注意力机制的来龙去脉
在自学注意力机制,参考资料是 动手学深度学习V2-跟李沐学AI
注意力机制的现实背景
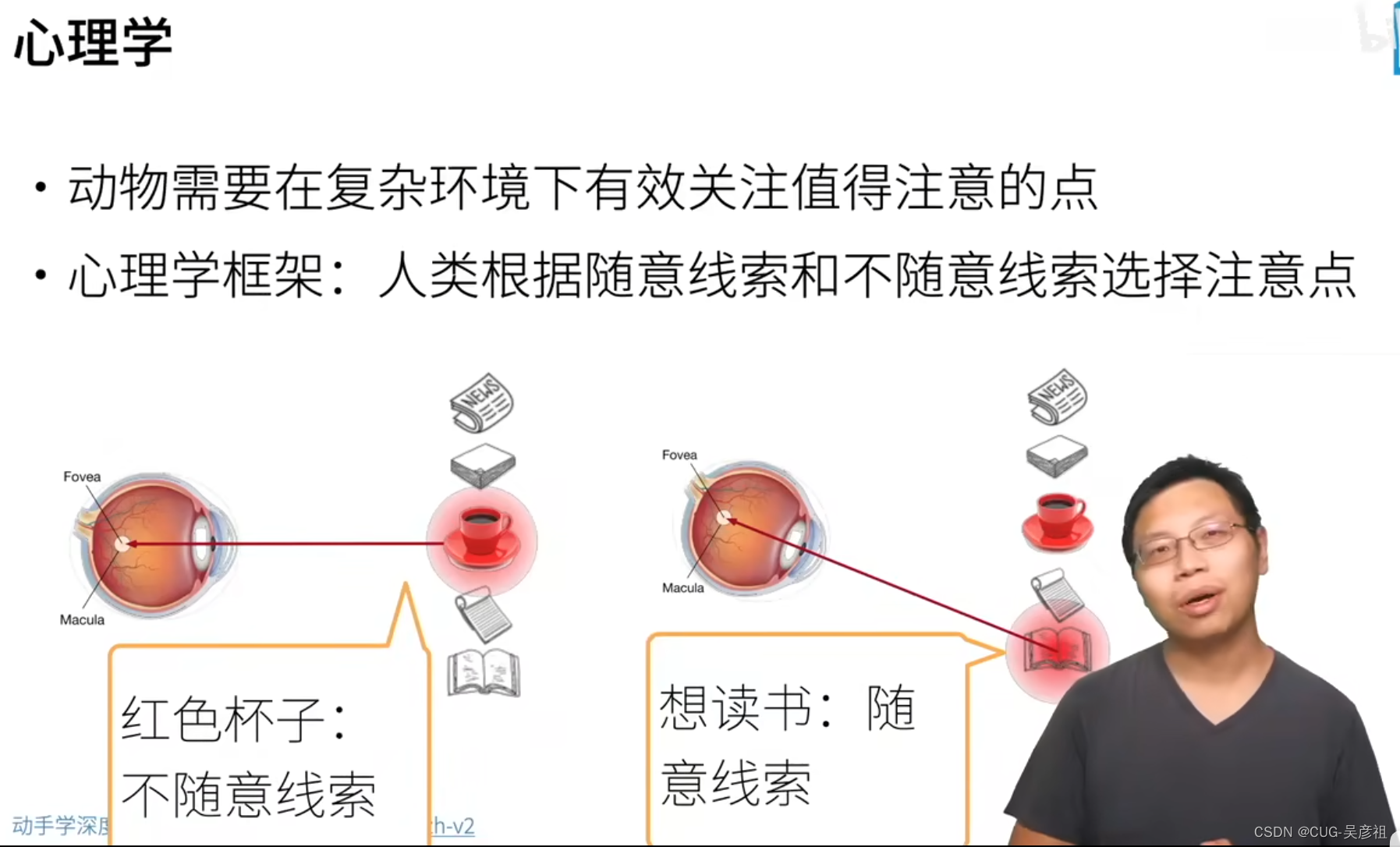
从心里学上讲,在充满各种信息的环境中,人类想要关注到自己想看的东西,就需要集中注意力去看对应的信息,比如桌子上有报纸、杯子、书本。人如果只想看到书本,那么眼睛就只盯着书本看,报纸和杯子就不用看了。
那么转换到深度学习中,想模仿人类的注意力的特点,在训练中希望在所有的样本(杯子、书本、报纸)中,既然我训练之前无法区分这些数据,那么我就希望,我最后输出的时候可以按照我的需求(例如,我要在这个环境中找到一个杯子),那么就需要设计注意力机制来在训练的时候,能够选取出和杯子高度相关的数据进行训练,最后就可以找到杯子作为输出。
注意力机制的本质
从设计上来说,注意力机制的本质就是设置N对键值对(Key-value),随后输入和key类似的query,计算query和那个key长得最像(余弦相似度),则在对应的pooling(聚集或池化层)去找到对应的key,然后找到value值输出。
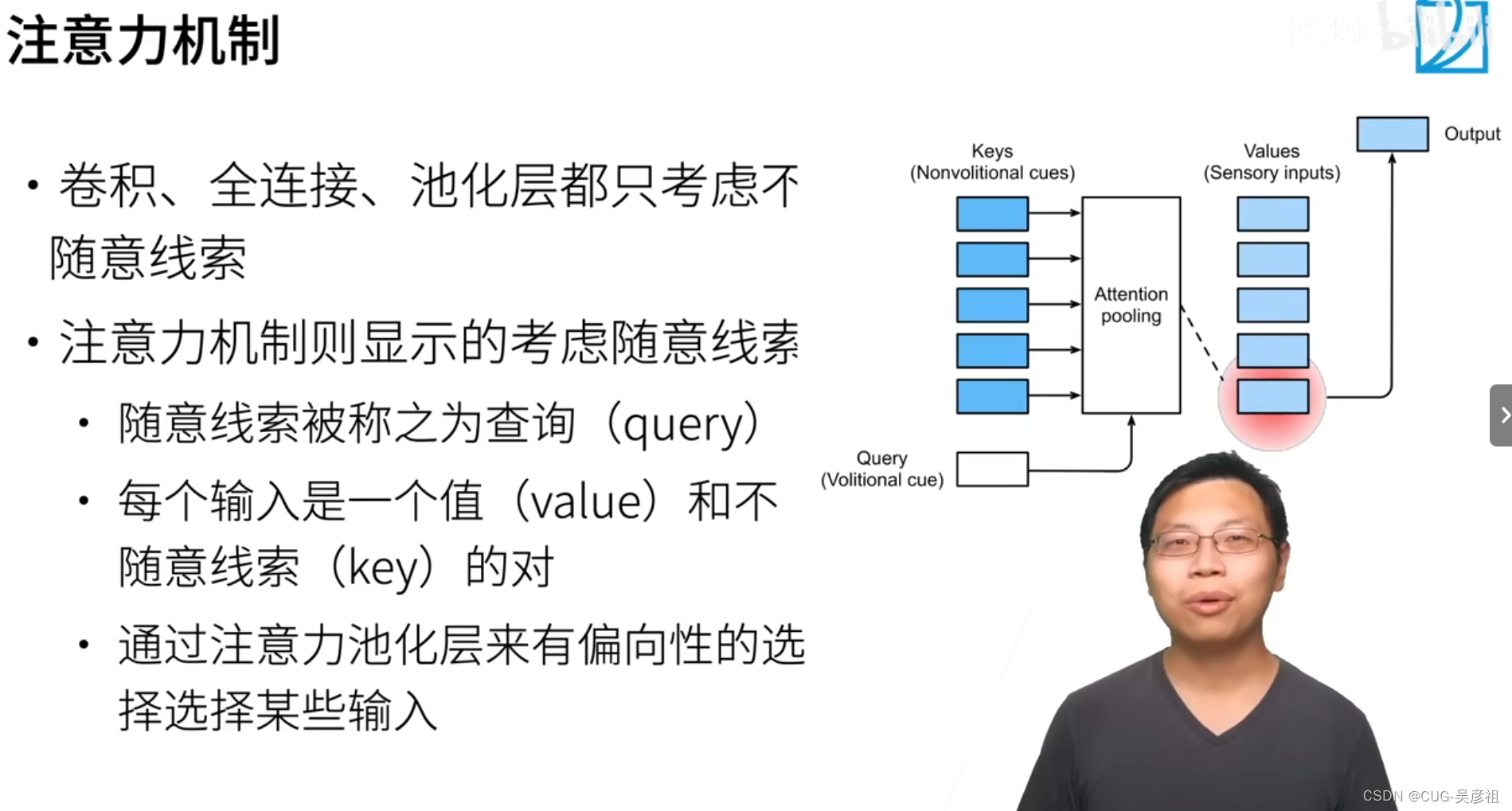
非参数的注意力池化层
在60年达算力有限时,统计学家们在设计,查询时,衡量效果的目标函数时,使用的是没用参数的加权平均和形式。x是query,xi表示key,yi表示value,则计算该query和每个key的差距,并将差距来做权重衡量该value占的比例。最后返回的时该query和那个value对应。K表示核函数。例如高斯核函数。

假设说使用高斯核函数,即为正态分布,将残差限定在[0-1]之间,那么就可以使得函数更加平滑。最后exp就可以转换成现如今注意力机制中使用的softmax函数。
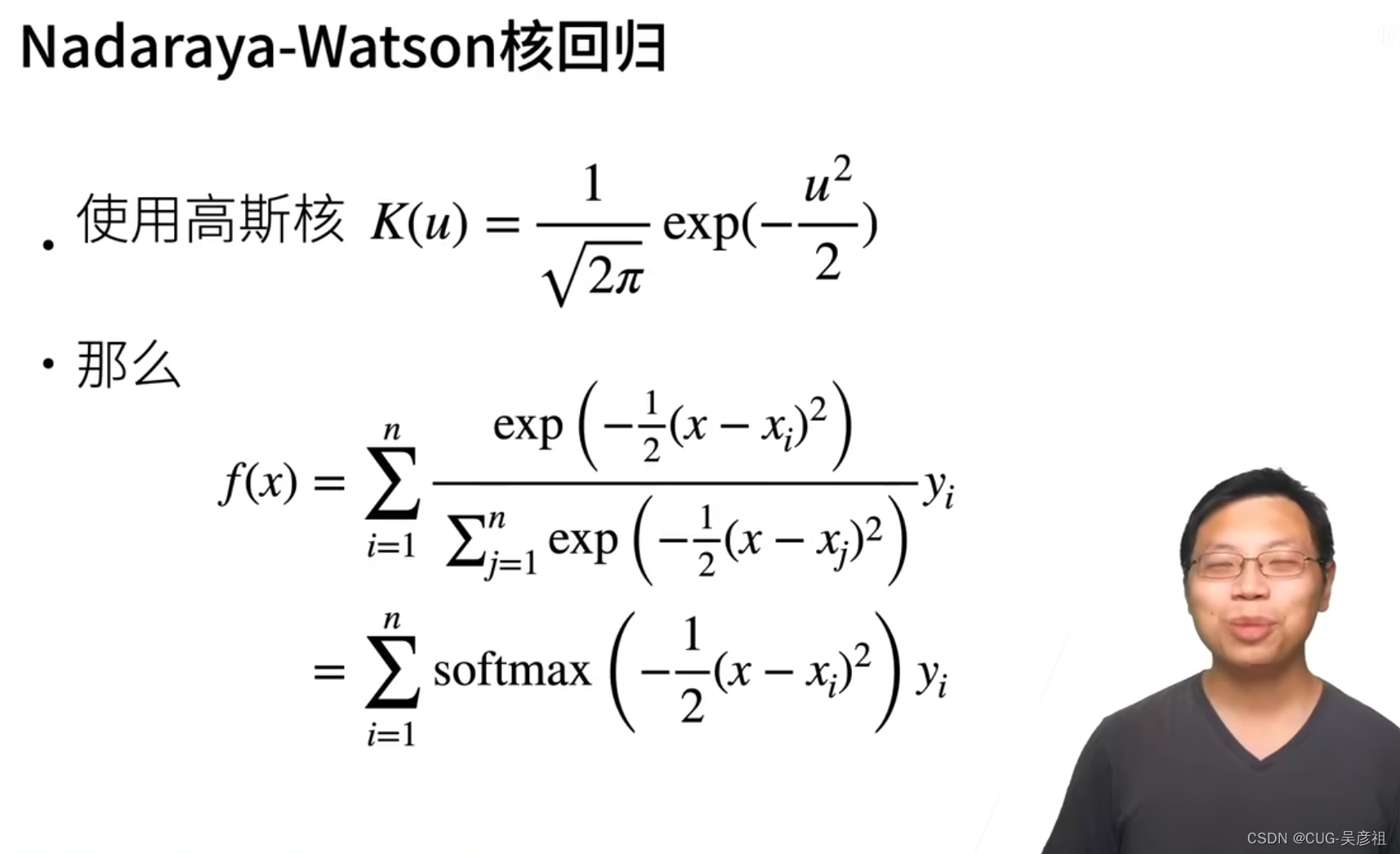
参数化的注意力机制
那么为了缩小注意力机制中,搜寻同类的返回,使得训练时更加的专注到周围的高度相关个体,给每个残差加入了参数w,那么这个参数w是可以通过学习来训练的。使得最后函数拟合的效果是最好的。查询效果最准。这就是现代Transformer的基础。如何设计权重w使得训练效果更好。这是需要改进的地方。

注意力分数设计-attention score function
回顾注意力机制中,query查询和key的差距并经过softmax将得分归一化,再乘对应的权重且乘上value最后,加权求和得到输出。
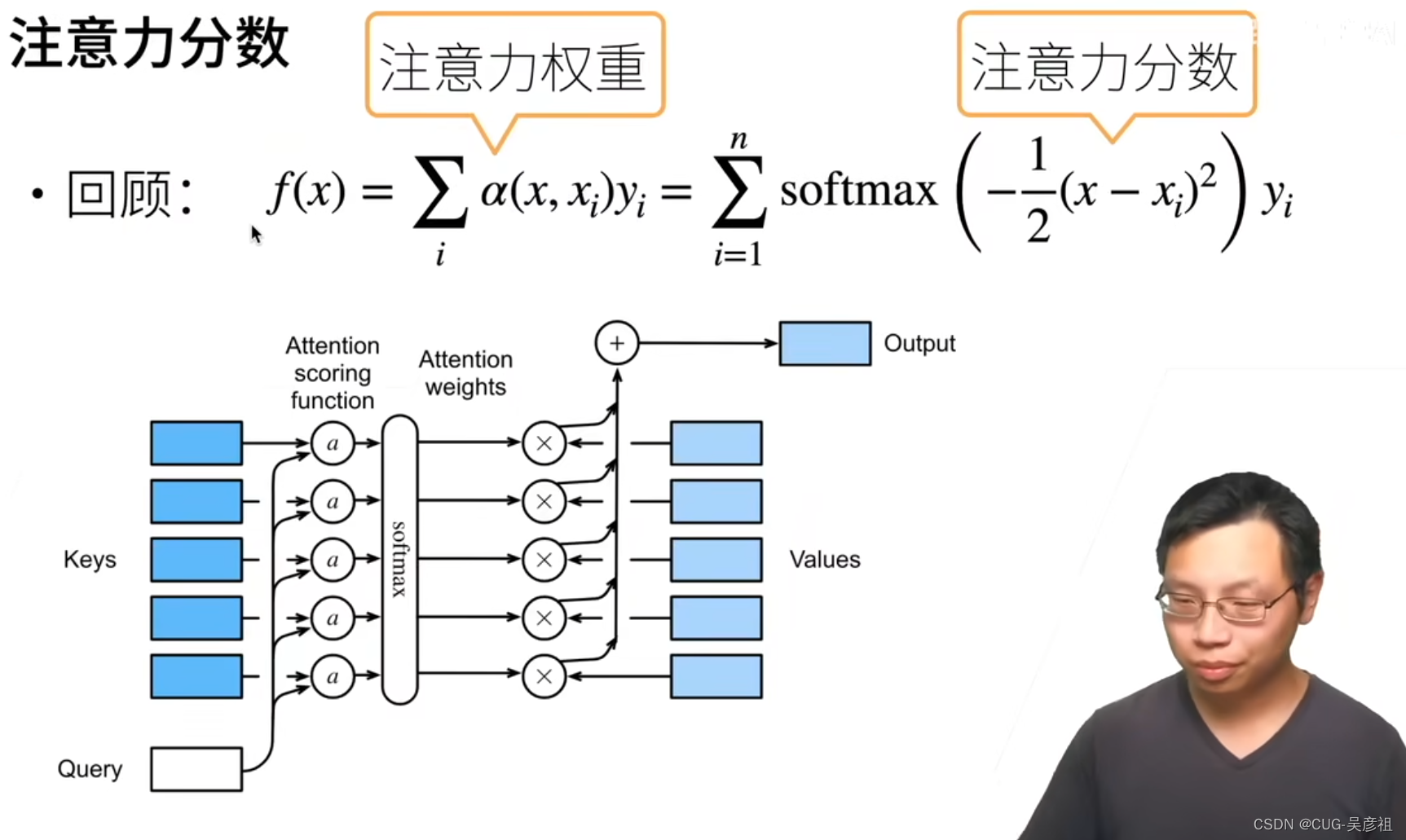
将q,k,v从一个标量一个值,拓展为一个向量之后,这里的q,k,v可以是都长得不一样。那么注意力分数或者说注意力得分函数,则为 a ( q , k i ) a(q,k_i) a(q,ki)。注意力池化层就是把M个键值对聚合起来的函数,可以是加权求和。

设计1:query和key加权-加权注意力
有三个参数需要学习分别是key权重矩阵Wk,query权重矩阵Wq,隐含层输出维度h。query长度为q,key长度为k,需要统一为h长度,则设定两个矩阵Wk为h行k列,Wq为h行q列,则key左乘Wk会变成长为h的向量,同理query也会变成长为h的向量,那么加起来再求tanh限定值在0-1之间,再乘value的转置,则得到维度为1*1的最后的分数。相当于把key和query输入到一个隐含层中输入为q+k输出为1。隐含层的参数为Wk和Wq。

设计2:点乘注意力
如果query和key一样长的话,那么可以用点乘也就是,内积的方式转换为注意力分数。

总结
注意力分数是query和key的相似度,注意力权重是分数的softmax结果。·两种常见的分数计算:·
1.将query和key合并起来进入一个单输出单隐藏层的MLP·
2.直接将query和key做内积
seq2seq中加入Attention Mechanism
动机
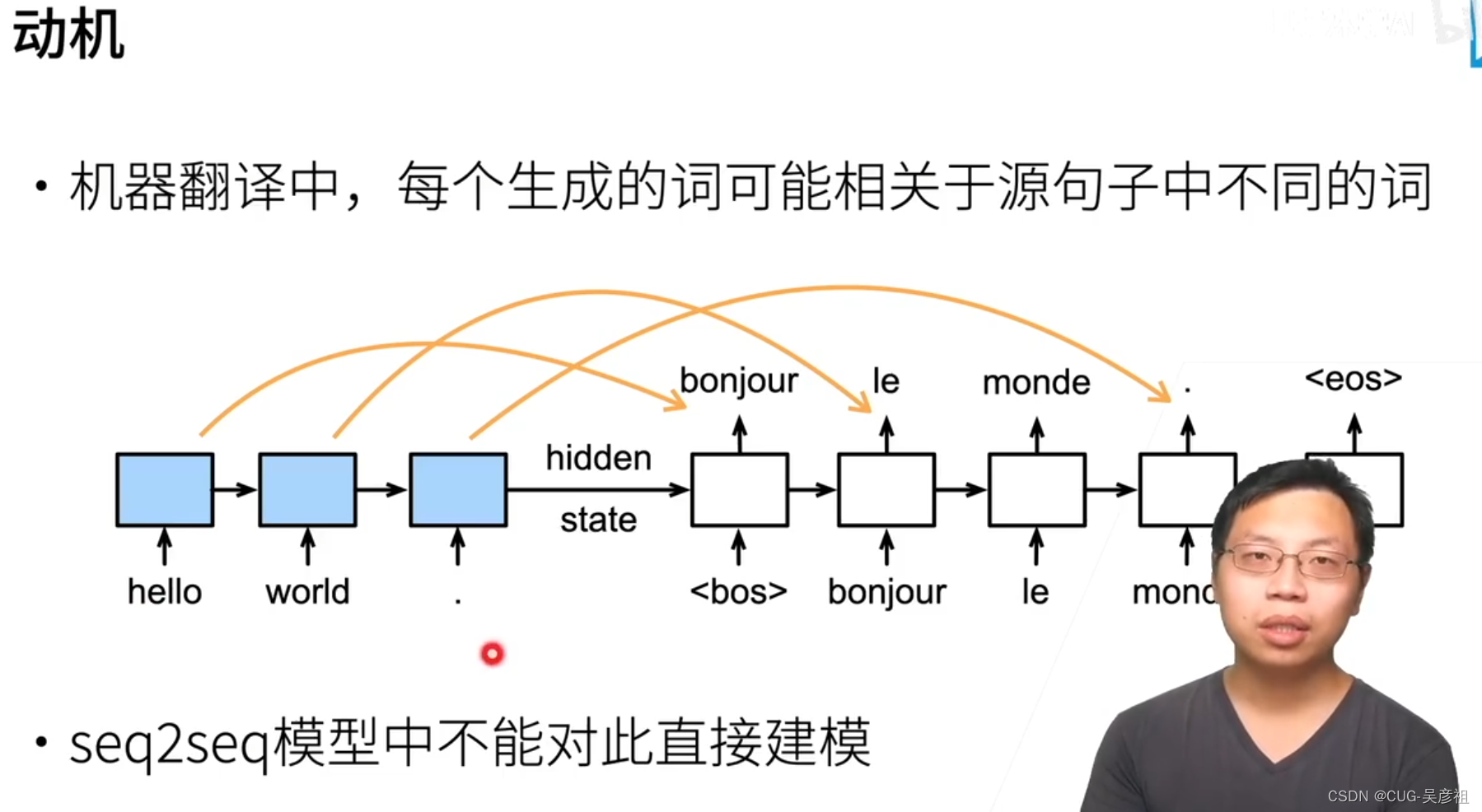
在自然语言处理的机器翻译中,例如英文翻译法文,每个词对应的单词可能不同。但是在seq2seq这个网络模型中,解码器的输入是编码器最后一个MLP隐含层的输出。这样的话,会使得需要寻找对应单词的信息杂糅在全部信息中。造成翻译效率的降低。因此无法直接采用seq2seq这个网络模型来进行机器翻译。
解决方法
解决方法是在两个RNN之间加入Attention pooling 辅助解码。编码器中,RNN的每个MLP都有一个隐含层输出。将这个输出作为一对(key,value)两个是一样的。随后将解码层的每个当前翻译单词的,前一个RNN的输出的作为一个query去查询。因为认为编码器和解码器的隐含层输出在一个语义空间内,所以都要用隐含层输出作为key value query。
举例来说,world在被翻译成le时,这个时候还猜不出world翻译成什么单词,那么需要用attention用解码器中上一个已经被翻译出来的bonjour的隐含层输出作为query 去attention pooling中查询编码器 中上一个已经被翻译出来的hello的RNN的隐含层输出,找到hello后把它附件的词的相似度收集起来,作为一个分数(不同单词的权重和),将该分数作为attention的输出和下一个单词的嵌入合并输入到下一个RNN中。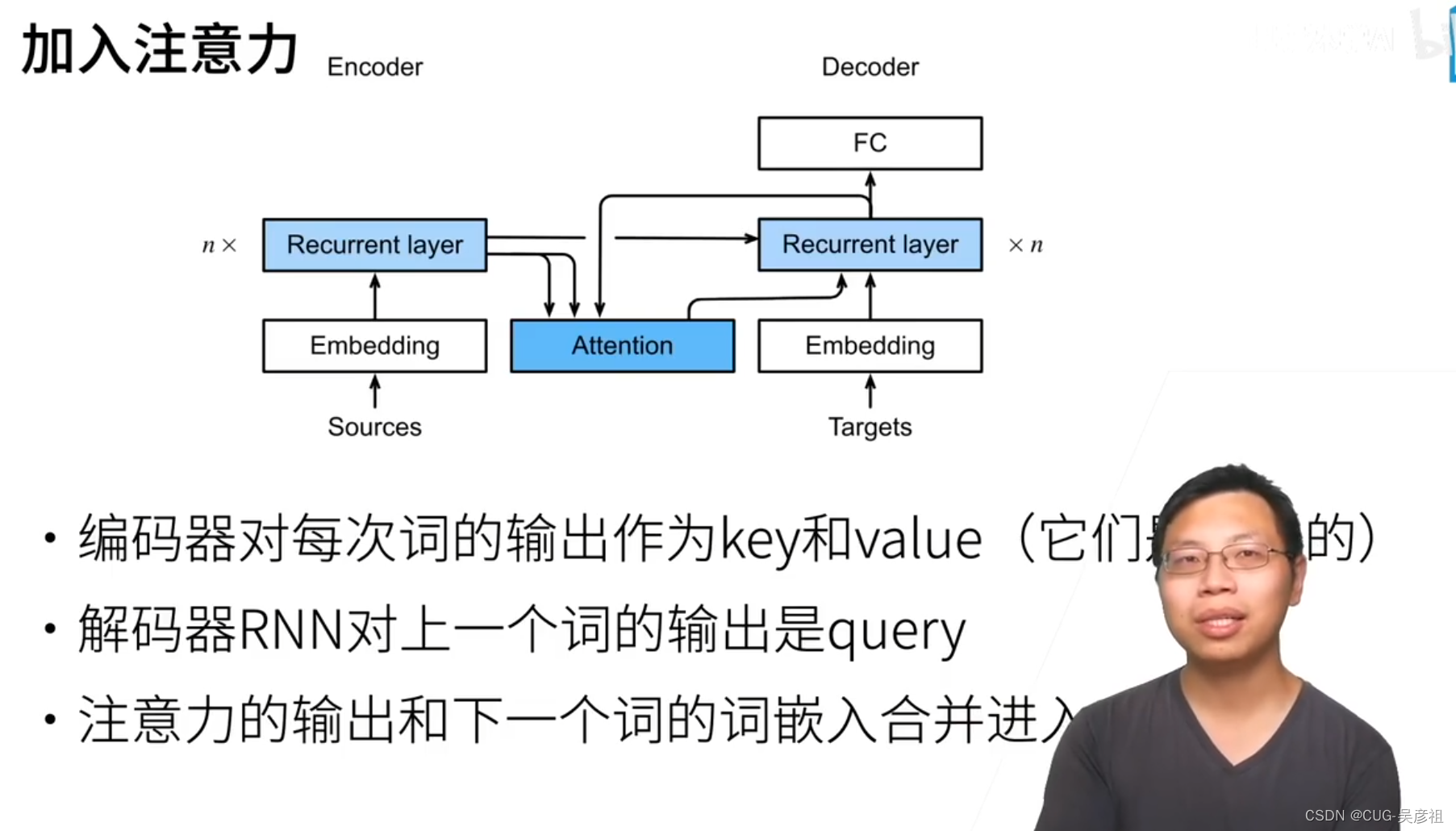
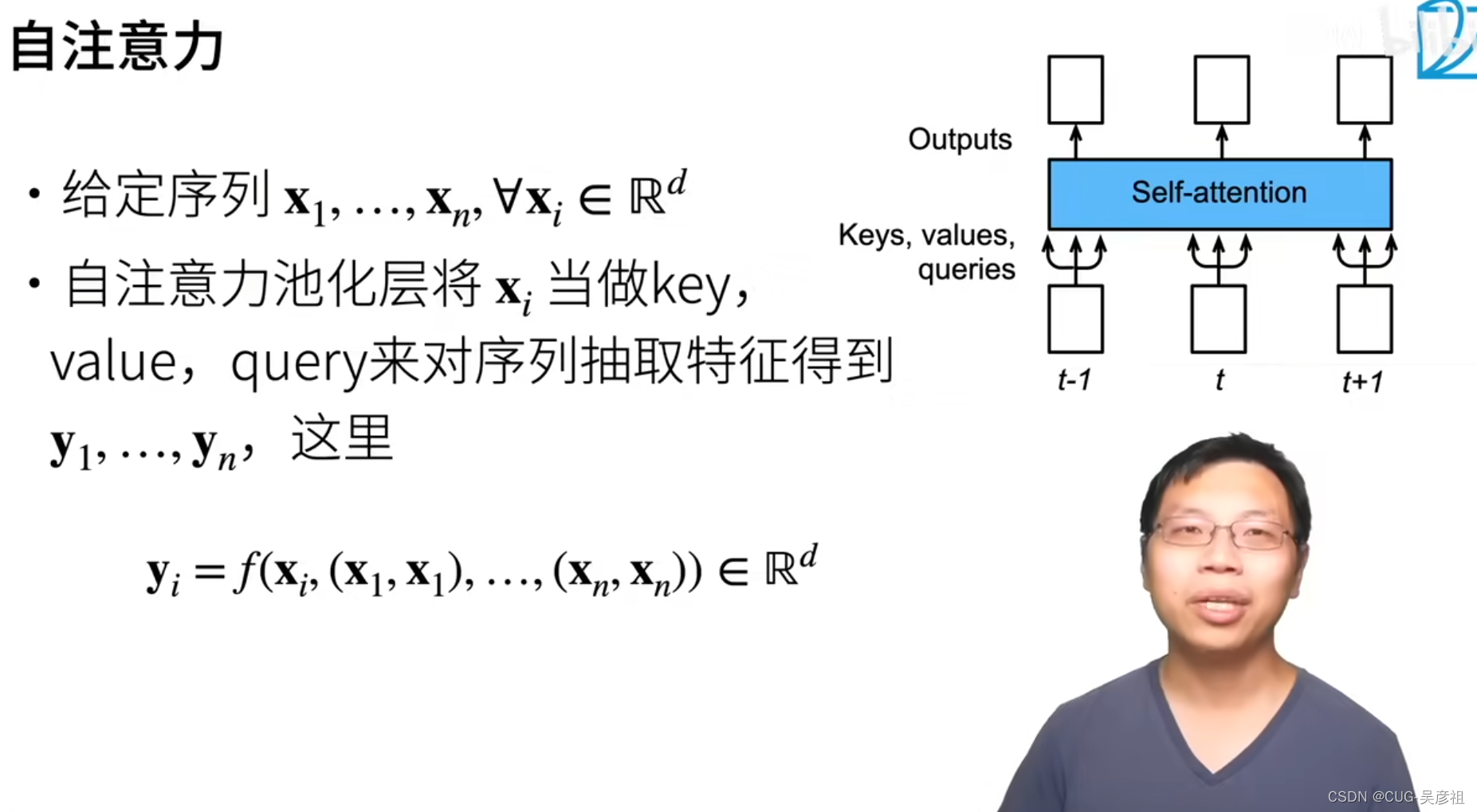
自注意力机制-self attention
假设有个序列 x 1 , . . . , x n x_1,...,x_n x1,...,xn每个 x i x_i xi是长为d的向量。自注意力机制就是将每个 x i x_i xi同时作为key,value,query抽取特征输入池化层中。那么每个x都可以查询到和自身相关的其他元素并赋予权重输出。和RNN中每个节点都有输出类似。
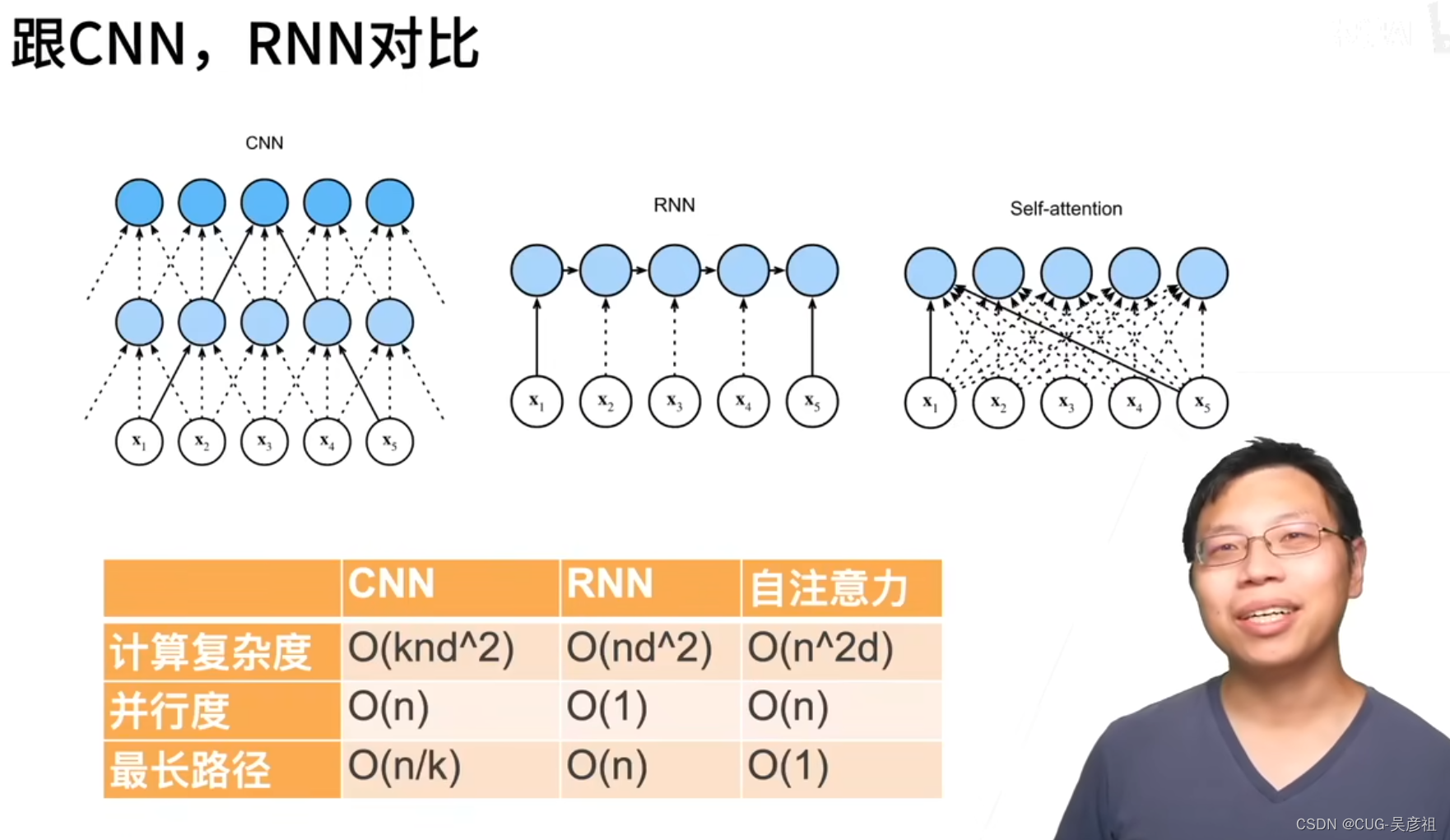
自注意力机制和CNN,RNN对比
如果模型对于 序列前后的依赖性很强的话RNN可以有很好的效果。但是当序列很长时候RNN的复杂度就很高。当句子很长的时候,自注意力机制也会有很大的计算量。自注意力机制当序列很长时可以很快的抓取到很远的信息,而RNN必须要将整个序列走完。而现如今Transformer和BERT这些模型应用了注意力机制,可以处理很长的序列,但是计算量平方级别增长,通常需要几百个GPU。
位置编码
自注意力机制没有位置信息,但CNN和RNN可以很快定位到不同输出的位置。所以由于自注意力机制没有位置信息,就将位置信息作为输入和序列相加合并起来输入进行训练。每个位置信息之间略有不同,区别的公式是如下两种。

相对位置信息编码
第i+a处的位置信息可以被i处的信息来线性表示。表达式如下:因为三角函数关系。

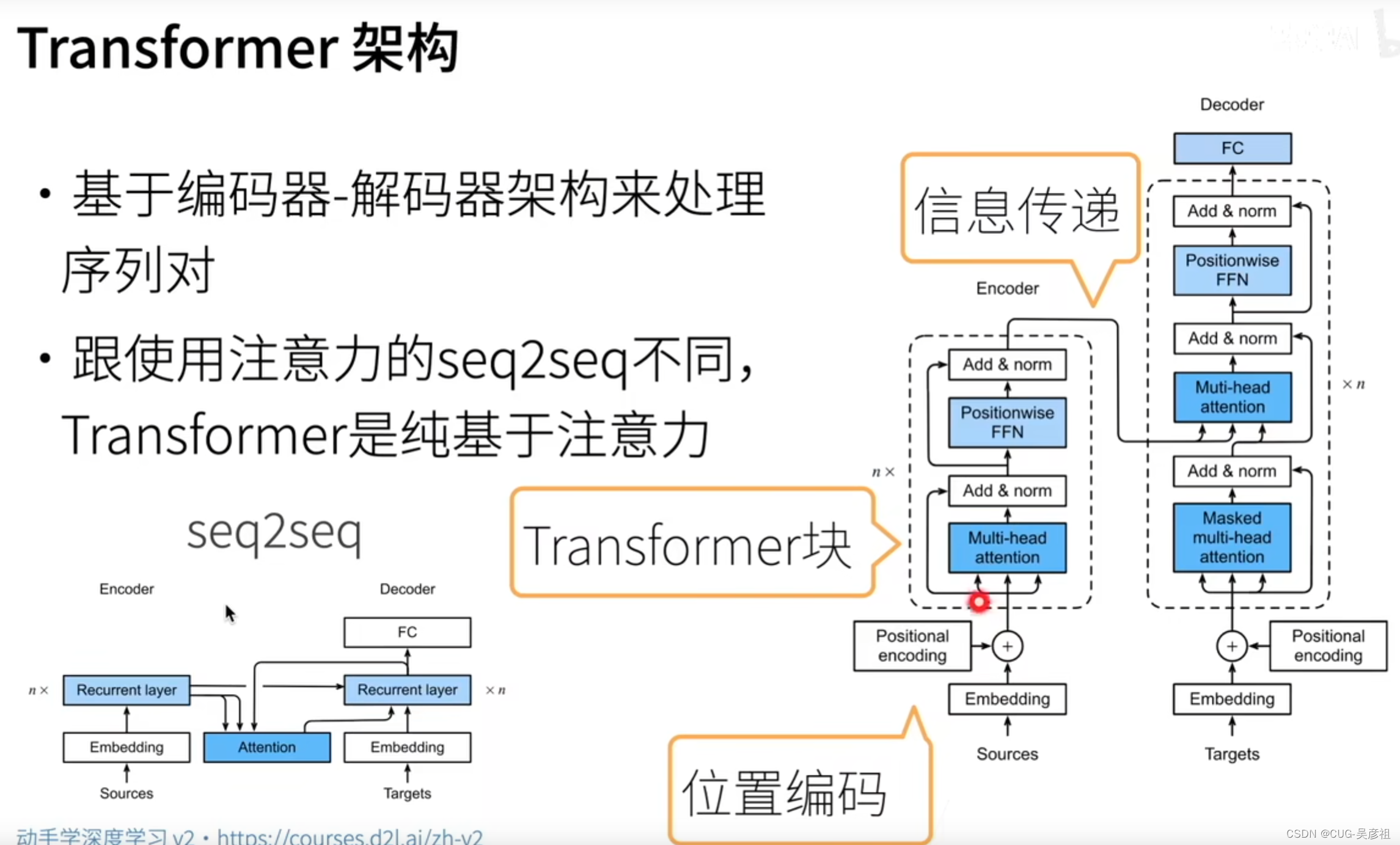
变形金刚 Transformer
相较于seq2seq, transformer使用纯注意力机制来处理序列问题,而非采用循环神经网络。transformer由一个编码器和一个解码器组成。
编码器:信息嵌入后加上位置编码一同输入到attention pooling中,自身的向量是Q,K,V,也就是自注意力机制。前面讲过自注意力机制可以无视距离快速阅读上下文。attention score从多头注意力出来之后,会加上前面的input并且归一化。随后输入全连接层,然后提取特征后再加上和归一化。重复进行N次最后将信息输出到解码器的attention pooling中当做key value。
解码器:同样的方式,解码器需要对应被翻译的词进行层层解码,mask 多头是为了不看padding部分,减少计算量。最后将得到的attention score拿到attention pooling中去查询和那个最像,将分数和输入加且归一化。再经过全连接层解码,反复N次之后最后用全连接层输出。
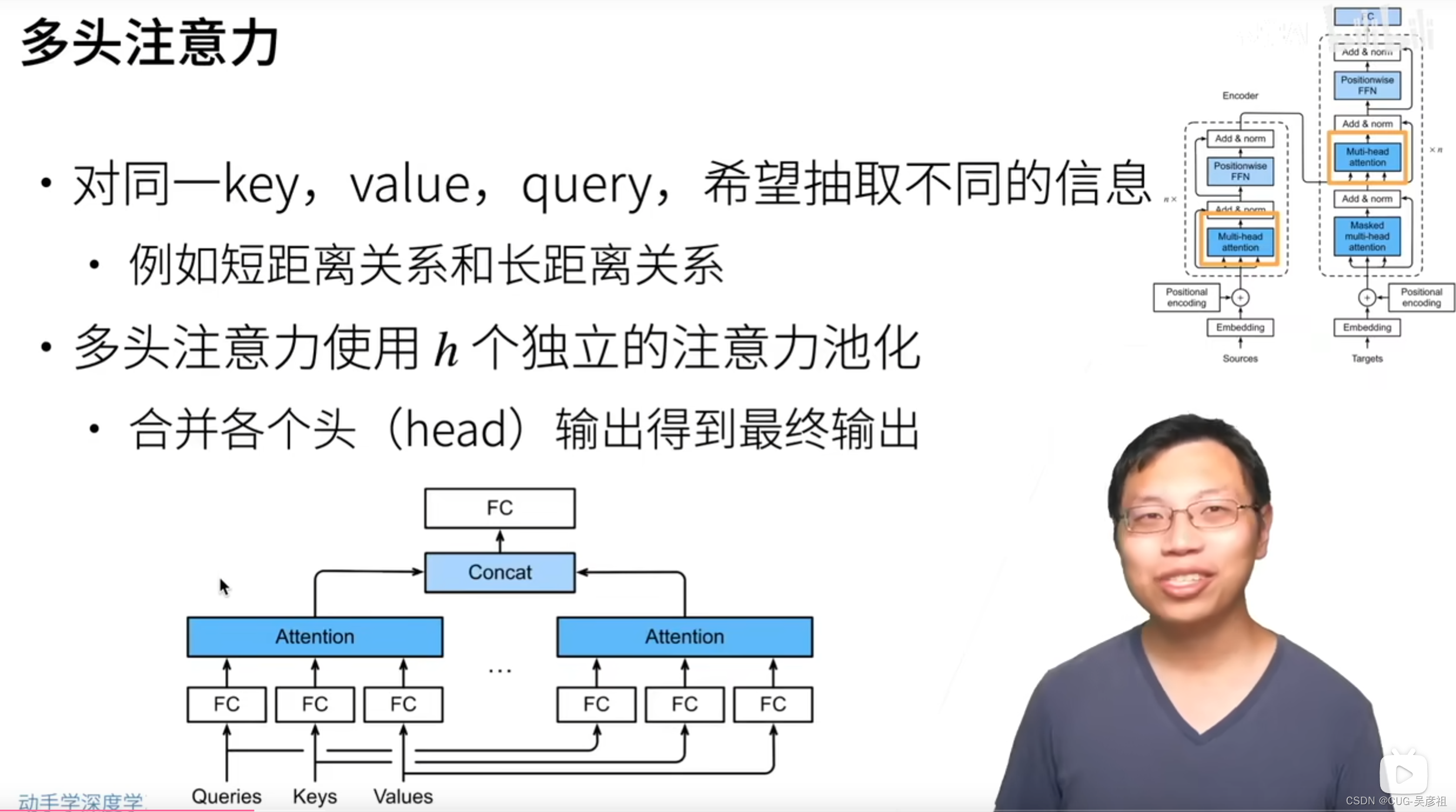
多头注意力机制-multi-head attention
每一个Q,K,V,我希望它在不同的时候表现出不同的性能,有时候可以记住长的句子,有时候可以记住短的句子,那么我就设置多个attention pooling来存储不同的能力或注意力。一对Q,K,V,我需要训练H个池化层。最后将H个attention score链接起来再用全连接层输出。在多头注意力的结构中,一个池化层就是一个头。将Q,K,V输入三个全连接层,映射到统一的d维度,最后每个头做一个自注意力机制。
Masked multi-head attention 带有掩码的多头注意力

基于位置的前馈网络FFN
其实就是个全连接层,原因是在attention pooling 的输出是三维,batchsize,序列长度,维度。由于序列长度可变,那么就不能将序列长度和维度组合。那么就将序列中的每个xi当做样本,通过全连接层映射为bn,d维度。

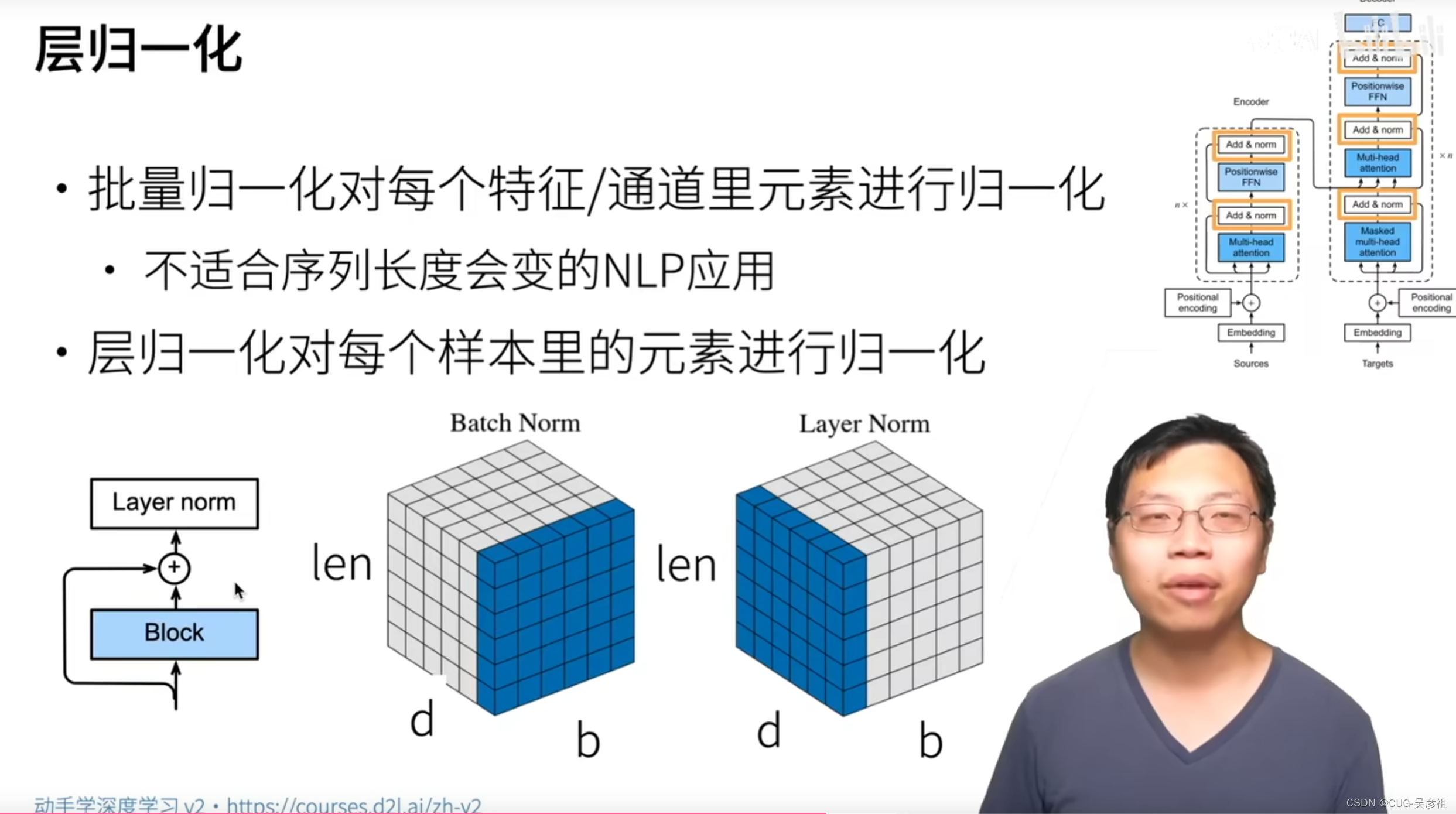
层归一化
由于要增加网络深度,增加网络的处理序列的能力,所以Add就是残差连接以保留之前的信息。第二就是需要归一化来方便加深网络的深度,但是传统的batch normal,是将序列中每个词的每一维的特征进行归一化,由于序列是可变的那么,会导致在归一化的时候,输入输出不稳定。所以就改成在每一个batch里做归一化。在单样本里做归一化。不会有不稳定的现象(不会有padding 0).
信息传递
把每一次的输出都存下来,作为解码时候attention pooling的key value的输入。

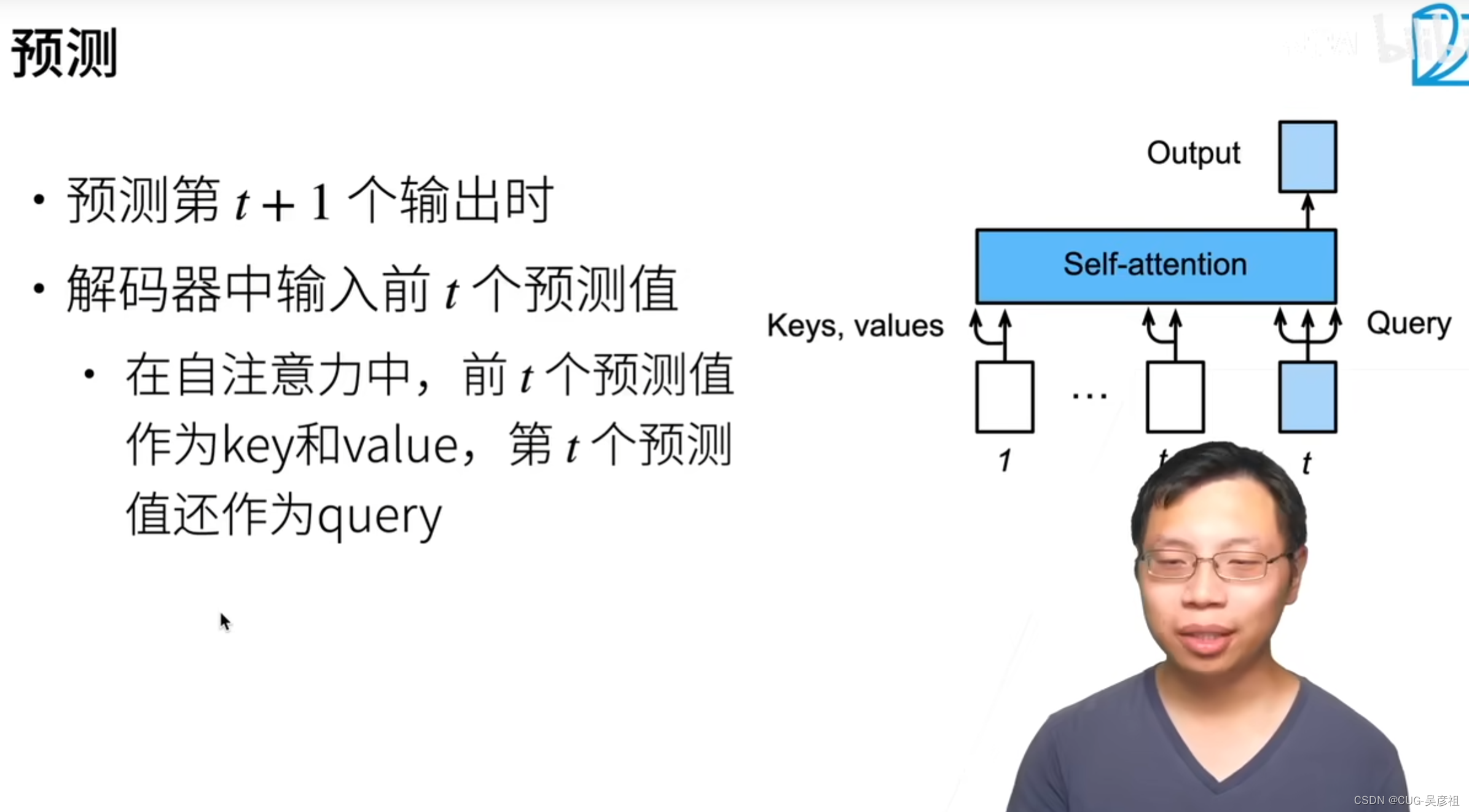
预测
当知道了前T个时刻的输出后,需要预测T+1时刻的输出,就需要前T时刻的输出当 key value,然后T时刻的输出当Q,K,V得到T+1时刻的单词被翻译的预测。
使用注意力机制做选择
注意力机制很好的就是,我结合不同的参数训练一堆东西,然后我输入那个参数就可以把训练的这部分模型提取出来使用。
例如:有N个不同的流水车间调度数据集,我建立RNN来对序列进行训练,记住每个测试集的特征,然后用强化学习来调整RNN的参数来使得其向最优解的方向靠近。然后我有N个测试集,我把这个N个测试集都训练在了一起,成为这N个测试集统一的优化器。那我我要使用这个优化器来进行解码的时候,我之间输入问题的规模,那么就可以通过Attention来找到优化器中那一部分被训练的模型,提出来用于求解该问题解。这样我相当于训练的一个模型就能求解N个测试集。相当于把N个定制化网络集成到了一起。缺点就是训练时间翻N倍。
例2:我在多目标组合优化中,我需要使得分布性非常好,在各个参考性附件都有点。那么传统方法是我设置N个参考线,我就要建立N个网络在该方向来用强化学习优化。如果用Attention,我就可以把这N个网络集成到一起。我训练完后,我需要得到那个参考线附近的解,我就输入参考线的名字,然后提取出那个模型,得到它优化的最终解。Attention就相当于一个集成和定制化的过程