可以对比我之前发布的文章
1.BP神经网络预测(python)
2.lstm时间序列预测+GRU(python)
3. 数据集点击此处即可进行下载
这篇文章用的数据和我之前发布的BP神经网络预测用的数据一样
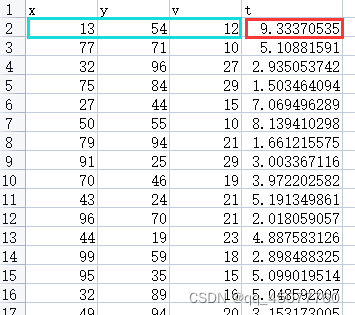
仍然是多输入单输出,也可以改成多输入多输出,下边是我的数据,蓝色部分预测红色(x,y,v为自变量,z为因变量)
直接上代码,有什么不明白的可以留言
#原始数据
import matplotlib
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
from tensorflow.python.layers.core import Dropout
import tensorflow
import sklearn.metrics
from IPython.core.display import SVG
from keras.layers import LSTM, Dense,Activation, Bidirectional
from keras.losses import mean_squared_error
from keras.models import Sequential
from keras.utils.vis_utils import model_to_dot, plot_model
from matplotlib import ticker
from pandas import DataFrame, concat
from sklearn import metrics
# from sklearn.impute import SimpleImputer
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from keras import regularizers
from sklearn.preprocessing import MinMaxScaler
#from statsmodels.tsa.seasonal import seasonal_decompose
import tensorflow as tf
import seaborn as sns
import os
os.environ['TF_CPP_MIN_LOG_LEVEL'] = '2'
matplotlib.rcParams['font.sans-serif'] = ['SimHei']
matplotlib.rcParams['axes.unicode_minus'] = False
data=pd.read_excel('2000.xls')
data = DataFrame(data, dtype=float)
data=data.iloc[:,:]
train_Standard = data.iloc[:1800,:]
test_Standard = data.iloc[1800:,:]
train_X,train_y = train_Standard.iloc[:,:-1],train_Standard.iloc[:,-1]
test_X,test_y = test_Standard.iloc[:,:-1],test_Standard.iloc[:,-1]
train_X, test_X=train_X.values, test_X.values
train_y, test_y=train_y.values, test_y.values
print(train_X.shape,train_y.shape) # (1500,3) (1500)
print(test_X.shape,test_y.shape) # (499,3) (499)
#归一化
MinMaxScaler = MinMaxScaler()
train_X=MinMaxScaler.fit_transform(train_X)
train_y = train_y.reshape(train_y.shape[0],1)
train_y=MinMaxScaler.fit_transform(train_y)
test_X=MinMaxScaler.fit_transform(test_X)
test_y = test_y.reshape(test_y.shape[0],1)
test_y=MinMaxScaler.fit_transform(test_y)
# reshape input to be 3D [samples,timeseps,features]
train_X = train_X.reshape((train_X.shape[0],1,train_X.shape[1]))
test_X = test_X.reshape((test_X.shape[0],1,test_X.shape[1]))
print(train_X.shape,train_y.shape,test_X.shape,test_y.shape) #(145, 1, 22) (145,) (38, 1, 22) (38,)
# 定义模型
model = Sequential()
model.add(Dense(32, input_shape=(train_X.shape[1], train_X.shape[2]),
#activity_regularizer=regularizers.l1(0.01),
#kernel_regularizer=regularizers.l2(0.01),
activation='relu'
)
)
#model.add(Dropout(0.5))
#model.add(Dense(32, activation='relu'))
#model.add(Dropout(0.5))
model.add(Dense(1,
activation='sigmoid'
))
model.compile(loss='binary_crossentropy',optimizer='rmsprop') # ,metrics=['accuracy']
# model.compile(loss='binary_crossentropy',optimizer='rmsprop')
#score = model.evaluate(test_X, test_y, batch_size=128)
# 拟合模型
batchsize = 10
history = model.fit(train_X, train_y, epochs=100, batch_size=batchsize, validation_data=(test_X, test_y))
model.summary()
model.save('mlp_model.h5')
# print(history.history.keys())
# plot history
#plt.subplot(len(groups),1,i)
plt.plot(history.history['loss'], label='train')
plt.plot(history.history['val_loss'], label='test')
plt.xlabel('epoch')
plt.ylabel('loss')
plt.title('batch_size = %d' %batchsize)
plt.legend()
plt.show()
# 预测测试集
xhat = model.predict(train_X)
yhat = model.predict(test_X)
train_X = train_X.reshape((train_X.shape[0], train_X.shape[2]))
test_X = test_X.reshape((test_X.shape[0], test_X.shape[2]))
# invert scaling for forecast
# invert scaling for actual
train_y = train_y.reshape((len(train_y), 1))
test_y = test_y.reshape((len(test_y), 1))
yhat = yhat.reshape(len(yhat),1)
yhat=MinMaxScaler.inverse_transform(yhat)
train_y=MinMaxScaler.inverse_transform(train_y)
test_y=MinMaxScaler.inverse_transform(test_y)
yhat = yhat.reshape((len(yhat), 1))
# calculate RMSE
yhat=yhat.ravel()
test_y=test_y.ravel()
mape = np.mean(np.abs((yhat-test_y)/(test_y)))*100
print('=============mape==============')
print(mape,'%')
# 画出真实数据和预测数据的对比曲线图
print("R2 = ",metrics.r2_score(test_y, yhat)) # R2
plt.plot(test_y,color = 'red',label = 'true')
plt.plot(yhat,color = 'blue', label = 'pred')
plt.title('Prediction')
plt.xlabel('Time')
plt.ylabel('value')
plt.legend()
plt.show()
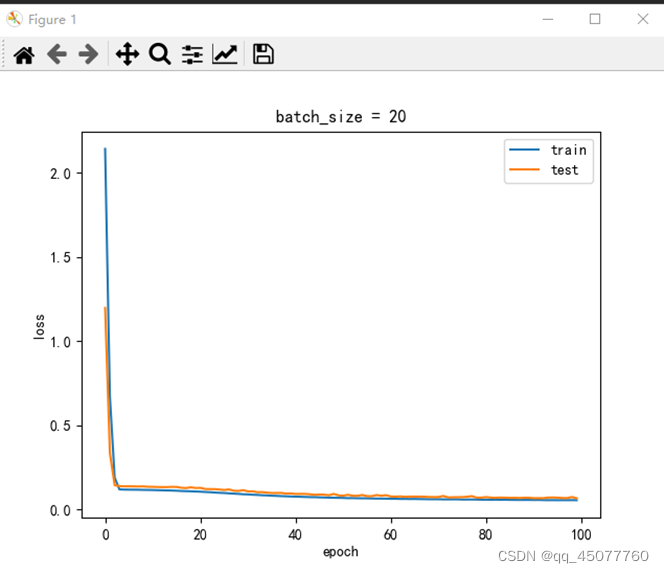
这是出来的训练集和测试集损失图
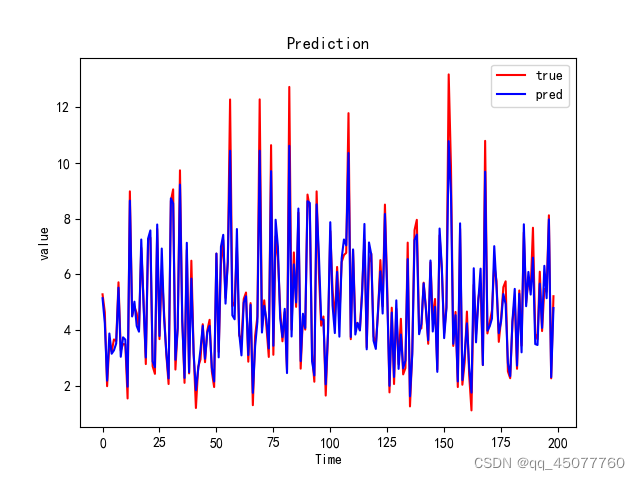
下边是预测值和真实值的结果图,其中
mape=6.7920069734065684%
R2 = 0.9597636539396392
可以加群:1029655667,进行沟通交流