MULTI-MODAL/MULTI-SCALE CONVOLUTIONAL NEURAL NETWORK BASED IN-LOOP FILTER DESIGN FOR NEXT GENERATION VIDEO CODEC
Jihong Kang, Sungjei Kim, Kyoung Mu Lee
Department of ECE, ASRI, Seoul National University, Seoul, Korea
Korea Electronics Technology Institute, Seongnam-si, Korea
摘要
本文提出了一种新颖的视频压缩环路滤波器设计方法。我们的方法的目的是用多模式/多尺度卷积神经网络(MMS-net)替换现有的解块滤波器和HEVC标准的SAO(样本自适应偏移)。提出的CNN结构由两个不同规模的子网组成。首先对输入图像进行下采样并通过低尺度网络恢复,然后将其输出图像馈入与原始输入图像相连的高尺度网络。此外,为了提高恢复性能,提出的架构利用了编码序列中的信息。具体地说,利用编码树单元(CTU)的压缩参数作为CNN的输入,有助于减少重建图像的阻塞伪影。在实验中,与传统的基于神经网络的方法[1]和HEVC参考软件HM16.7[2]相比,我们的方法在“All Intra-Main”配置下,BD-rate分别降低了4.55%和8.5%。
索引项—环路滤波器,HEVC,CNN,视频压缩,图像恢复
1. 介绍
视频和图像的压缩过程固有地导致帧内容的失真。压缩技术已在保持内容质量的同时,减少了用于存储压缩数据的比特数方面取得了进步。在这些技术中,HEVC标准[5]中的去块滤波器[3]和样本自适应偏移(SAO)[4]发挥了重要作用。 用于去除视觉伪影,例如阻塞伪影,振铃伪影,模糊伪影等。顾名思义,去块滤波器主要负责去除由基于块的量化处理引起的块伪影。HEVC标准中新引入的SAO使用附加的偏移值补偿其他工件。这两个滤波器既恢复了重建图像的主观质量,又恢复了重建图像的客观质量,而且由于重建图像被引用到序列中其他帧的预测中,因此也有助于提高压缩率。
近年来,卷积神经网络(CNN)在图像分类中的成功应用已经扩展到许多其他的研究领域。在图像恢复中,如超分辨率[6,7,8]、去模糊[9,10]和去噪[11],CNN已经优于传统的非学习方法。从机器学习的角度,我们可以认为CNN是通过使用大量的训练数据来学习从失真图像到未失真图像的非线性映射函数来完成图像恢复任务的。尽管输入图像的失真特性不同,但CNN在不同的图像恢复任务中的学习过程是非常相似的。通常,将失真和未失真的图像对作为输入和目标馈入CNN,并且CNN学习如何通过消除输入图像的失真来恢复目标图像。同样,相同的过程可以应用于学习视频编码中环路滤波器的操作。
一些研究已经开始应用CNNs来代替环路中的滤波器。Park and Kim[12]提议由IFCNN取代SAO。IFCNN有3个卷积层,输入和输出之间有跳跃连接[7]。 他们展示了通过用CNN替换现有环路滤波器来降低1.6-2.8%BD-rate的可能性。Dai等人。[1] 提出了VRCNN作为去块滤波器和SAO的替代。VRCNN共有4层卷积层,每层有2个不同大小的核。VRCNN报告了令人鼓舞的平均4.6%的比特率降低的结果。然而[1,12]的CNN体系结构过于肤浅,没有反映出最近CNN的改进,如批处理规范化[13]和剩余网络[14,15],而且这些工作仅仅是单纯地将CNN应用于这个问题,而没有考虑压缩视频中的丰富信息。
编码视频中含有大量直接或间接影响帧失真的信息,如编码参数(CPs),因此我们可以利用这些信息进行恢复。例如,分层编码树单元(CTU)信息可以准确地定位可能的块状伪像的边界。利用这些信息作为CNN的输入可以帮助网络精确地检测和恢复伪影。
本文提出了一种基于多模态/多尺度CNN(MMS-net)结构的HEVC环路滤波器设计方法。我们的模型具有完全卷积的神经网络结构,并且以端到端的方式工作。多尺度CNN的结构通过粗到细的恢复过程有效地提高了恢复性能。此外,编码视频中的CTU信息指导网络正确检测和移除阻塞伪影。为了更好地处理CTU信息,我们提出了一种将CTU转换为矩阵形式的方法和一种匹配不同模态特征的预处理网络。
2. 多模态/多尺度卷积神经网络
2.1. 格式化编码参数
块效应主要由基于块的压缩机制引起。因此,给定块划分信息,网络可以很容易地定位和消除块伪影。在HEVC标准中,CTU是压缩的基本处理单元。CTU递归地划分为编码单元四叉树(CU),每个CU由预测单元(PUs)和转换单元(TUs)组成。为了简单起见,我们只使用每个帧的CU和TU信息作为CNN的输入。
为了向CNN提供CU和TU信息,需要将这些信息转换成合适的形式。CU和TU信息应能提供输入图像中每个单元的位置和大小。在我们的实现中,我们创建一个输入图像大小的矩阵。然后,我们为每个CU和TU的最外层像素对应的位置分配值“2”,并为每个矩阵中的非边界区域设置值“1”。因此,为每个帧生成两个矩阵。CU编码的一个例子如图2所示。

2.2. 多模态自适应网络
将编码的CPs馈入网络的最简单的方法是沿着输入图像的通道轴连接CP矩阵。然而,以这种方式向网络提供CP信息可能会妨碍网络的恢复过程,而不是由于方式不同而改善结果。为了有效地处理单一网络中的多模态信息,我们添加了一个简单的预处理网络(称为自适应网络),将CP信息空间转换为图像特征空间。卷积层和ReLU层的组合将CP矩阵投影到单通道特征映射中。然后,将CP特征图逐元素与输入图像相乘,并作为附加通道连接到输入图像。自适应网络的结构如图3的左上角所示。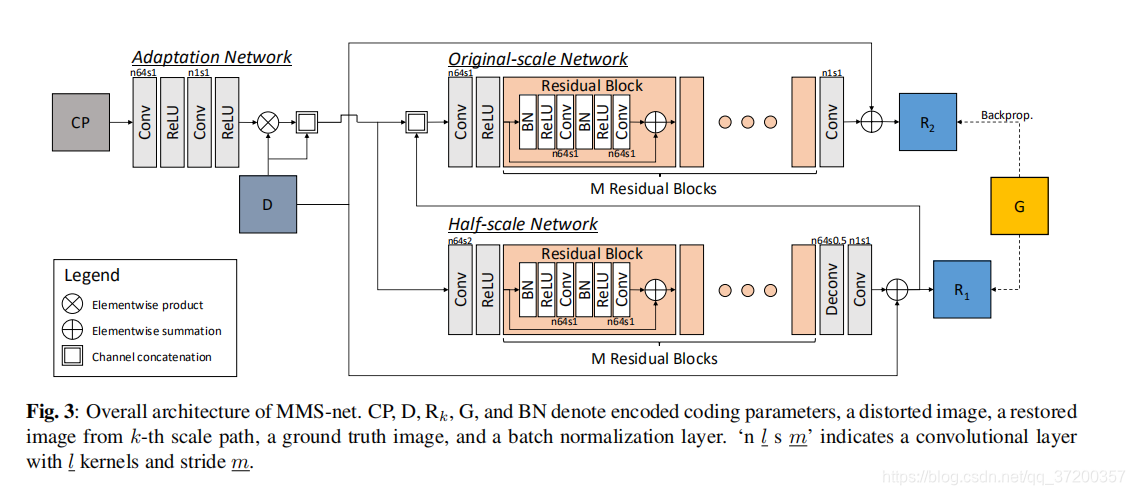
2.3. 模型结构
近年来,多尺度图像复原体系结构被广泛应用于各种图像复原研究中。多尺度图像复原可以看作是多尺度图像空间中的一个层次化过程,使得复原图像在更精细的尺度上保留小细节,在更粗的尺度上保留长距离的相关性。例如,Nah等人。[9] 从模糊图像中创建三级高斯金字塔图像,并将其用作对应于每个尺度的CNNs的输入,以进行去模糊操作。粗糙到精细恢复的概念已被证明在锐化严重模糊的图像中是有用的。同样,我们提出的模型有两个不同尺度的连续子网络(K=2)。粗尺度网络从一半缩小的输入图像中恢复失真图像,而细尺度网络通过将来自粗尺度网络的重建图像和原始失真图像两者作为输入来输出恢复的图像。在粗尺度网络中,我们没有从网络外部调整输入图像的大小,而是使用步长为2的卷积层进行下采样,使用反卷积层进行上采样。这种嵌入网络的插值结构简化了整个系统的处理过程。
每个比例尺度的子网结构都是SRResnet的修改版本[8]。网络的基本构建单元是剩余块[15]。每个剩余块包含两个连续的子模块,由一个批处理规范化层、一个ReLU层和一个卷积层组成。每个残差块的输入和输出之间的跳跃连接直接将输入信号传播到输出,因此具有卷积层的子模块学习输入信号上的残差特征。类似地,每个子网络的输入和输出之间的全局跳过连接[7]会引导网络在失真图像上生成还原图像的残差。我们对每个尺度路径使用M个残差块。网络中的所有卷积层都使用3×3的卷积核,除了每个尺度的子网络的第一卷积层使用7×7的卷积核外。在每个卷积层的边界上添加填充,以使输入和输出维度相同。图3用总体架构描述了每个卷积层的内核数和跨步数。
注意,所提出的模型没有全连接层,因此,这是一个完全卷积的神经网络[16],它可以生成与输入相同大小的图像。
2.4. 多尺度损失
每个子网的损失分别由子网输出与GT图像之间的MSE准则计算。然后,总损失定义如下: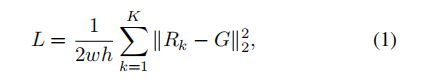
其中,Rk、G、K分别表示第K子网的输出、GT图像和子网的数目(比例)。通过输入图像的宽度w和高度h对损失进行归一化。请注意,第k级子网的损失通过网络反向传播,并与提议架构中的(k-1)级损失一起累积。
2.5. 训练
对于训练数据集,我们使用来自Xiph.org视频测试媒体的28个YCBCR420颜色格式的高清序列[17]。由于GPU内存有限,我们将序列裁剪为176×144大小。在每个裁剪序列中,在HEVC编码过程中(使用HM 16.7软件[2])从环路滤波器前捕获输入训练图像,并将原始序列用作GT图像。 网络实现采用Caffe[18]框架。我们使用ADAM[19]优化器运行了3×105次训练迭代。学习速率自适应地从1×10-3调整到5×10-6,直到损失收敛。
3. 实验结果
3.1. 测试环境
实验中,在JCT-VC通用测试条件[20]的测试序列上进行了测试。我们的模型只在帧的Y通道上训练,但是我们也应用了该模型来恢复U,V通道。编码器配置设置为“All Intra-Main”配置。根据QP22、QP27、QP32和QP37使用HEVC编码器相应QP设置的训练图像训练4个不同的模型。
3.2. 网络消融研究
为了研究模型的各个组成部分对性能的影响,我们进行了几个可变组成部分的控制实验。在这个实验中,我们的方法在类D[20]中的所有序列上进行评估。
首先,我们比较了单尺度网络和多尺度网络。表1显示多尺度网络将性能提高了0.08-0.14db。此外,附加的编码参数CU和TU也提高了输出图像的峰值信噪比。沿输入图像的通道轴连接CP图像在5个残差块网络中很有用,但对于15个残差块网络则更糟。然而,对于5个和15个残差块网络,通过CP自适应网络(pre-network)获得0.08db的增益。我们可以观察到,CP信息有助于压缩伪影的局部化,但它需要预处理网络来关联不同的模式。在5个残差分块网络中使用CP比没有CP的15个残差分块网络性能稍好,因此可以通过牺牲较小的性能增益将计算量减少到三分之一。
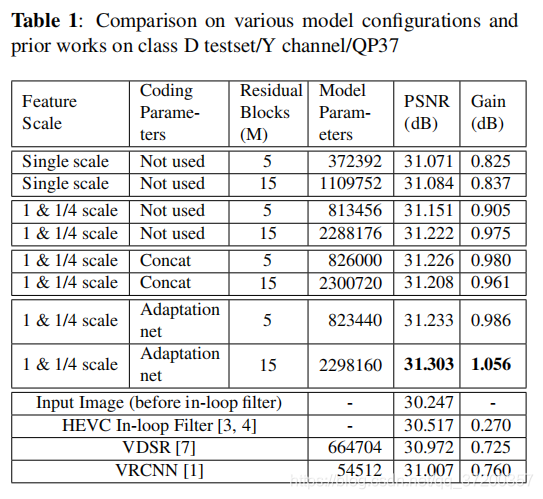
表1中还包括先前工作的PSNR和模型参数的数量[1,7]。尽管VDSR比VRCNN具有更多的变量,但它无法找到更好的最优点,性能也不如VRCNN。该方法利用残差网络的结构和成批规范化层,可以缓解收敛到局部极小值的问题。
3.3. 与最先进的方法比较
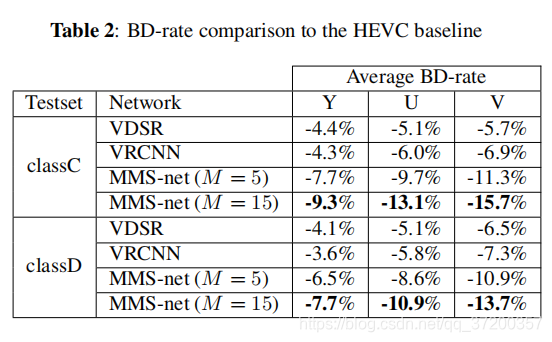
我们还根据BD速率度量将MMS-net与现有的最先进网络进行比较。为了公平比较,我们在训练数据集上训练了VDSR[7]和VRCNN[1],直到这些模型收敛。由于GPU内存的限制,我们只对C类和D类序列的模型进行了测试。在表2中,MMS-net(M = 15)通过在HEVC基准上降低Y通道的平均8.5%的BD-rate,从而获得了卓越的性能。在模型泛化方面,值得注意的是,该模型在176×144图像上训练,但对于较大分辨率的图像效果同样很好。此外,该模型仅在Y通道上训练,但进一步降低了U和V通道上的BD-rate。
对于主观质量比较,一些示例图像如图1所示。结果表明,提出的MMS网络在保持图像主要内容和锐利边缘的同时,有效地去除了图像中的块效应。

4. 结论
在本文中,我们提出了一种新的多模式/多尺度卷积神经网络(MMS Net)架构,以取代现有的HEVC环路滤波器。MMS网络可以利用压缩比特流中的CTU信息成功地去除阻塞伪影。此外,多尺度网络的由粗到细的方法被证明有利于图像的量化恢复。在今后的工作中,我们将探索如何利用其他编码信息,如QP、运动矢量和帧内预测模式,进行图像恢复。
