摘要
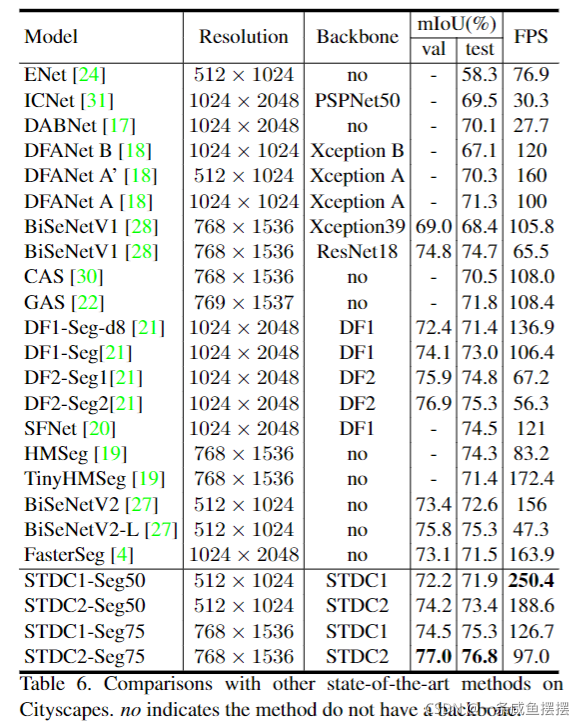
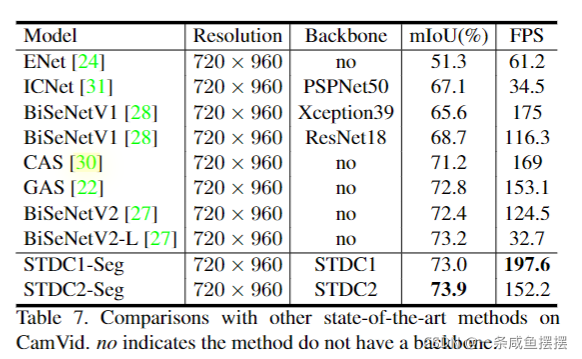
BiSeNet已被证明是一种用于实时分割的流行的双边网络。然而,它添加额外路径已编码空间信息的原理是耗时的,并且由于特定任务设计的不足,从预训练的任务(如图像分类)中借用骨干网络来进行语义分割可能是低效的。为了解决这些问题,我们提出了一种新的高效的结构,即短时密集连接网络(Short-Term Dense concatenate network, STDC network)。具体来说,我们逐步降低特征图的维数,并利用特征图的聚集来进行图像表示,形成了STDC网络的基本模块。在解码器中,我们提出了一个Detail Aggregation module(以下称为细节聚合模块),以单流的方式将学习到的空间信息集成到底层中。最后,融合底层特征和深层特征来预测最终的分割结果。在城市景观和CamVid数据集上的大量实验证明了我们的方法的有效性,在分割精度和推理速度之间取得了良好的平衡。在NVIDIA GTX 1080Ti上,我们以250.4 FPS的速度在测试集上实现了71.9%的mIoU,比最新的方法快了45.2%,在更高分辨率的图像上,以97.0 FPS的速度实现了76.8%的mIoU。
引言
许多研究者提出设计低延迟、高效率的CNN模型,并满足分割精度。这些实时语义分割方法在各种基准测试中都取得了很好的性能。对于实时推理,如DFANet[18]和BiSeNetV1[28]选择了轻量级主干,并研究了特征融合或聚合模块的方法来补偿精度的下降。然而,由于特定任务设计的不足,这些从图像分类任务中剥离出来的轻量级主干可能不能很好地解决图像分割问题。除了选择轻量级骨架外,限制输入图像的大小是提高推理速度的另一种常用方法。较小的输入分辨率似乎是有效的,但它很容易忽略边界和小物体周围的详细外观。为了解决这个问题,如图2(a)所示,BiSeNet[28, 27]采用多路径框架将底层细节和高层语义结合起来。然而,添加附加路径获取底层特征耗时较长,辅助路径往往缺乏底层信息引导。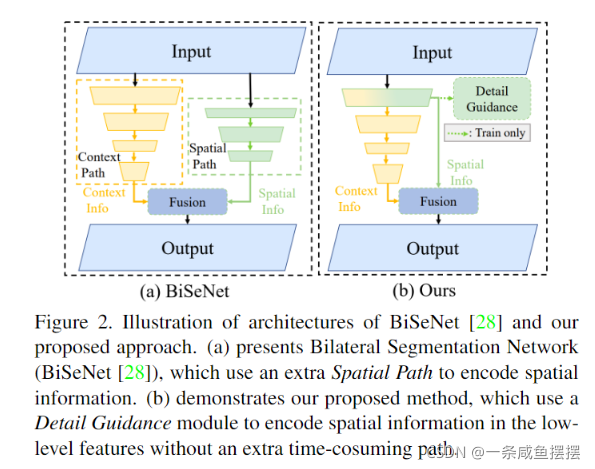
为此,我们提出了一种新的网络,以提高推理速度、结构可解释和性能优于现有方法。首先,我们设计了一种新的结构,称为短期密集连接模块(Short-Term density Concatenate module, STDC模块),以获得具有少量参数的可变感受野。然后,将STDC模块无缝集成到U-net架构中,形成STDC网络,大大提高了网络在语义分割任务中的性能。
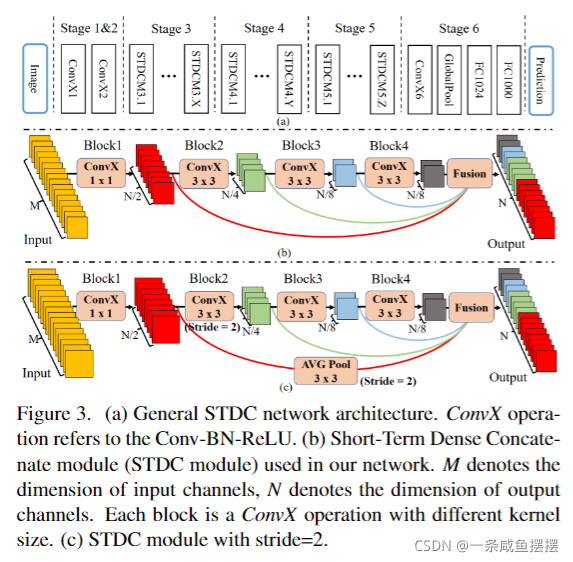
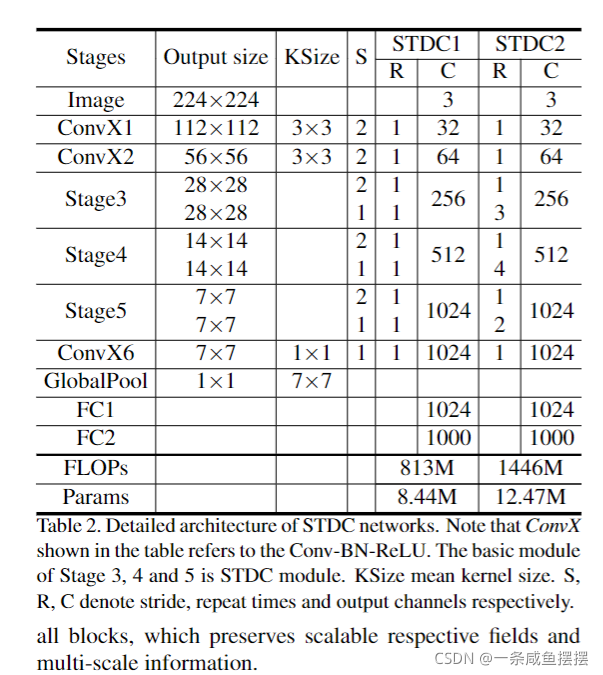
具体来说,如图3所示,我们将来自多个连续层的特征图连接起来,每个层对不同尺度和各自领域的输入图像/特征进行编码,从而实现多尺度特征表示。为了加快速度,层的卷积核尺寸逐渐减小,分割性能的损失可以忽略不计。STDC网络的详细结构表2所示。
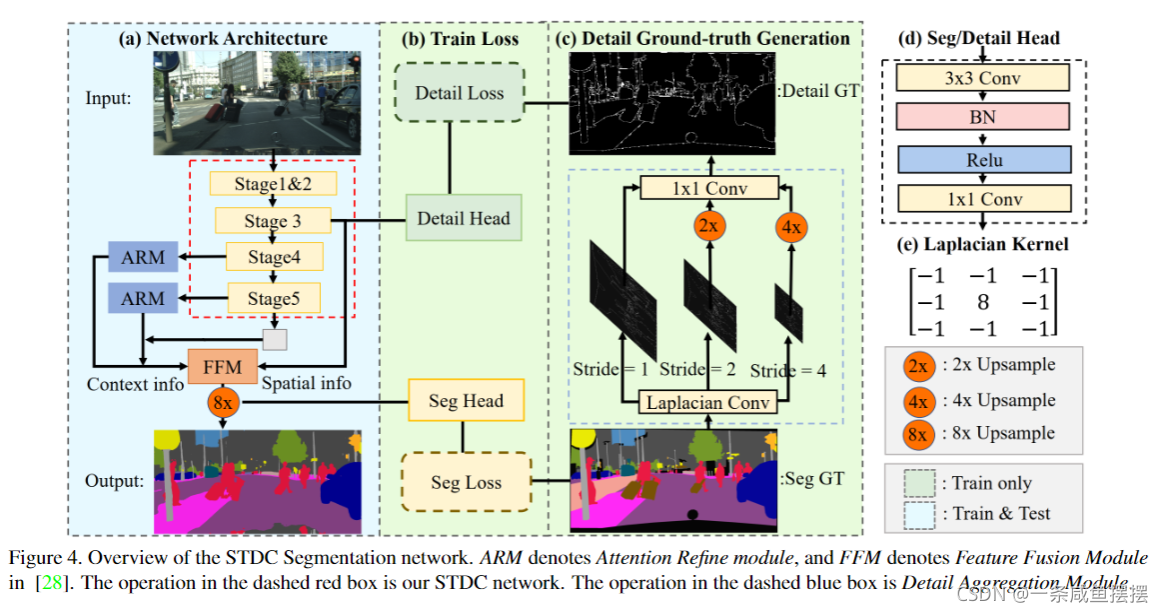
在解码阶段,如图2(b)所示,没有采用额外耗时的路径,而是采用Detail Guidance细节引导来引导底层对空间细节的学习。我们首先利用细节聚合模块生成细节GT。然后利用二元交叉熵和Dice loss对细节信息学习任务进行优化。最后,融合底层的空间细节信息和深层的语义信息来预测语义分割的结果。整个网络结构如图4所示。
主要贡献
- 设计了一个短时密集连接级联模块STDC,用于提取具有可扩展感受野和多尺度的深层信息
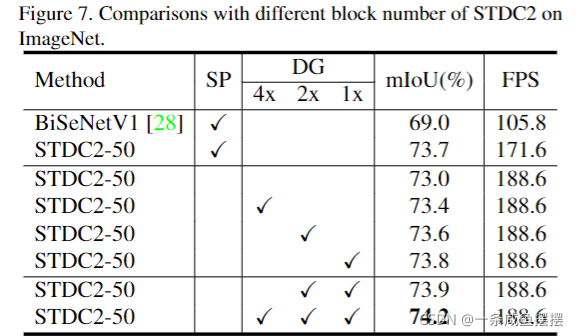
- 提出细节聚合模块来学习解码器,从而更精确的保存底层的空间信息,而无需在推断时间上有额外的计算成本。
网络设计
编码网络的设计–STDC模块
我们提出的网络的关键组成部分是短期密集级联模块STDC,图3(b)©说明了STDC模块的结构。
在STDC模块中,第一个block的kernel size为1,其余部分简单的设置为3,给定STDC模块输出的通道数为N,则第i块卷积层的通道数为N/2**i,除了最后一层通道数,其与前一层的通道数相同。在图像分类任务中,通常的做法是在更高的层上使用更多的通道,但在语义分割任务上,我们关注的是可扩展的感受野和多尺度信息。低的层需要足够的通道来通过小的感受野编码更细粒度的信息,而高的层通过大的感受野更注重高层信息的引导,与低层设置相同的通道可能会导致信息冗余。降采样只在block2中使用。为了丰富特征信息,通过跳接结构将x1-xn的特征映射作为STDC模块的输出。拼接前,将STDC模块不同block的响应映射通过3*3平均池化下采样到相同的空间大小,如图3©所示。
网络结构
在图3(a)展示了网络架构。它由输入层和预测层之外的6个阶段组成。通常,阶段1-5分别以s=2的步长进行下采样,第6阶段通过一个conv,一个全局平均池化和两个全连接层输出预测。
阶段1和阶段2通常被认为是特征提取的低层。为了追求效率,我们只在阶段1和2中使用一个卷积块,根据我们的经验证明这是足够的。阶段3、4、5中的STDC模块的数量在我们的网络中进行了仔细的调整。在这些阶段中,每个阶段的第一个STDC模块以s=2的步长进行下采样,然后后面的STDC模块保持分辨率不变。表2显示了STDC的详细结构。
解码器设计
分割架构
我们使用预训练的STDC网络作为编码器的骨干,采用BiseNet的上下文路径对上下文信息进行编码。如图4(a)所示,我们使用阶段3、4、5分别生成下采样率为1/8、1/16,1/32的特征图。然后我们使用全局平均池化来提供具有大的感受野的全局上下文信息。U型结构用于对来自全局特征进行上采样,并将它们与编码器最后两个阶段(4、5)的对于特征相结合。在BiseNet之后,我们使用ARM模块对每两个阶段的组合特征进行优化。对于最终的语义分割预测,我们采用BiseNet中的FFM模块,将编码器中的第3阶段的1/8下采样特征与解码器中的对应特征进行融合。来自编码主干的特征保留的丰富的细节信息,而来自解码器的特征由于来自全局池化而包含上下文信息。具体来说,Seg Head包含一个3×3 convn - bn - relu运算符,后面跟着一个1 ×1卷积,以得到输出维数N,它被设置为类的数量。我们采用交叉入口损失和在线硬样本挖掘来优化语义分割学习任务。
Detail Guidance of Low-level Features
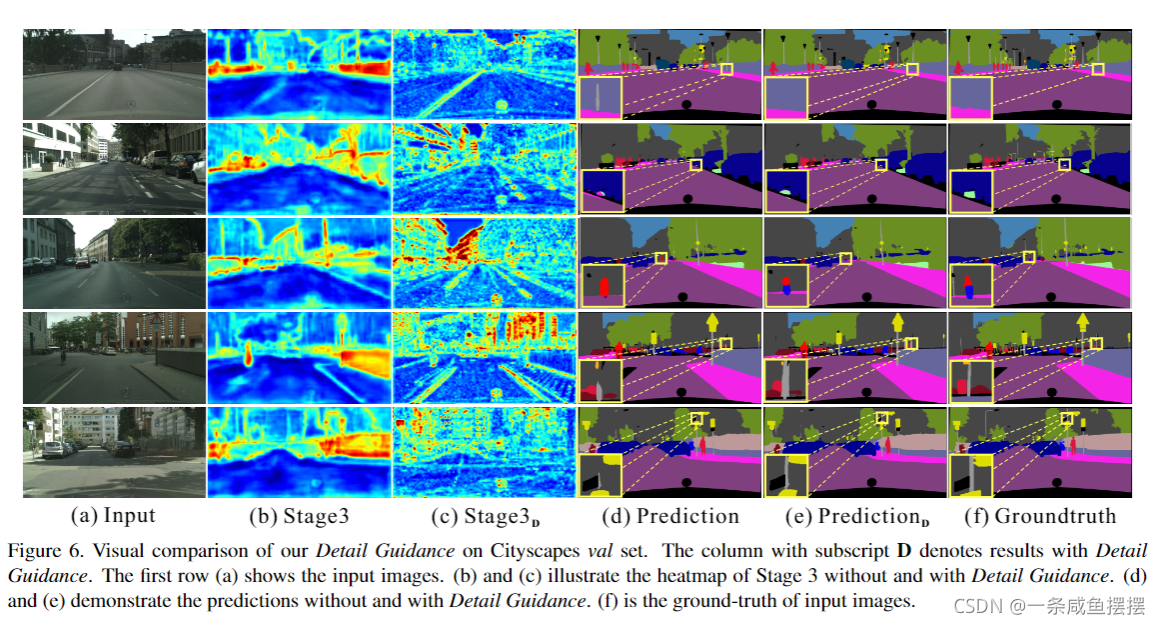
我们可视化BiseNet在图5(b)中的空间路径的特征。与骨干网络的具有相同下采样率的低级特征(阶段3)相比,空间路径可以编码更多的空间细节信息,如边界,角落。基于此,我们提出了一个细节引导模块,以单流的方式引导底层学习空间信息。首先,我们通过拉普拉斯算子从分割的GT中生成细节图GT,如图4©所示。我们在阶段3中插入Detail Head来生成细节特征图。然后利用细节GT作为细节特征图的引导,引导底层学习空间细节特征。如图5(d)所示,具有细节引导的特征图可以编码比图5©所示结果更多的空间细节。最后,将学习到的细节特征与解码器的上下文特征融合,进行分割预测。
Detail Ground-truth Generation
我们通过我们的细节聚合模块从语义分割GT生成了二进制细节的GT,如图4(c)的虚线框所示。该操作可以由名为Laplacian内核的2-D卷积内核和可训练的1×1卷积进行。我们使用图4(e)所示的Laplacian操作来生成不同步长的细节特征图,以获得多尺度细节信息。然后我们将细节特征上采样到原始大小,并将其与可训练的1×1卷积融合,以便动态加权。。最后,我们采用阈值0.1将预测的细节转换为带有边界和角点信息的最终二值细节GT。
Detail loss
由于产生的 detail GT 前景较少,背景较多,直接用 binary cross-entropy 监督容易导致正负样本不均衡,作者在 binary cross-entropy 基础上,辅助了 Dice Loss
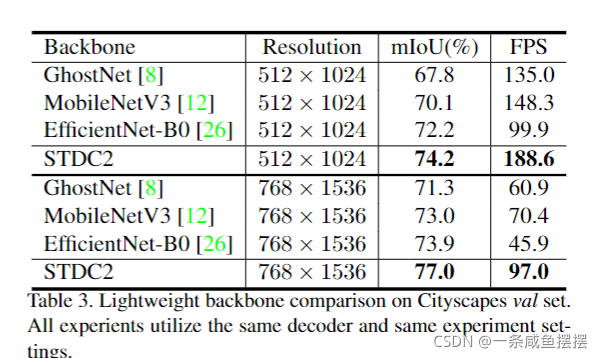
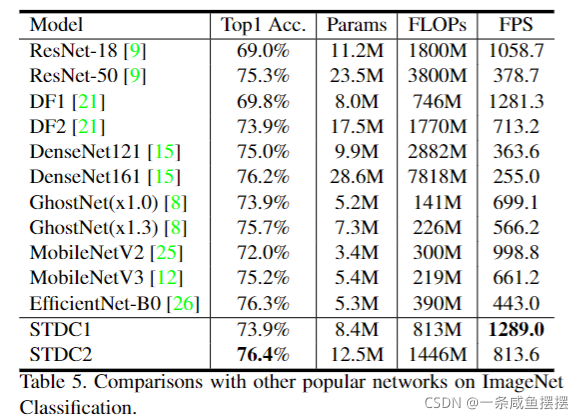
实验