多层感知器
多层感知器(Multilayer Perceptron,缩写MLP)是一种前向结构的人工神经网络,映射一组输入向量到一组输出向量。MLP可以被看作是一个有向图,由多个的节点层所组成,每一层都全连接到下一层。除了输入节点,每个节点都是一个带有非线性激活函数的神经元。使用反向传播算法的监督学习方法用来训练MLP。MLP是感知器的推广,克服了感知器不能对线性不可分数据进行识别的弱点。
多层感知器可以实现非线性判别式,如果用于回归可以逼近输入的非线性函数。且具有连续输入和输出的任何函数都可以用MLP近似。
具有一个隐藏层的MLP可以学习输入的任意非线性函数(隐藏节点个数不限)。
感知器
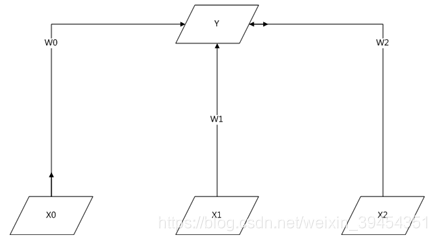
①感知器(Perception)是基本的处理元素,它具有输入、输出,每个输入关联一个连接权重(connection weight),然后输出是输入的加权和。上图就是一个单层的感知器,输入分别是X0、X1、X2,输出Y是输入的加权和:Y = W0X0 + W1X1 + W2X2,在实际的使用中,主要任务就是通过数据训练确定参数权重。在训练神经网络时,如果未提供全部样本而是逐个提供实例,则通常使用在线学习,然后在每个实例学习之后立刻调整网络参数,以这种方式使得网络缓慢得及时调整。具体收敛可以使用梯度下降算法。
②感知器具有很强的表现力,比如布尔函数AND和OR都可以使用上面的单层感知器实现。但是对于XOR操作则不行,因为单层感知器只能模拟线性函数,对于XOR这种非线性函数,需要新型的感知器。
多层感知器原理
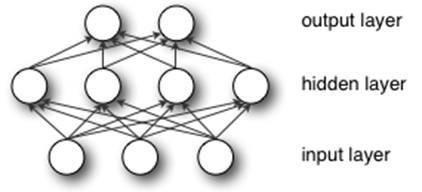
对于XOR这种非线性函数的模拟,需要采用多层感知器,即在最初的输入和输出层之间隐藏着一到多个层。
多层感知机也叫人工神经网络除了输入输出层,它中间可以有多个隐层,最简单的MLP只含一个隐层,即三层的结构如图。
多层感知机层与层之间是全连接的,多层感知机最底层是输入层,中间是隐藏层,最后是输出层。
①输入层:输入数据。

②隐藏层:首先它与输入层是全连接的,假设输入层用向量X表示,则隐藏层的输出就是f(W1X+b1),W1是权重(也叫连接系数),b1是偏置,函数f 可以是常用的sigmoid函数或者tanh函数:![]()
③输出层:隐藏层到输出层可以看成是多类别逻辑回归(softmax回归),所以输出层的输出就是softmax(W2X1+b2),X1表示隐藏层的输出f(W1X+b1)。
激活函数
若每个神经元的激活函数都是线性函数,那么,任意层数的MLP都可被约简成一个等价的单层感知器。
实际上,MLP本身可以使用任何形式的激活函数,但为了使用反向传播算法进行有效学习,激活函数必须限制为可微函数。由于具有良好可微性,很多S函数,尤其是双曲正切函数(Hyperbolic tangent)及逻辑函数,被采用为激活函数。
MLP所有的参数就是各个层之间的连接权重以及偏置,包括W1、b1、W2、b2。
求解最佳参数是最优化问题,解决办法使用梯度下降法了(SGD):首先随机初始化所有参数,然后迭代地训练,不断地计算梯度和更新参数,直到满足某个条件为止(比如误差足够小、迭代次数足够多时)。
这个过程涉及到代价函数、正则化、学习速率、梯度计算等。
softmax函数
如果有两个函数a和b,并且a>b。如果取max值那么直接选取a没有第二种可能,这样会造成分值小的一方饥饿。希望值大的一方经常取到但是分值较小的那一项也可以偶尔取到。
同样a和b,并且a>b。如果按照softmax值计算a和b的概率,由于a的softmax值>b的softmax值,则a会经常被取到而b也会偶尔被取到,概率跟他们本身的大小有关。