论文笔记【1】:2018-[CVPR] MoNet: Deep Motion Exploitation for Video Object Segmentation
本文提出一个新的MoNet模型,从帧表示学习和分割细化两个方面深入挖掘运动信息来提高视频目标分割的准确性。MoNet利用计算的运动信息(即光流)通过对齐和整合来自相邻帧的特征来增强目标帧的特征表示。新的特征表示为分割提供了有价值的时间上下文,并提高了对各种常见干扰因素的鲁棒性。通过引入距离转换层(DT),MoNet可以有效地分割运动不一致的区域,并提高分割的准确性。
![Figure 1. Architecture of the proposed MoNet. The target frame and its two adjacent frames and are passed to a segmentation network [4] and a FlowNet [9] respectively. The features and from adjacent frames are aligned (by their corresponding optical flow and ) and combined with the target frame feature , giving a new feature . Based on , two separative branches segment the target frame into foreground and background mask. The distance transform layer maps the optical flow to motion prior, which is fused with the foreground/background mask to produce refined object segmentations. Best viewed in color.](https://img-blog.csdnimg.cn/20181211101138476.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3p4eDgyNzQwNzM2OQ==,size_16,color_FFFFFF,t_70)
MoNet的整体框架如Fig.1所示。输入为目标帧和随机的两个相近帧,将它们分别送到FlowNet[4]和分割网络[9],输出它们的外观特征和光流。利用计算出来的光流来对齐相邻帧的特征,然后将它们整合到目标帧特征中。采用合并特征,分割模型将目标帧分离为前景和背景掩模。为了降低临近物体的干扰,引入了距离变换层,将估计的光流映射到运动先验,过滤掉与目标对象运动不一致的区域。最后将运动先验与前景背景掩膜融合产生最后的分割结果。

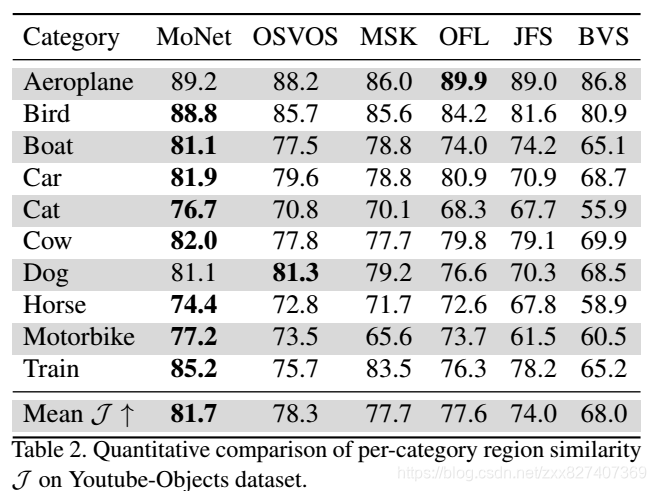
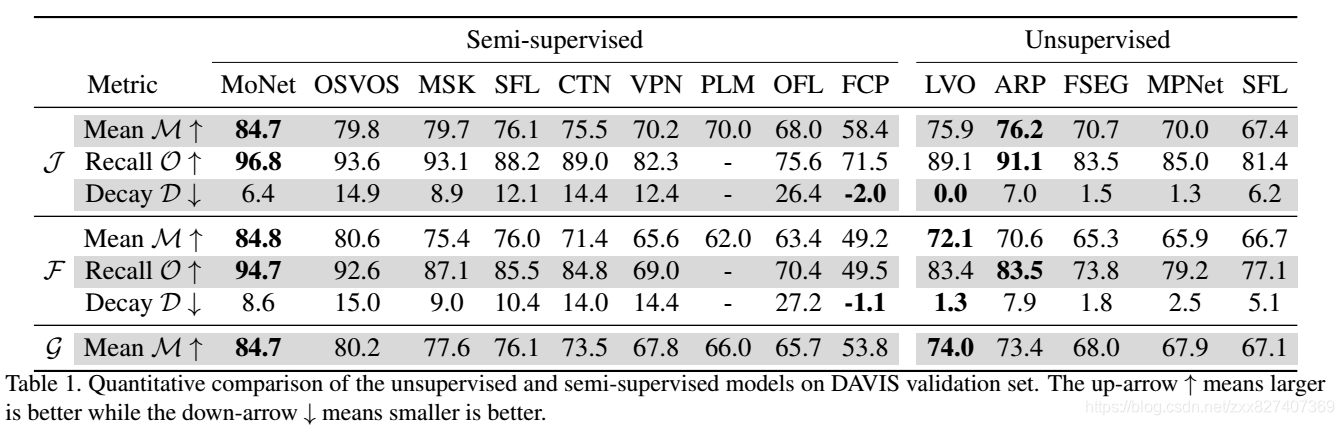
实验: