山东大学Python(人工智能)——实验
实验要求:
1.对机器学习的任何一种算法用sklearn和TensorFlow进行实现
2.要求:
a).数据源可利用现有的或自动生成样本数>=1000,属性数量不能小于5个
b).数据用NumPy或Pandas进行处理和存储,要有相应的预处理过程
c).数据要能完整体现数据处理的完整过程,
包括采集,预处理,训练,测试,评估,展示
这个实验我本想用MNIST数据集,后来发现这个数据集太基础了,接着我发现了CIFAR10数据集(如果不了解这个数据集,可以去网上搜,但别忘了回来呦),这个数据集还是很不错的,我用这个数据集作为我实验的数据集。我在网上找了很多代码,发现要么是代码有问题,无法运行;要么是过于复杂,照搬TensorFlow的GitHub源码;要么就是用了太复杂的函数。因此,我集百家之长,成一家之言。目前,这个实验就是在学校给老师展示的实验。
如果有什么建议,非常欢迎在评论区评论或者私信我
我的硬件环境:
电脑型号 THUNDEROBOT 911 笔记本电脑
操作系统 Windows 10 64位 ( DirectX 12 )
处理器 英特尔 Core i7-8750H @ 2.20GHz 六核
主板 THUNDEROBOT NL5T ( 300 Series 芯片组 Family - A30D )
内存 8 GB ( 三星 )
主硬盘 三星 MZVLW128HEGR-00000 ( 128 GB / 固态硬盘 )
显卡 Nvidia GeForce GTX 1060 ( 6 GB / 广达 )
显示器 友达 AUO60ED ( 15.5 英寸 )
声卡 瑞昱 @ 英特尔 High Definition Audio 控制器
网卡 英特尔 Wireless-AC 9560
我的软件环境:
Python 3.7
PyCharm 2019.3
# 我的存储目录是
# "Python实验\input.py"
# "Python实验\train.py"
# "Python实验\cifar-10-batches-py\"
我目前准确率最高的网络结构是:(不过这个模型当时没保存下来)
- Layer1 卷积+卷积+池化+lrn
- Layer2 卷积+卷积+池化+lrn
- Layer3 卷积+卷积+lrn+池化
- Layer4 dropout+全连接
- Layer5 dropout+全连接
- softmax
训练和测试次数在train.py(共170行)中的133行的train_iters和156行的test_iters,复制代码粘贴到你的编辑器上就能确定位置。
目前最高的准确率是运行5000次后的62.00%,运行时间1.79min/epoch
我目前的测试情况:
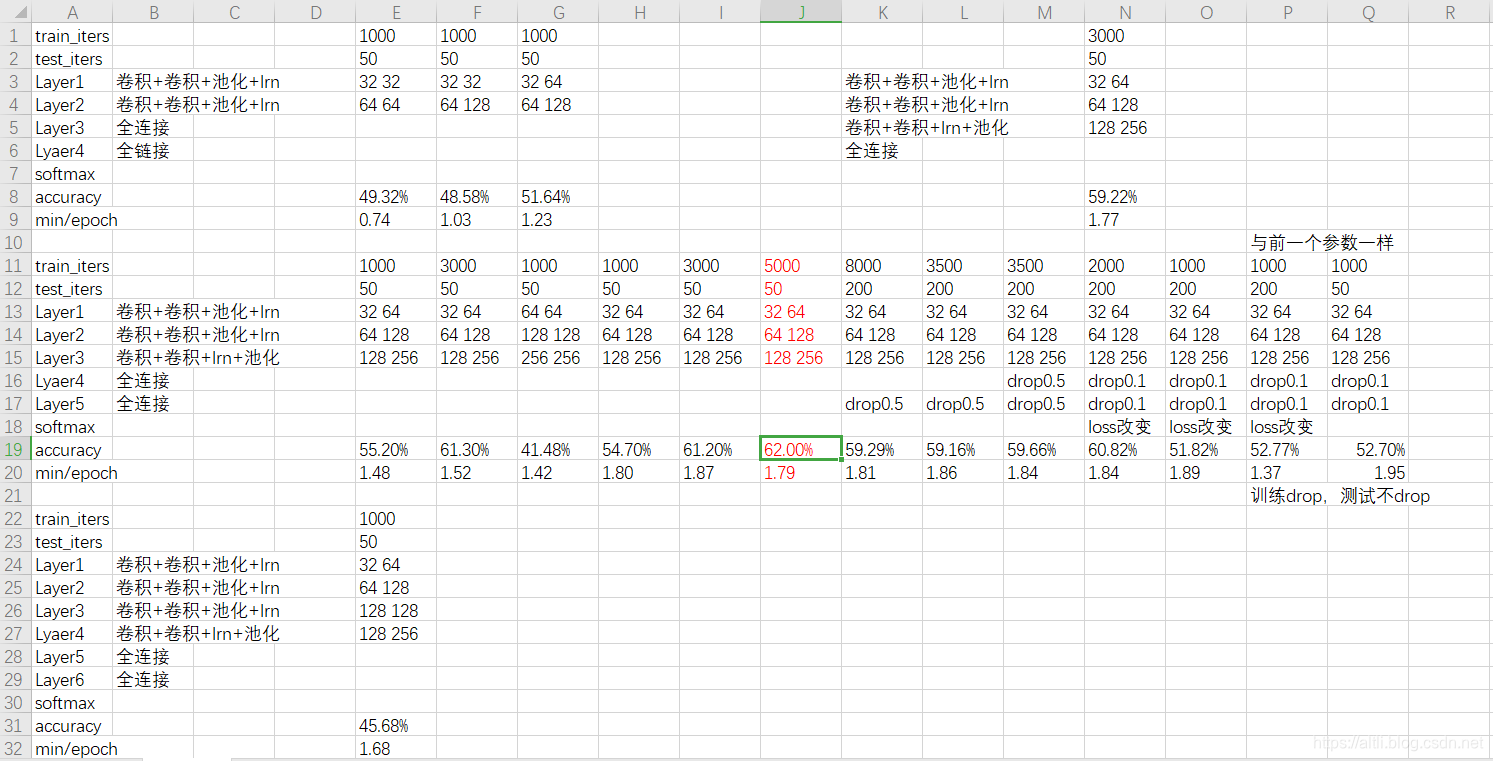
也就是说3个大卷积层的情况是最合适的
使用tensorboard可视化的结果是:
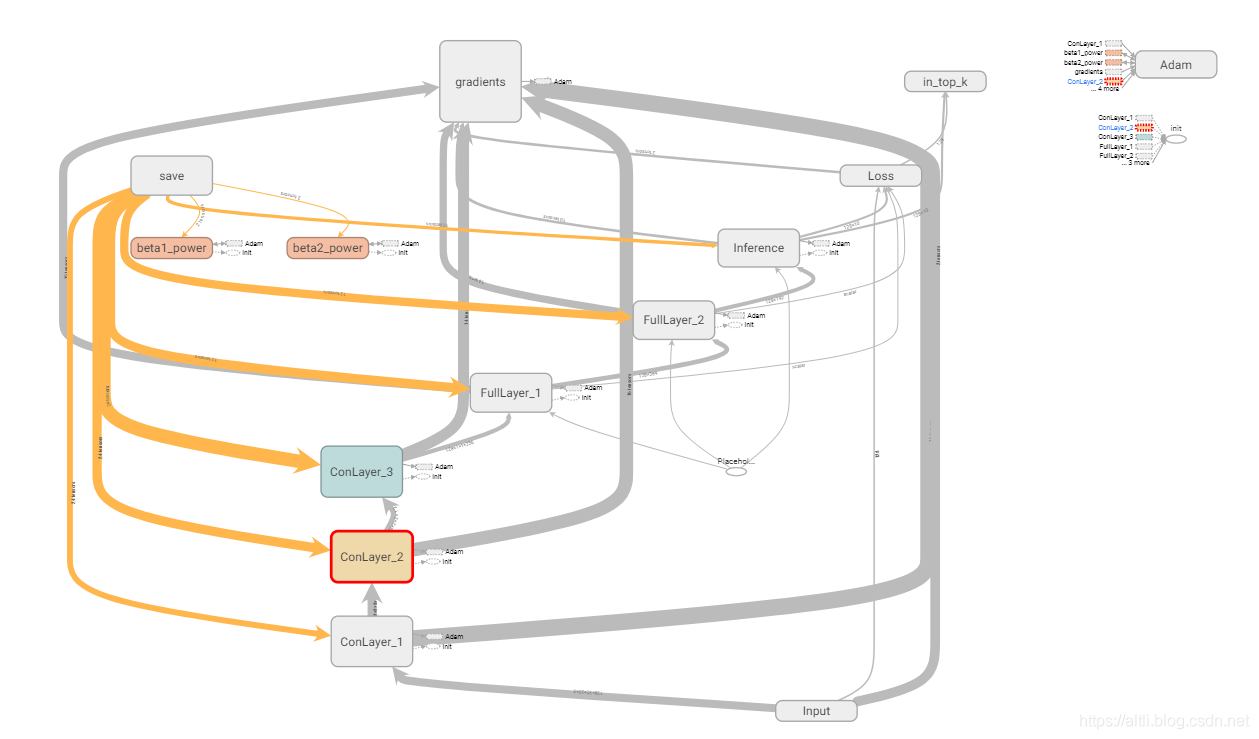
当然,使用tensorboard可视化之后,还包括5大层的参数的统计、直方图
完整实验代码:
TensorFlow版本是1.13.2,因为2.0版本及以上可能会有问题
代码分为两部分
- input.py:控制输入
- train.py:初始化,函数准备,网络,训练,输出,保存模型,tensorboard可视化
input.py
import pickle
import numpy as np
import random
def load(file_name):
with open(file_name, 'rb') as fo:
data = pickle.load(fo, encoding='bytes')
return data
def get_train():
data1 = load('cifar-10-batches-py\data_batch_1')
x1 = np.array(data1[b'data'])
x1 = x1.reshape(-1, 32, 32, 3)
y1 = np.array(data1[b'labels'])
data2 = load('cifar-10-batches-py\data_batch_2')
x2 = np.array(data2[b'data'])
x2 = x2.reshape(-1, 32, 32, 3)
y2 = np.array(data2[b'labels'])
train_data = np.r_[x1, x2]
train_labels = np.r_[y1, y2]
data3 = load('cifar-10-batches-py\data_batch_3')
x3 = np.array(data3[b'data'])
x3 = x3.reshape(-1, 32, 32, 3)
y3 = data3[b'labels']
train_data = np.r_[train_data, x3]
train_labels = np.r_[train_labels, y3]
data4 = load('cifar-10-batches-py\data_batch_4')
x4 = np.array(data4[b'data'])
x4 = x4.reshape(-1, 32, 32, 3)
y4 = data4[b'labels']
train_data = np.r_[train_data, x4]
train_labels = np.r_[train_labels, y4]
return list(train_data), list(train_labels)
def get_test():
data1 = load('cifar-10-batches-py\\test_batch')
x = np.array(data1[b'data'])
x = x.reshape(-1, 32, 32, 3)
y = data1[b'labels']
return list(x), list(y)
# 训练和测试时使用
def get_batch(batch_size, image, label):
batch_image = list()
batch_label = list()
indexs = list()
for i in range(batch_size):
index = random.randint(0, len(image) - 1)
while index in indexs:
index = random.randint(0, len(image) - 1)
d = list(image[index])
batch_image.append(d)
z = label[index]
batch_label.append(z)
indexs.append(index)
return batch_image, batch_label
train.py
import numpy as np
import tensorflow as tf
import matplotlib.pyplot as plt
import input
import time # 仅用在时间的统计上
def l2_weight_init(shape, stddev, w1):
weight = tf.Variable(tf.truncated_normal(shape, stddev=stddev))
if w1 is not None:
weight_loss = tf.multiply(tf.nn.l2_loss(weight), w1, name="weight_loss")
tf.add_to_collection("losses", weight_loss)
return weight
# 初始化权重
def weight_init(shape, stddev):
return tf.Variable(tf.truncated_normal(shape, mean=0, stddev=stddev))
# 初始化偏置
def bias_init(shape):
return tf.Variable(tf.truncated_normal(shape, mean=0, stddev=0.1))
# 构建卷机层
def conv2d(image, weight):
return tf.nn.conv2d(image, weight, strides=[1, 1, 1, 1], padding="SAME")
# 构建最大池化层
def max_pool(tensor):
return tf.nn.max_pool(tensor, ksize=[1, 2, 2, 1], strides=[1, 2, 2, 1], padding="SAME")
batch_size = 128 # 每次处理的大小
display = 100 # 每display次,输出1次,在训练时使用
# 抑制附近神经元防止过拟合
def LRnorm(tensor):
return tf.nn.lrn(tensor, 4, bias=1.0, alpha=0.001/9, beta=0.75)
# dropout防止过拟合
def dropout(tensor, rate):
return tf.nn.dropout(tensor, rate=rate)
# 计算准确性
def accuracy(test_labels, test_y_out):
test_labels = tf.to_int64(test_labels)
prediction_result = tf.equal(test_labels, tf.argmax(y_, 1))
accu = tf.reduce_mean(tf.cast(prediction_result, tf.float32))
return accu
# 用于tensorboard显示
def variable_summaries(var):
with tf.name_scope('summaries'):
# 计算参数的均值,并使用tf.summary.scaler记录
mean = tf.reduce_mean(var)
tf.summary.scalar('mean', mean)
# 计算参数的标准差
with tf.name_scope('stddev'):
stddev = tf.sqrt(tf.reduce_mean(tf.square(var - mean)))
# 使用tf.summary.scaler记录记录下标准差,最大值,最小值
tf.summary.scalar('stddev', stddev)
tf.summary.scalar('max', tf.reduce_max(var))
tf.summary.scalar('min', tf.reduce_min(var))
# 用直方图记录参数的分布
tf.summary.histogram('histogram', var)
with tf.name_scope('Input'):
image = tf.placeholder('float', [batch_size, 32, 32, 3])
label = tf.placeholder('float', [batch_size])
rate = tf.placeholder(tf.float32)
with tf.name_scope('ConLayer_1'):
w1 = weight_init([3, 3, 3, 32], 0.05)
variable_summaries(w1)
b1 = bias_init([32])
variable_summaries(b1)
conv1 = tf.nn.relu(conv2d(image, w1) + b1)
poola = max_pool(conv1)
w2 = weight_init([3, 3, 32, 64], 0.05)
variable_summaries(w2)
b2 = bias_init([64])
variable_summaries(b2)
conv2 = tf.nn.relu(conv2d(poola, w2) + b2)
pool1 = max_pool(conv2)
LRn1 = LRnorm(pool1)
with tf.name_scope('ConLayer_2'):
w3 = weight_init([3, 3, 64, 64], 0.05)
variable_summaries(w3)
b3 = bias_init([64])
variable_summaries(b3)
conv3 = tf.nn.relu(conv2d(LRn1, w3) + b3)
poolb = max_pool(conv3)
w4 = weight_init([3, 3, 64, 128], 0.05)
variable_summaries(w4)
b4 = bias_init([128])
variable_summaries(b4)
conv4 = tf.nn.relu(conv2d(poolb, w4) + b4)
pool2 = max_pool(conv4)
LRn2 = LRnorm(pool2)
with tf.name_scope('ConLayer_3'):
w5 = weight_init([3, 3, 128, 128], 0.05)
variable_summaries(w5)
b5 = bias_init([128])
variable_summaries(b5)
conv5 = tf.nn.relu(conv2d(LRn2, w5) + b5)
poolc = max_pool(conv5)
w6 = weight_init([3, 3, 128, 256], 0.05)
variable_summaries(w6)
b6 = bias_init([256])
variable_summaries(b6)
conv6 = tf.nn.relu(conv2d(poolc, w6) + b6)
LRn3 = LRnorm(conv6)
pool3 = max_pool(LRn3)
with tf.name_scope('FullLayer_1'):
reshape = tf.reshape(pool3, [batch_size, -1]) # 将每个样本reshape为一维向量
n_input = reshape.get_shape()[1].value # 取每个样本的长度
w7 = l2_weight_init([n_input, 384], 0.04, w1=0.004)
variable_summaries(w7)
b7 = bias_init([384])
variable_summaries(b7)
#drop7 = dropout(w7, rate)
full_1 = tf.nn.relu(tf.matmul(reshape, w7) + b7)
with tf.name_scope("FullLayer_2"):
w8 = l2_weight_init([384, 192], 0.04, w1=0.004)
variable_summaries(w8)
b8 = bias_init([192])
variable_summaries(b8)
#drop8 = dropout(w8, rate)
full_2 = tf.nn.relu(tf.matmul(full_1, w8) + b8)
with tf.name_scope('Inference'):
w9 = weight_init([192, 10], 1/64.0)
variable_summaries(w9)
b9 = bias_init([10])
variable_summaries(b9)
#drop9 = dropout(w9, rate)
logits = tf.add(tf.matmul(full_2, w9), b9)
y_ = tf.nn.softmax(logits)
with tf.name_scope('Loss'):
label = tf.cast(label, tf.int64)
cross_entropy = tf.nn.sparse_softmax_cross_entropy_with_logits(logits=logits, labels=label)
cross_entropy_mean = tf.reduce_mean(cross_entropy)
tf.add_to_collection('losses', cross_entropy_mean)
loss = tf.add_n(tf.get_collection('losses'), name='total_loss')
tf.summary.scalar('loss', loss)
merged = tf.summary.merge_all()
train_op = tf.train.AdamOptimizer(0.001).minimize(loss) # 定义优化器
top_k_op = tf.nn.in_top_k(logits, label, 1)
# 获取输出分类准确率最高的那个数,即将10个输出类别中概率最大的值的索引与label比较,相同为True,不同为False
saver = tf.train.Saver() # 生成saver用来保存模型
init = tf.global_variables_initializer()
sess = tf.Session()
summary_writer = tf.summary.FileWriter('./tmp/first', graph=tf.get_default_graph())
sess.run(init)
Cross_loss = [] # 存储每一个batch_size之后的损失函数的值
Train_accuracy = [] # 存储每一个batch_size之后的准确率
print("program begin")
train_image, train_label = input.get_train()
train_iters = 10000 # 训练次数
start = time.time() # 记录总时间
saver.restore(sess, "./save/model") # 会将已经保存的变量值resotre到变量中
for i in range(train_iters):
start_time = time.time() # 开始时间
batch_images, batch_labels = input.get_batch(batch_size, train_image, train_label)
_, cross_entropy = sess.run([train_op, loss], feed_dict={image: batch_images, label: batch_labels, rate: 0.5})
Cross_loss.append(cross_entropy)
duration = time.time()-start_time # 当前步所用时
if i % display == 0:
run_options = tf.RunOptions(trace_level=tf.RunOptions.FULL_TRACE)
run_metadata = tf.RunMetadata()
examples_per_sec = batch_size/duration # batchsize张图片/当前步所用时间=每秒钟训练多少张图片
sec_per_batch = float(duration)
summary, ys_train = sess.run([merged, top_k_op], feed_dict={image: batch_images, label: batch_labels, rate: 0.0},
options=run_options, run_metadata=run_metadata) # 计算当前准确率
summary_writer.add_run_metadata(run_metadata, 'step%03d' % i)
summary_writer.add_summary(summary, i)
temp_train = np.sum(ys_train)/batch_size
print("epoch:%4d , loss=%.3f(%.1f examples/sec;%.3f sec/batch) , now=%.3f min , accuracy=%.3f" % (
i, cross_entropy, examples_per_sec, sec_per_batch, (time.time()-start)/60, temp_train*100), "%", sep="")
count_train = 0
saver.save(sess, "./save/model") # file_name如果不存在的话,会自动创建
summary_writer.close() # 关闭summary_writer
end = time.time()-start
test_image, test_label = input.get_test()
count = 0
test_iters = 50 # 测试次数
for i in range(test_iters):
test_batch_image, test_batch_label = input.get_batch(batch_size, test_image, test_label)
ys = sess.run([top_k_op], feed_dict={image: test_batch_image, label: test_batch_label, rate: 0.0})
temp = np.sum(ys)/batch_size
count += temp
print("%4d: "%i, temp*100, "%", sep="")
print("average accuracy: ", count/test_iters*100, "% ", end/train_iters, " min/epoch", sep="")
sess.close()
fig, ax = plt.subplots(figsize=(13, 6))
ax.plot(Cross_loss)
plt.grid()
plt.title('Train loss')
plt.show()
print("program end")
运行之后出现下图情况很正常,忽略就可以:
上面的情况出现完之后,就会是正常的情况:
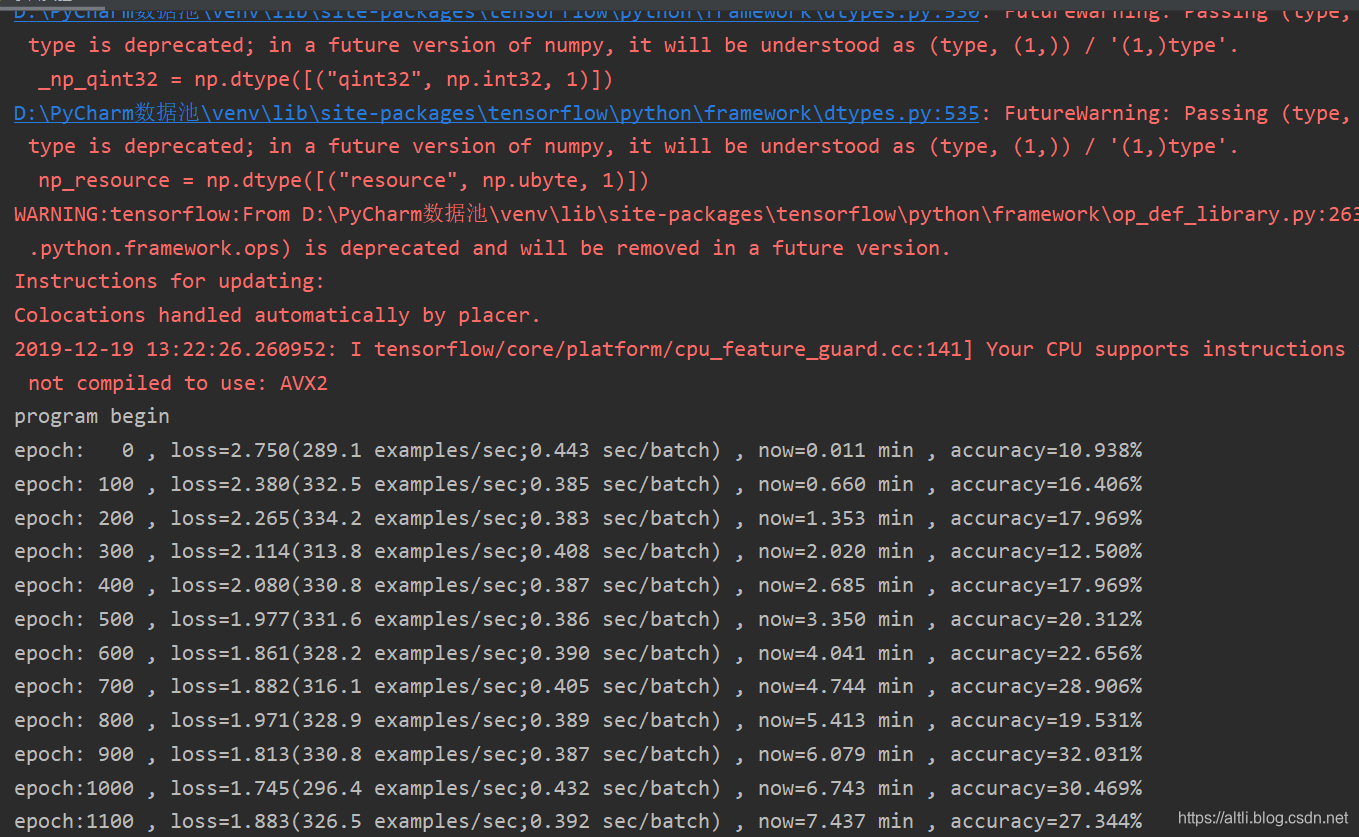
下面是损失函数值的变化
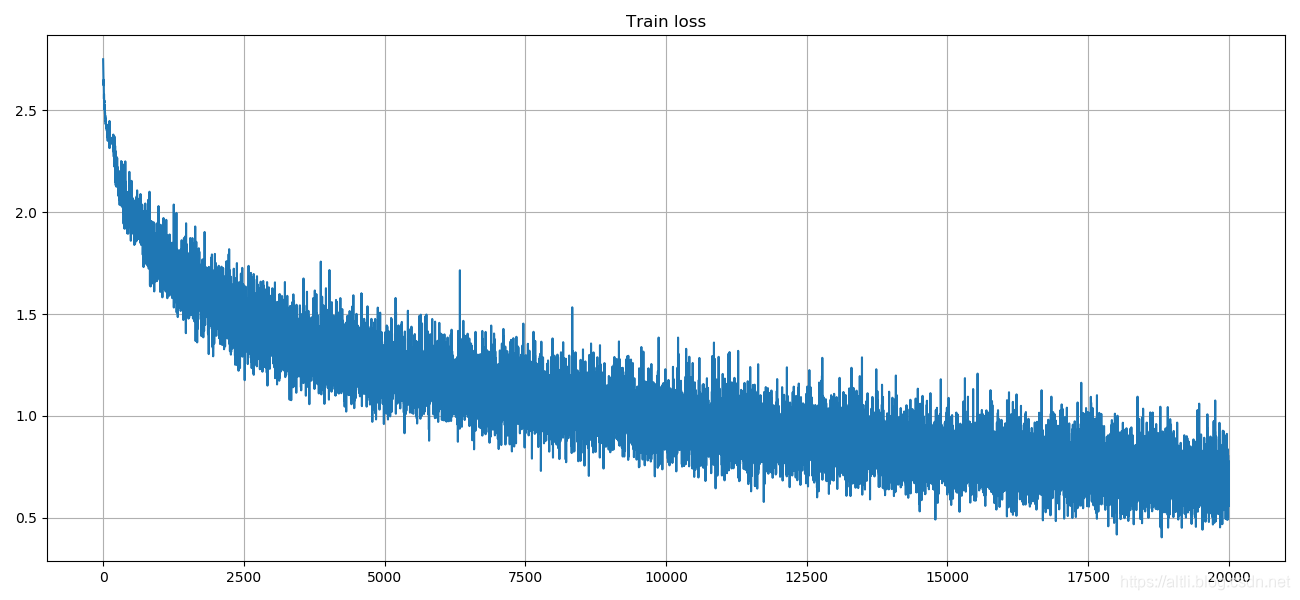
20000次迭代的结果是56%,当然由于能够打开保存的模型,可以继续训练下去,但准确率也不会有太大的变化。
总结
我认为,准确率在56%至62%间浮动,主要是因为数据的预处理问题。看了官网上的代码,她对图片进行了随机的旋转,归一化等操作,这极大的提高了模型的准确率。一个好的模型决定了成功的下限,好的数据决定了成功的上限。
