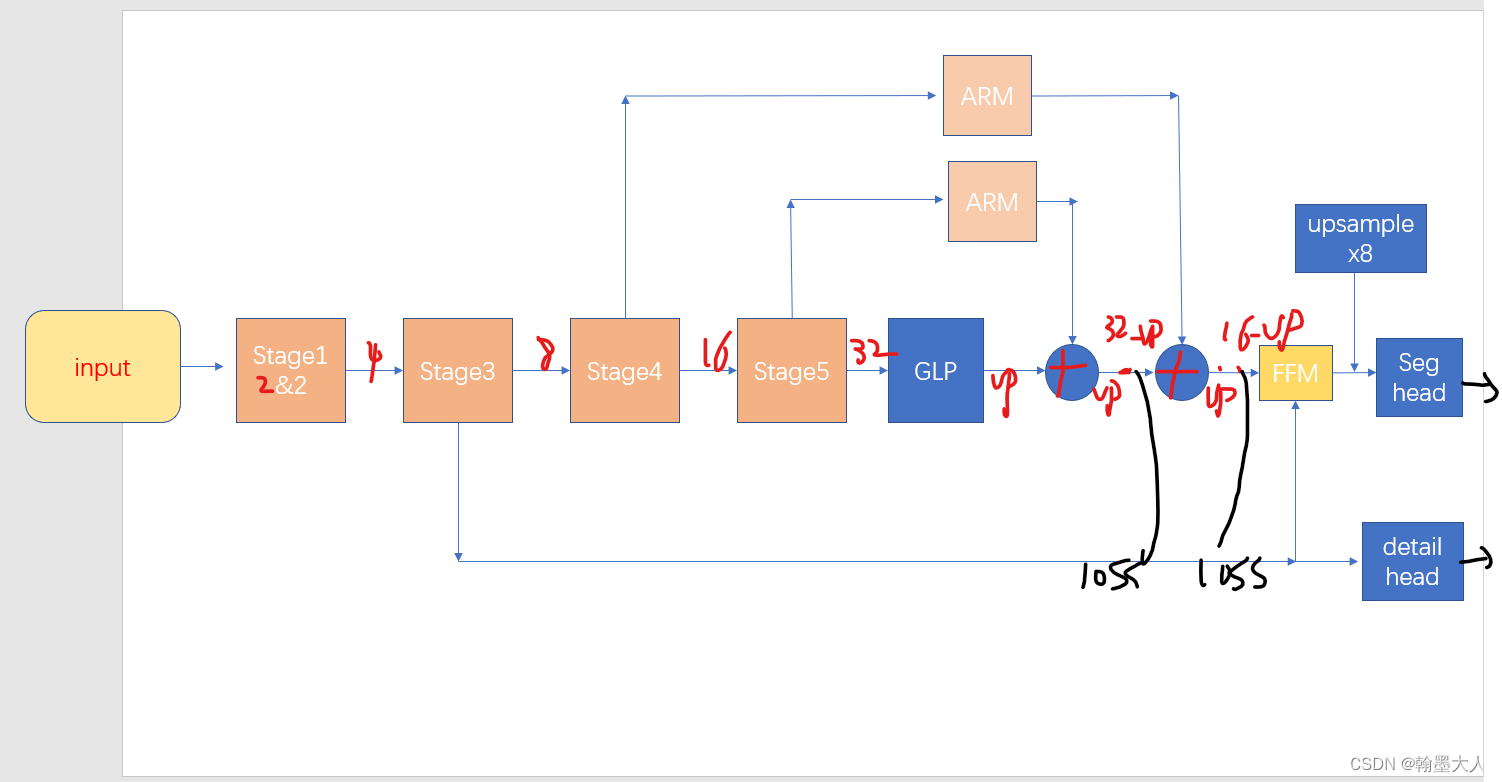
精简了一下代码,backbone采用的STDCNet813。
#!/usr/bin/python
# -*- encoding: utf-8 -*-
import torch
import torch.nn as nn
import torch.nn.functional as F
import torchvision
from nets.stdcnet import STDCNet1446, STDCNet813
from modules.bn import InPlaceABNSync as BatchNorm2d
# BatchNorm2d = nn.BatchNorm2d
class ConvBNReLU(nn.Module):
def __init__(self, in_chan, out_chan, ks=3, stride=1, padding=1, *args, **kwargs):
super(ConvBNReLU, self).__init__()
self.conv = nn.Conv2d(in_chan,
out_chan,
kernel_size = ks,
stride = stride,
padding = padding,
bias = False)
# self.bn = BatchNorm2d(out_chan)
self.bn = BatchNorm2d(out_chan, activation='none')
self.relu = nn.ReLU()
self.init_weight()
def forward(self, x):
x = self.conv(x)
x = self.bn(x)
x = self.relu(x)
return x
class BiSeNetOutput(nn.Module):
def __init__(self, in_chan, mid_chan, n_classes, *args, **kwargs):
super(BiSeNetOutput, self).__init__()
self.conv = ConvBNReLU(in_chan, mid_chan, ks=3, stride=1, padding=1)
self.conv_out = nn.Conv2d(mid_chan, n_classes, kernel_size=1, bias=False)
self.init_weight()
def forward(self, x):
x = self.conv(x)
x = self.conv_out(x)
return x
class AttentionRefinementModule(nn.Module):
def __init__(self, in_chan, out_chan, *args, **kwargs):
super(AttentionRefinementModule, self).__init__()
self.conv = ConvBNReLU(in_chan, out_chan, ks=3, stride=1, padding=1)
self.conv_atten = nn.Conv2d(out_chan, out_chan, kernel_size= 1, bias=False)
# self.bn_atten = BatchNorm2d(out_chan)
self.bn_atten = BatchNorm2d(out_chan, activation='none')
self.sigmoid_atten = nn.Sigmoid()
self.init_weight()
def forward(self, x):
feat = self.conv(x)
atten = F.avg_pool2d(feat, feat.size()[2:])
atten = self.conv_atten(atten)
atten = self.bn_atten(atten)
atten = self.sigmoid_atten(atten)
out = torch.mul(feat, atten)
return out
class ContextPath(nn.Module):
def __init__(self, backbone='CatNetSmall', pretrain_model='', use_conv_last=False, *args, **kwargs):
super(ContextPath, self).__init__()
self.backbone_name = backbone
self.backbone = STDCNet813(pretrain_model=pretrain_model, use_conv_last=use_conv_last)
self.arm16 = AttentionRefinementModule(512, 128)
inplanes = 1024
self.arm32 = AttentionRefinementModule(inplanes, 128)
self.conv_head32 = ConvBNReLU(128, 128, ks=3, stride=1, padding=1)
self.conv_head16 = ConvBNReLU(128, 128, ks=3, stride=1, padding=1)
self.conv_avg = ConvBNReLU(inplanes, 128, ks=1, stride=1, padding=0)
def forward(self, x):
H0, W0 = x.size()[2:]
feat2, feat4, feat8, feat16, feat32 = self.backbone(x)
H8, W8 = feat8.size()[2:]
H16, W16 = feat16.size()[2:]
H32, W32 = feat32.size()[2:]
avg = F.avg_pool2d(feat32, feat32.size()[2:])
avg = self.conv_avg(avg)
avg_up = F.interpolate(avg, (H32, W32), mode='nearest')
feat32_arm = self.arm32(feat32)
feat32_sum = feat32_arm + avg_up
feat32_up = F.interpolate(feat32_sum, (H16, W16), mode='nearest')
feat32_up = self.conv_head32(feat32_up)
feat16_arm = self.arm16(feat16)
feat16_sum = feat16_arm + feat32_up
feat16_up = F.interpolate(feat16_sum, (H8, W8), mode='nearest')
feat16_up = self.conv_head16(feat16_up)
return feat2, feat4, feat8, feat16, feat16_up, feat32_up # x8, x16
class FeatureFusionModule(nn.Module):
def __init__(self, in_chan, out_chan, *args, **kwargs):
super(FeatureFusionModule, self).__init__()
self.convblk = ConvBNReLU(in_chan, out_chan, ks=1, stride=1, padding=0)
self.conv1 = nn.Conv2d(out_chan,
out_chan//4,
kernel_size = 1,
stride = 1,
padding = 0,
bias = False)
self.conv2 = nn.Conv2d(out_chan//4,
out_chan,
kernel_size = 1,
stride = 1,
padding = 0,
bias = False)
self.relu = nn.ReLU(inplace=True)
self.sigmoid = nn.Sigmoid()
self.init_weight()
def forward(self, fsp, fcp):
fcat = torch.cat([fsp, fcp], dim=1)
feat = self.convblk(fcat)
atten = F.avg_pool2d(feat, feat.size()[2:])
atten = self.conv1(atten)
atten = self.relu(atten)
atten = self.conv2(atten)
atten = self.sigmoid(atten)
feat_atten = torch.mul(feat, atten)
feat_out = feat_atten + feat
return feat_out
class BiSeNet(nn.Module):
def __init__(self, backbone, n_classes, pretrain_model='', use_boundary_2=False, use_boundary_4=False, use_boundary_8=False, use_boundary_16=False, use_conv_last=False, heat_map=False, *args, **kwargs):
super(BiSeNet, self).__init__()
self.use_boundary_2 = use_boundary_2
self.use_boundary_4 = use_boundary_4
self.use_boundary_8 = use_boundary_8
self.use_boundary_16 = use_boundary_16
# self.heat_map = heat_map
self.cp = ContextPath(backbone, pretrain_model, use_conv_last=use_conv_last)
conv_out_inplanes = 128
sp2_inplanes = 32
sp4_inplanes = 64
sp8_inplanes = 256
sp16_inplanes = 512
inplane = sp8_inplanes + conv_out_inplanes
self.ffm = FeatureFusionModule(inplane, 256)
self.conv_out = BiSeNetOutput(256, 256, n_classes)
self.conv_out16 = BiSeNetOutput(conv_out_inplanes, 64, n_classes)
self.conv_out32 = BiSeNetOutput(conv_out_inplanes, 64, n_classes)
self.conv_out_sp16 = BiSeNetOutput(sp16_inplanes, 64, 1)
self.conv_out_sp8 = BiSeNetOutput(sp8_inplanes, 64, 1)
self.conv_out_sp4 = BiSeNetOutput(sp4_inplanes, 64, 1)
self.conv_out_sp2 = BiSeNetOutput(sp2_inplanes, 64, 1)
self.init_weight()
def forward(self, x):
H, W = x.size()[2:]
feat_res2, feat_res4, feat_res8, feat_res16, feat_cp8, feat_cp16 = self.cp(x)
feat_out_sp2 = self.conv_out_sp2(feat_res2)
feat_out_sp4 = self.conv_out_sp4(feat_res4)
feat_out_sp8 = self.conv_out_sp8(feat_res8)
feat_out_sp16 = self.conv_out_sp16(feat_res16)
feat_fuse = self.ffm(feat_res8, feat_cp8)
feat_out = self.conv_out(feat_fuse)
feat_out16 = self.conv_out16(feat_cp8)
feat_out32 = self.conv_out32(feat_cp16)
feat_out = F.interpolate(feat_out, (H, W), mode='bilinear', align_corners=True)
feat_out16 = F.interpolate(feat_out16, (H, W), mode='bilinear', align_corners=True)
feat_out32 = F.interpolate(feat_out32, (H, W), mode='bilinear', align_corners=True)
if self.use_boundary_2 and self.use_boundary_4 and self.use_boundary_8:
return feat_out, feat_out16, feat_out32, feat_out_sp2, feat_out_sp4, feat_out_sp8
if (not self.use_boundary_2) and self.use_boundary_4 and self.use_boundary_8:
return feat_out, feat_out16, feat_out32, feat_out_sp4, feat_out_sp8
if (not self.use_boundary_2) and (not self.use_boundary_4) and self.use_boundary_8:
return feat_out, feat_out16, feat_out32, feat_out_sp8
if (not self.use_boundary_2) and (not self.use_boundary_4) and (not self.use_boundary_8):
return feat_out, feat_out16, feat_out32
if __name__ == "__main__":
net = BiSeNet('STDCNet813', 19)
net.cuda()
net.eval()
in_ten = torch.randn(1, 3, 768, 1536).cuda()
out, out16, out32 = net(in_ten)
print(out.shape)
看一下主函数:
class BiSeNet(nn.Module):
def __init__(self, backbone, n_classes, pretrain_model='', use_boundary_2=False, use_boundary_4=False, use_boundary_8=False, use_boundary_16=False, use_conv_last=False, heat_map=False, *args, **kwargs):
super(BiSeNet, self).__init__()
self.use_boundary_2 = use_boundary_2
self.use_boundary_4 = use_boundary_4
self.use_boundary_8 = use_boundary_8
self.use_boundary_16 = use_boundary_16
# self.heat_map = heat_map
self.cp = ContextPath(backbone, pretrain_model, use_conv_last=use_conv_last)
conv_out_inplanes = 128
sp2_inplanes = 32
sp4_inplanes = 64
sp8_inplanes = 256
sp16_inplanes = 512
inplane = sp8_inplanes + conv_out_inplanes
self.ffm = FeatureFusionModule(inplane, 256)
self.conv_out = BiSeNetOutput(256, 256, n_classes)
self.conv_out16 = BiSeNetOutput(conv_out_inplanes, 64, n_classes)
self.conv_out32 = BiSeNetOutput(conv_out_inplanes, 64, n_classes)
self.conv_out_sp16 = BiSeNetOutput(sp16_inplanes, 64, 1)
self.conv_out_sp8 = BiSeNetOutput(sp8_inplanes, 64, 1)
self.conv_out_sp4 = BiSeNetOutput(sp4_inplanes, 64, 1)
self.conv_out_sp2 = BiSeNetOutput(sp2_inplanes, 64, 1)
self.init_weight()
def forward(self, x):
H, W = x.size()[2:]
feat_res2, feat_res4, feat_res8, feat_res16, feat_cp8, feat_cp16 = self.cp(x)
feat_out_sp2 = self.conv_out_sp2(feat_res2)
feat_out_sp4 = self.conv_out_sp4(feat_res4)
feat_out_sp8 = self.conv_out_sp8(feat_res8)
feat_out_sp16 = self.conv_out_sp16(feat_res16)
feat_fuse = self.ffm(feat_res8, feat_cp8)
feat_out = self.conv_out(feat_fuse)
feat_out16 = self.conv_out16(feat_cp8)
feat_out32 = self.conv_out32(feat_cp16)
feat_out = F.interpolate(feat_out, (H, W), mode='bilinear', align_corners=True)
feat_out16 = F.interpolate(feat_out16, (H, W), mode='bilinear', align_corners=True)
feat_out32 = F.interpolate(feat_out32, (H, W), mode='bilinear', align_corners=True)
if self.use_boundary_2 and self.use_boundary_4 and self.use_boundary_8:
return feat_out, feat_out16, feat_out32, feat_out_sp2, feat_out_sp4, feat_out_sp8
if (not self.use_boundary_2) and self.use_boundary_4 and self.use_boundary_8:
return feat_out, feat_out16, feat_out32, feat_out_sp4, feat_out_sp8
if (not self.use_boundary_2) and (not self.use_boundary_4) and self.use_boundary_8:
return feat_out, feat_out16, feat_out32, feat_out_sp8
if (not self.use_boundary_2) and (not self.use_boundary_4) and (not self.use_boundary_8):
return feat_out, feat_out16, feat_out32
1:输入x,经过self.cp,
elf.cp = ContextPath(backbone, pretrain_model, use_conv_last=use_conv_last)
跳到context path中,
class ContextPath(nn.Module):
def __init__(self, backbone='CatNetSmall', pretrain_model='', use_conv_last=False, *args, **kwargs):
super(ContextPath, self).__init__()
self.backbone_name = backbone
self.backbone = STDCNet813(pretrain_model=pretrain_model, use_conv_last=use_conv_last)
self.arm16 = AttentionRefinementModule(512, 128)
inplanes = 1024
self.arm32 = AttentionRefinementModule(inplanes, 128)
self.conv_head32 = ConvBNReLU(128, 128, ks=3, stride=1, padding=1)
self.conv_head16 = ConvBNReLU(128, 128, ks=3, stride=1, padding=1)
self.conv_avg = ConvBNReLU(inplanes, 128, ks=1, stride=1, padding=0)
def forward(self, x):
H0, W0 = x.size()[2:]
feat2, feat4, feat8, feat16, feat32 = self.backbone(x)
H8, W8 = feat8.size()[2:]
H16, W16 = feat16.size()[2:]
H32, W32 = feat32.size()[2:]
avg = F.avg_pool2d(feat32, feat32.size()[2:])
avg = self.conv_avg(avg)
avg_up = F.interpolate(avg, (H32, W32), mode='nearest')
feat32_arm = self.arm32(feat32)
feat32_sum = feat32_arm + avg_up
feat32_up = F.interpolate(feat32_sum, (H16, W16), mode='nearest')
feat32_up = self.conv_head32(feat32_up)
feat16_arm = self.arm16(feat16)
feat16_sum = feat16_arm + feat32_up
feat16_up = F.interpolate(feat16_sum, (H8, W8), mode='nearest')
feat16_up = self.conv_head16(feat16_up)
return feat2, feat4, feat8, feat16, feat16_up, feat32_up # x8, x16
1.1:首先经过backbone,输出feat2, feat4, feat8, feat16, feat32,即每一个stage的输出。
1.2:然后获得feat8, feat16, feat32的长和宽。
1.3:然后对feat32进行全局平均池化,尺寸由(b,c,h,w)变为(b,c,1,1),再经过 self.conv_avg将通道由1024变为128。在将avg_up上采样到feat32大小。
1.4:将feat32经过ARM模块,
self.arm32 = AttentionRefinementModule(inplanes, 128)
class AttentionRefinementModule(nn.Module):
def __init__(self, in_chan, out_chan, *args, **kwargs):
super(AttentionRefinementModule, self).__init__()
self.conv = ConvBNReLU(in_chan, out_chan, ks=3, stride=1, padding=1)
self.conv_atten = nn.Conv2d(out_chan, out_chan, kernel_size= 1, bias=False)
# self.bn_atten = BatchNorm2d(out_chan)
self.bn_atten = BatchNorm2d(out_chan, activation='none')
self.sigmoid_atten = nn.Sigmoid()
self.init_weight()
def forward(self, x):
feat = self.conv(x)
atten = F.avg_pool2d(feat, feat.size()[2:])
atten = self.conv_atten(atten)
atten = self.bn_atten(atten)
atten = self.**sigmoid_atten**(atten)
out = torch.mul(feat, atten)
return out
1.4.1:首先将x经过一个卷积,再将feat经过平均池化,大小变为(b,c,1,1)。再经过卷积,激活函数变为sigmoid,再与feat相乘。
1.5:将avg_up与arm的特征相加,经过1x1卷积融合,上采样,再与经过arm的stage4输出,相加,经过1x1卷积融合,上采样。
1.6:输出feat2, feat4, feat8, feat16, feat16_up, feat32_up
2:经过context即self.cp之后,对encoder的stage2,4,8,16的输出进过 self.conv_out_sp2,
self.conv_out_sp8 = BiSeNetOutput(sp8_inplanes, 64, 1)
self.conv_out_sp4 = BiSeNetOutput(sp4_inplanes, 64, 1)
self.conv_out_sp2 = BiSeNetOutput(sp2_inplanes, 64, 1)
class BiSeNetOutput(nn.Module):
def __init__(self, in_chan, mid_chan, n_classes, *args, **kwargs):
super(BiSeNetOutput, self).__init__()
self.conv = ConvBNReLU(in_chan, mid_chan, ks=3, stride=1, padding=1)
self.conv_out = nn.Conv2d(mid_chan, n_classes, kernel_size=1, bias=False)
self.init_weight()
def forward(self, x):
x = self.conv(x)
x = self.conv_out(x)
return x
2.1:特征图首先经过一个3x3卷积,将通道降维,然后再经过1x1卷积,输出通道为1。
3:将stage4特征经过arm,融合并上采样的的特征图 和 stage3经过卷积输出通道为1的特征图输入到ffm模块。
self.ffm = FeatureFusionModule(inplane, 256)
class FeatureFusionModule(nn.Module):
def __init__(self, in_chan, out_chan, *args, **kwargs):
super(FeatureFusionModule, self).__init__()
self.convblk = ConvBNReLU(in_chan, out_chan, ks=1, stride=1, padding=0)
self.conv1 = nn.Conv2d(out_chan,
out_chan//4,
kernel_size = 1,
stride = 1,
padding = 0,
bias = False)
self.conv2 = nn.Conv2d(out_chan//4,
out_chan,
kernel_size = 1,
stride = 1,
padding = 0,
bias = False)
self.relu = nn.ReLU(inplace=True)
self.sigmoid = nn.Sigmoid()
self.init_weight()
def forward(self, fsp, fcp):
fcat = torch.cat([fsp, fcp], dim=1)
feat = self.convblk(fcat)
atten = F.avg_pool2d(feat, feat.size()[2:])
atten = self.conv1(atten)
atten = self.relu(atten)
atten = self.conv2(atten)
atten = self.sigmoid(atten)
feat_atten = torch.mul(feat, atten)
feat_out = feat_atten + feat
return feat_out
3.1:在ffm中,首先将输入两个特征拼接经过卷积,再经过平均池化,h和w变为1x1。再经过两个卷积,都不加bn,激活函数为relu和sigmoid,与原始特征相乘,做一个注意力计算,再进行一个残差连接。
4:经过ffm之后的特征经过一个卷积(seg head),输出通道为类别数,再上采样到原始图像大小,即分割输出。
5:对1.6的两个输出也卷积,上采样到原图大小,输出通道为类别数,这一步用来做深监督的,FFM的输出为主损失,其余两个为辅助损失,用来对分割输出进行监督。
6:输出feat_out, feat_out16, feat_out32, feat_out_sp2, feat_out_sp4, feat_out_sp8,前三个用来做分割损失,后三个用来做细节损失。
--------------------------------------------------------------整体框架分析完毕-----------------------------------------------------------------------
然后就是文章比较重要的损失计算。
首先看损失的定义:
在train文件中:
criteria_p = OhemCELoss(thresh=score_thres, n_min=n_min, ignore_lb=ignore_idx)
criteria_16 = OhemCELoss(thresh=score_thres, n_min=n_min, ignore_lb=ignore_idx)
criteria_32 = OhemCELoss(thresh=score_thres, n_min=n_min, ignore_lb=ignore_idx)
boundary_loss_func = DetailAggregateLoss()
7:首先看分割损失就是交叉熵损失。
class OhemCELoss(nn.Module):
def __init__(self, thresh, n_min, ignore_lb=255, *args, **kwargs):
super(OhemCELoss, self).__init__()
self.thresh = -torch.log(torch.tensor(thresh, dtype=torch.float)).cuda()
self.n_min = n_min
self.ignore_lb = ignore_lb
self.criteria = nn.CrossEntropyLoss(ignore_index=ignore_lb, reduction='none')
def forward(self, logits, labels):
N, C, H, W = logits.size()
loss = self.criteria(logits, labels).view(-1)
loss, _ = torch.sort(loss, descending=True)
if loss[self.n_min] > self.thresh:
loss = loss[loss>self.thresh]
else:
loss = loss[:self.n_min]
return torch.mean(loss)
8:接着看边界损失
class DetailAggregateLoss(nn.Module):
def __init__(self, *args, **kwargs):
super(DetailAggregateLoss, self).__init__()
self.laplacian_kernel = torch.tensor(
[-1, -1, -1, -1, 8, -1, -1, -1, -1],
dtype=torch.float32).reshape(1, 1, 3, 3).requires_grad_(False).type(torch.cuda.FloatTensor)
self.fuse_kernel = torch.nn.Parameter(torch.tensor([[6./10], [3./10], [1./10]],
dtype=torch.float32).reshape(1, 3, 1, 1).type(torch.cuda.FloatTensor))
def forward(self, boundary_logits, gtmasks):
# boundary_logits = boundary_logits.unsqueeze(1)
boundary_targets = F.conv2d(gtmasks.unsqueeze(1).type(torch.cuda.FloatTensor), self.laplacian_kernel, padding=1)
boundary_targets = boundary_targets.clamp(min=0)
boundary_targets[boundary_targets > 0.1] = 1
boundary_targets[boundary_targets <= 0.1] = 0
boundary_targets_x2 = F.conv2d(gtmasks.unsqueeze(1).type(torch.cuda.FloatTensor), self.laplacian_kernel, stride=2, padding=1)
boundary_targets_x2 = boundary_targets_x2.clamp(min=0)
boundary_targets_x4 = F.conv2d(gtmasks.unsqueeze(1).type(torch.cuda.FloatTensor), self.laplacian_kernel, stride=4, padding=1)
boundary_targets_x4 = boundary_targets_x4.clamp(min=0)
boundary_targets_x8 = F.conv2d(gtmasks.unsqueeze(1).type(torch.cuda.FloatTensor), self.laplacian_kernel, stride=8, padding=1)
boundary_targets_x8 = boundary_targets_x8.clamp(min=0)
boundary_targets_x8_up = F.interpolate(boundary_targets_x8, boundary_targets.shape[2:], mode='nearest')
boundary_targets_x4_up = F.interpolate(boundary_targets_x4, boundary_targets.shape[2:], mode='nearest')
boundary_targets_x2_up = F.interpolate(boundary_targets_x2, boundary_targets.shape[2:], mode='nearest')
boundary_targets_x2_up[boundary_targets_x2_up > 0.1] = 1
boundary_targets_x2_up[boundary_targets_x2_up <= 0.1] = 0
boundary_targets_x4_up[boundary_targets_x4_up > 0.1] = 1
boundary_targets_x4_up[boundary_targets_x4_up <= 0.1] = 0
boundary_targets_x8_up[boundary_targets_x8_up > 0.1] = 1
boundary_targets_x8_up[boundary_targets_x8_up <= 0.1] = 0
boudary_targets_pyramids = torch.stack((boundary_targets, boundary_targets_x2_up, boundary_targets_x4_up), dim=1)
boudary_targets_pyramids = boudary_targets_pyramids.squeeze(2)
boudary_targets_pyramid = F.conv2d(boudary_targets_pyramids, self.fuse_kernel)
boudary_targets_pyramid[boudary_targets_pyramid > 0.1] = 1
boudary_targets_pyramid[boudary_targets_pyramid <= 0.1] = 0
if boundary_logits.shape[-1] != boundary_targets.shape[-1]:
boundary_logits = F.interpolate(
boundary_logits, boundary_targets.shape[2:], mode='bilinear', align_corners=True)
bce_loss = F.binary_cross_entropy_with_logits(boundary_logits, boudary_targets_pyramid)
dice_loss = dice_loss_func(torch.sigmoid(boundary_logits), boudary_targets_pyramid)
return bce_loss, dice_loss
8.1:首先对GT进行拉普拉斯卷积处理,然后再进行二值化为[0,1],
8.2:接着对GT再进行提边,步长分别为2,4,8。下采样完了之后再上采样,同样进行阈值处理,转换为二值图。
8.3:将boundary_targets, boundary_targets_x2_up, boundary_targets_x4_up图stack在一起,再压缩一个维度。然后再经过一个1x1卷积,进行loss计算。分别计算bce loss和dice loss。如何计算
9:train文件中
lossp = criteria_p(out, lb)
loss2 = criteria_16(out16, lb)
loss3 = criteria_32(out32, lb)
boundery_bce_loss = 0.
boundery_dice_loss = 0.
if use_boundary_2:
# if dist.get_rank()==0:
# print('use_boundary_2')
boundery_bce_loss2, boundery_dice_loss2 = boundary_loss_func(detail2, lb)
boundery_bce_loss += boundery_bce_loss2
boundery_dice_loss += boundery_dice_loss2
if use_boundary_4:
# if dist.get_rank()==0:
# print('use_boundary_4')
boundery_bce_loss4, boundery_dice_loss4 = boundary_loss_func(detail4, lb)
boundery_bce_loss += boundery_bce_loss4
boundery_dice_loss += boundery_dice_loss4
if use_boundary_8:
# if dist.get_rank()==0:
# print('use_boundary_8')
boundery_bce_loss8, boundery_dice_loss8 = boundary_loss_func(detail8, lb)
boundery_bce_loss += boundery_bce_loss8
boundery_dice_loss += boundery_dice_loss8
loss = lossp + loss2 + loss3 + boundery_bce_loss + boundery_dice_loss
loss.backward()
optim.step()
将三个深监督损失和两个细节损失加到一起进行一个反向传播。