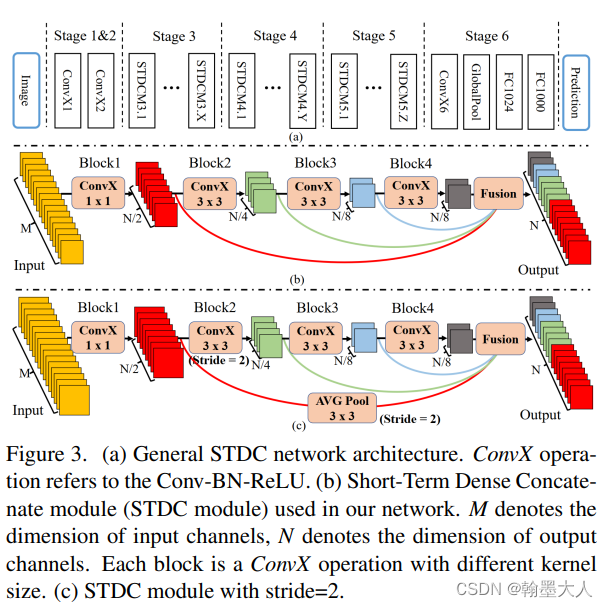
模型backbone:模型的backbone相比于分类架构是精心设计的,有点类似于densenet。
模型整体框架:
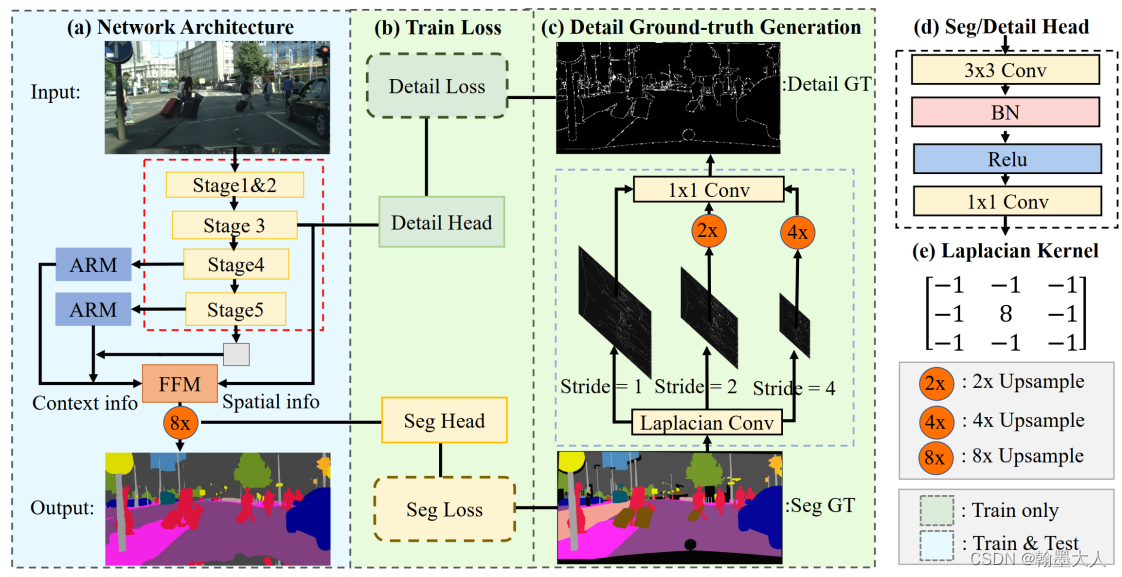
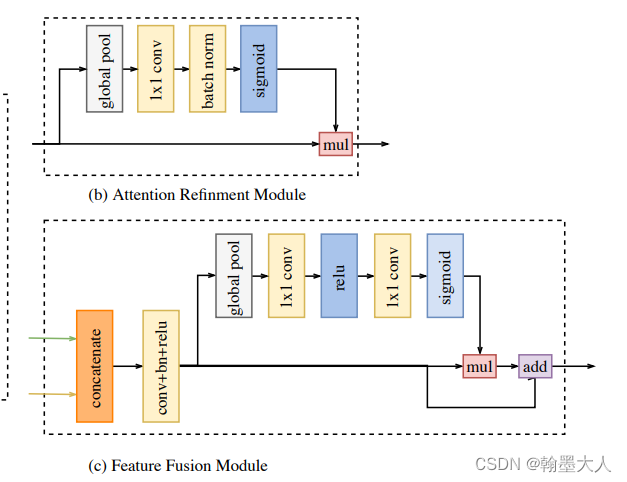
1:decoder整体设计部分,在stage5之后,使用一个全局平均池化去提供全局上下文信息,将最后一层的输出和stage4,5的输出结合起来,其中每两层使用Bisenet中的ARM模块。最后使用一个FFM模块融合stage3的空间信息并输出语义分割图。
encoder的stage3有丰富的细节信息,经过ARM后的decoder信息有丰富的上下文信息。:
2:seg head由3x3和1x1卷积组成。
3:低层特征的细节引导
下面的(b)图作为空间分支的可视化,可以编码更多的空间特征比如边界和拐角。因此作者提出细节引导模块,引导低层特征即stage3学习更多的空间信息。

作者对分割的GT进行拉普拉斯卷积处理,产生了细节GT。作者在stage3处插入了detail head,生成的细节图和细节GT进行损失计算,反向传播时更新detail head的参数,使其专注于细节的提取。
细节GT的产生:使用拉普拉斯卷积核对分割GT进行卷积,再通过一个1x1卷积用于权重调整。最后使用0.1阈值将细节GT二值化。
细节损失计算公式:dice loss + bce loss
detail head:3x3卷积后接1x1卷积得到细节图,细节loss在推理时不使用。
模型重绘:
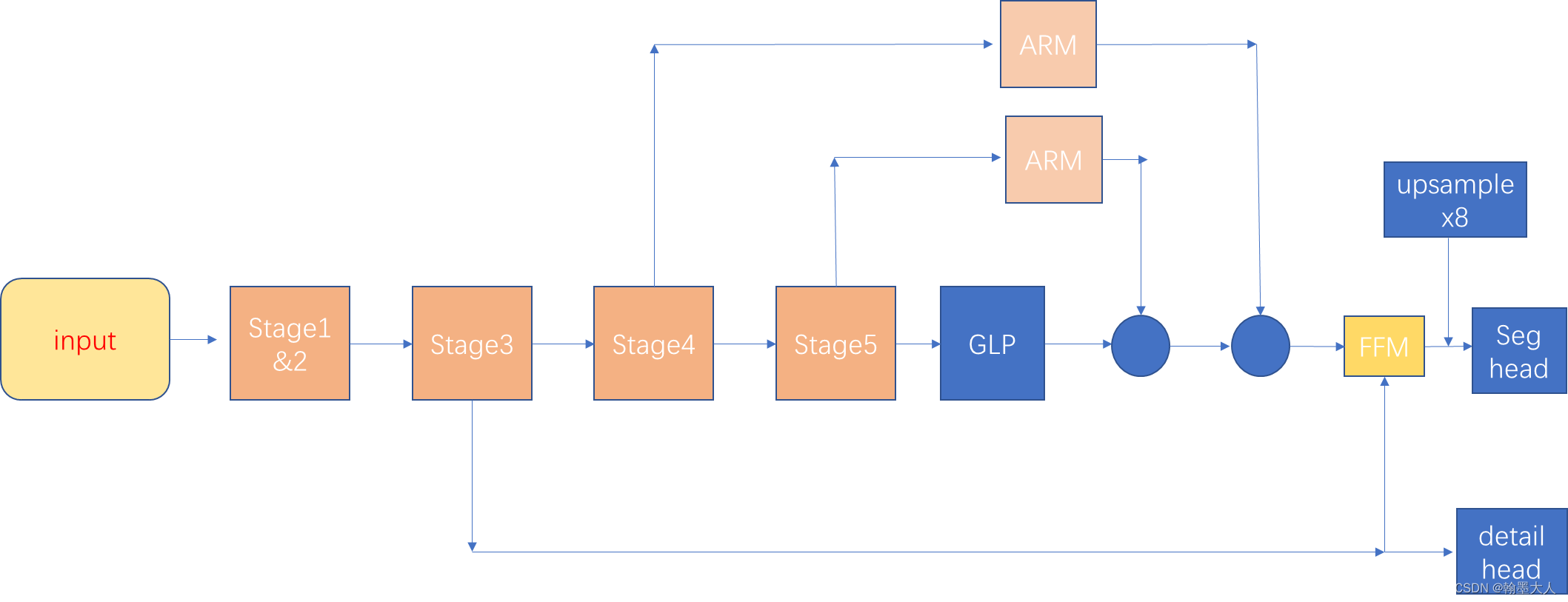
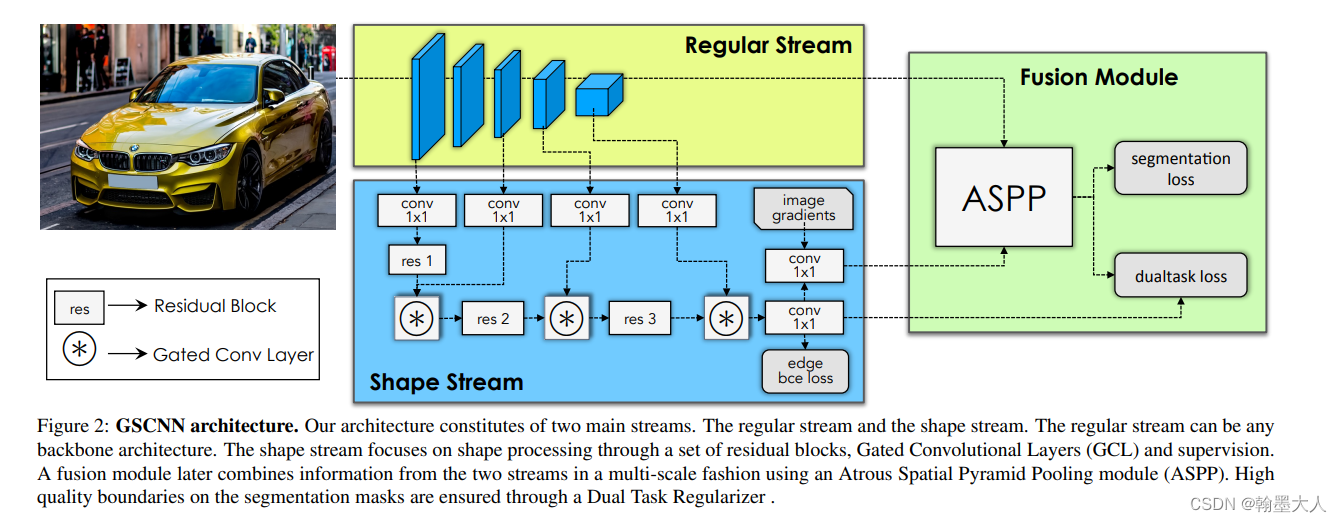
相比于gate-scnn结构:stage3并未经过一些列的卷积操作进行提取边界,而是使用backbone本身的卷积进行提边,且gate-scnn是边缘细节在decoder开始部分就融合进去了,而STDC是融合在decoder的tail部分。
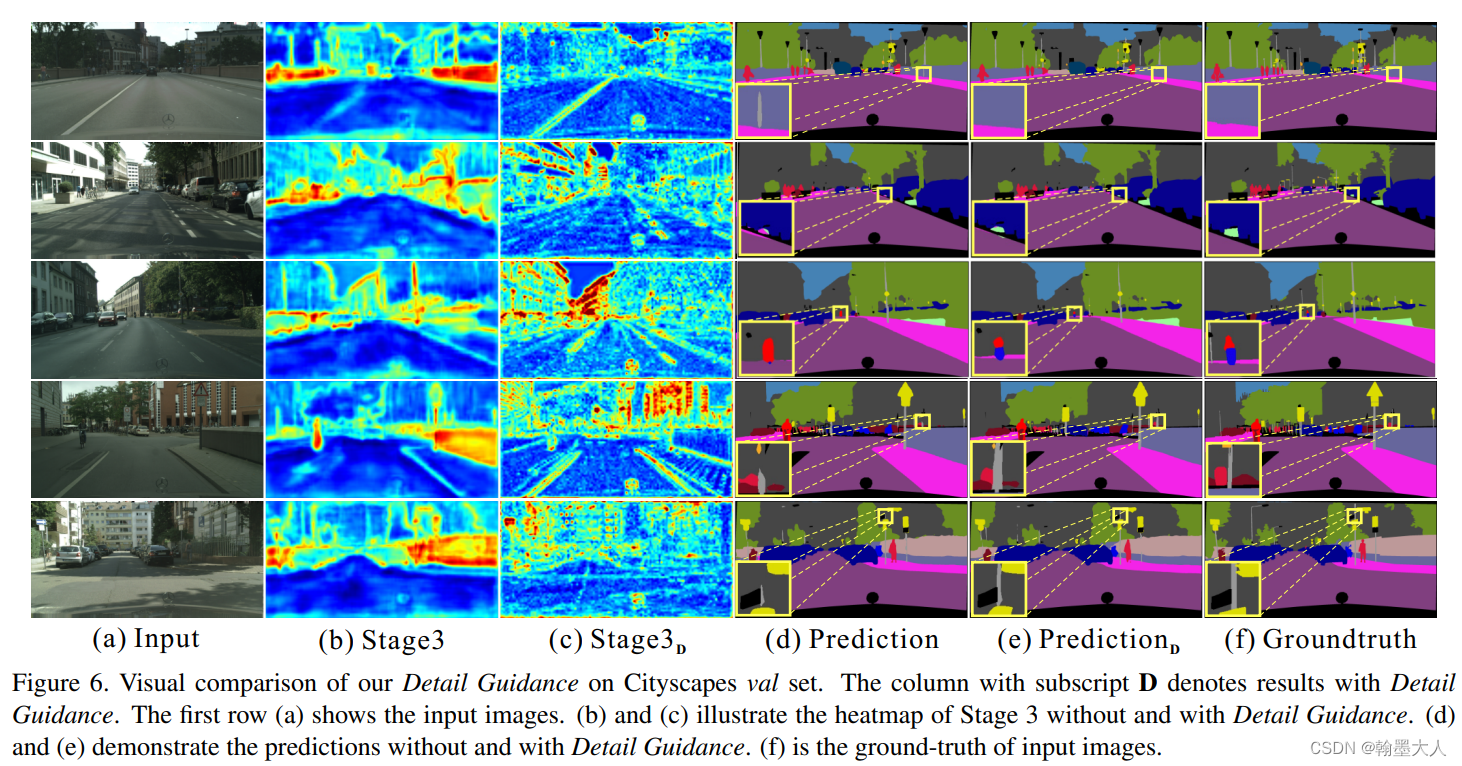
结果可视化: