务的标记数据对所有参数进行微调。每个下游任务都有单独的微调模型,即使它们是使用相同的预训练参数进行初始化的
BERT中有两个步骤:
- 预训练:在预训练中,模型在不同的预训练任务中使用未标记的数据进行训练。
- 微调:在微调的时候同样是用一个BERT模型,但是它的权重被初始化成在预训练中得到的权重,所有的权重在微调的时候都会参与训练,用的是有标号的数据
预训练的时候输入是一些没有标号的句子对
这里是在一个没有标号的数据上训练出一个BERT模型,把他的权重训练好,对下游的任务来说,对每个任务创建一个同样的BERT模型,但是它的权重的初始化值来自于前面预训练训练好的权重,对于每一个任务都会有自己的有标号的数据,然后对BERT继续进行训练,这样就得到了对于某一任务的BERT版本
模型架构

模型调了哪 3 个参数?
L: transform blocks的个数
H: hidden size 隐藏层大小
A: 自注意力机制 multi-head 中 head 头的个数
题外话:

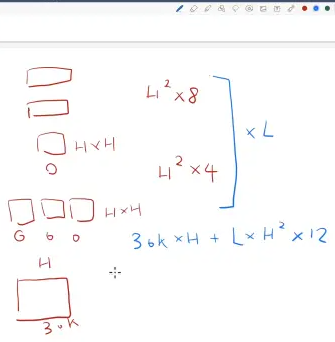
3个小方块分别是Q、K、V。
- 对于Q、K和V的投影矩阵:每个投影矩阵的维度为H*64(假设每个头的维度为64)。由于有A个头,所以总的参数数量为3(Q、K和V) * A * H * 64
- 自注意力的输出投影矩阵:这个矩阵的维度也是H*H。
参数数量 = 3 * A * H * 64 + H * H = 4 * H * H


举例说明:假设我们有一个包含单词"unhappiness"的文本。使用传统的分词方法,它将被切分为一个单词,即"unhappiness"。然而,如果我们采用WordPiece算法,它可能会将这个单词切分为"un"、"happiness"两个子词。这是因为"un"和"happiness"都是常见的部分,"un"通常表示否定,而"happiness"表示快乐。这种切分方法可以更好地捕捉文本的含义
对于每一个词元进入BERT的向量表示,它是这个词元本身的embedding加上它在哪一个句子的embedding再加上位置的embedding,如下图所示
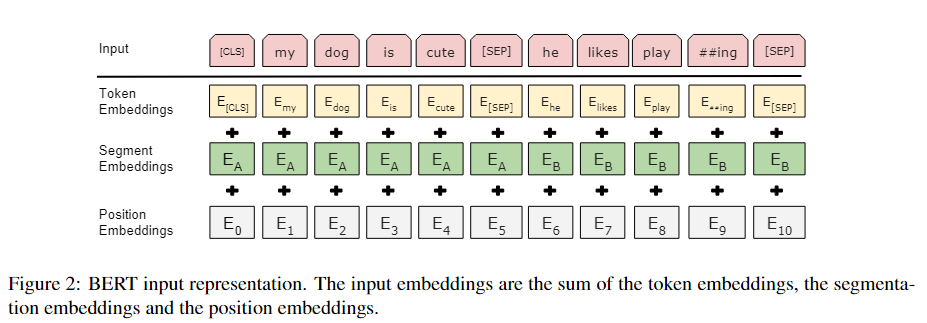
上图演示的是BERT的嵌入层的做法,即由一个词元的序列得到一个向量的序列,这个向量的序列会进入transformer块
上图中每一个方块是一个词元
- token embedding:这是一个正常的embedding层,对每一个词元输出它对应的向量
- segment embedding:表示是第一句话还是第二句话
- position embedding:输入的大小是这个序列的最大长度,它的输入就是每个词元这个序列中的位置信息(从零开始),由此得到对应的位置的向量
最终就是每个词元本身的嵌入加上在第几个句子的嵌入再加上在句子中间的位置嵌入
在transformer中,位置信息是手动构造出来的一个矩阵,但是在BERT中不管是属于哪个句子,还是具体的位置,它对应的向量表示都是通过学习得来的
预训练
Masked LM

Note that the purpose of the masking strategies is to reduce the mismatch between pre-training and fine-tuning, as the [MASK] symbol never appears during the fine-tuning stage.
请注意,掩蔽策略的目的是减少预训练和微调之间的不匹配,因为 [MASK] 符号在微调阶段永远不会出现。
掩蔽策略的主要目的是在预训练和微调之间创建一个更一致的训练信号,以提高模型的泛化性能。这是因为在预训练和微调之间存在一定的数据分布不匹配,如果不采取掩蔽策略,模型可能在微调阶段表现不佳,因为它在预训练阶段学到的知识无法直接转移到微调任务中。
Next Sentence Prediction (NSP)


用BERT做微调


