一、代码
# coding=utf-8
import pandas as pd # 用于分析数据集
import seaborn as sns # 可视化
import tensorflow as tf
import matplotlib.pyplot as plt # 可视化
import tensorflow.contrib.layers as layers
from sklearn import datasets # 用于获取数据集
from sklearn.preprocessing import MinMaxScaler # 用于数据归一化
from sklearn.model_selection import train_test_split # 用于划分训练集、测试集
# 数据集
boston = datasets.load_boston() # 读取波士顿房价,返回Bunch对象
df = pd.DataFrame(boston.data, columns=boston.feature_names) # 创建Pandas的数据结构DataFrame
df['target'] = boston.target
print(df.describe()) # 数据细节
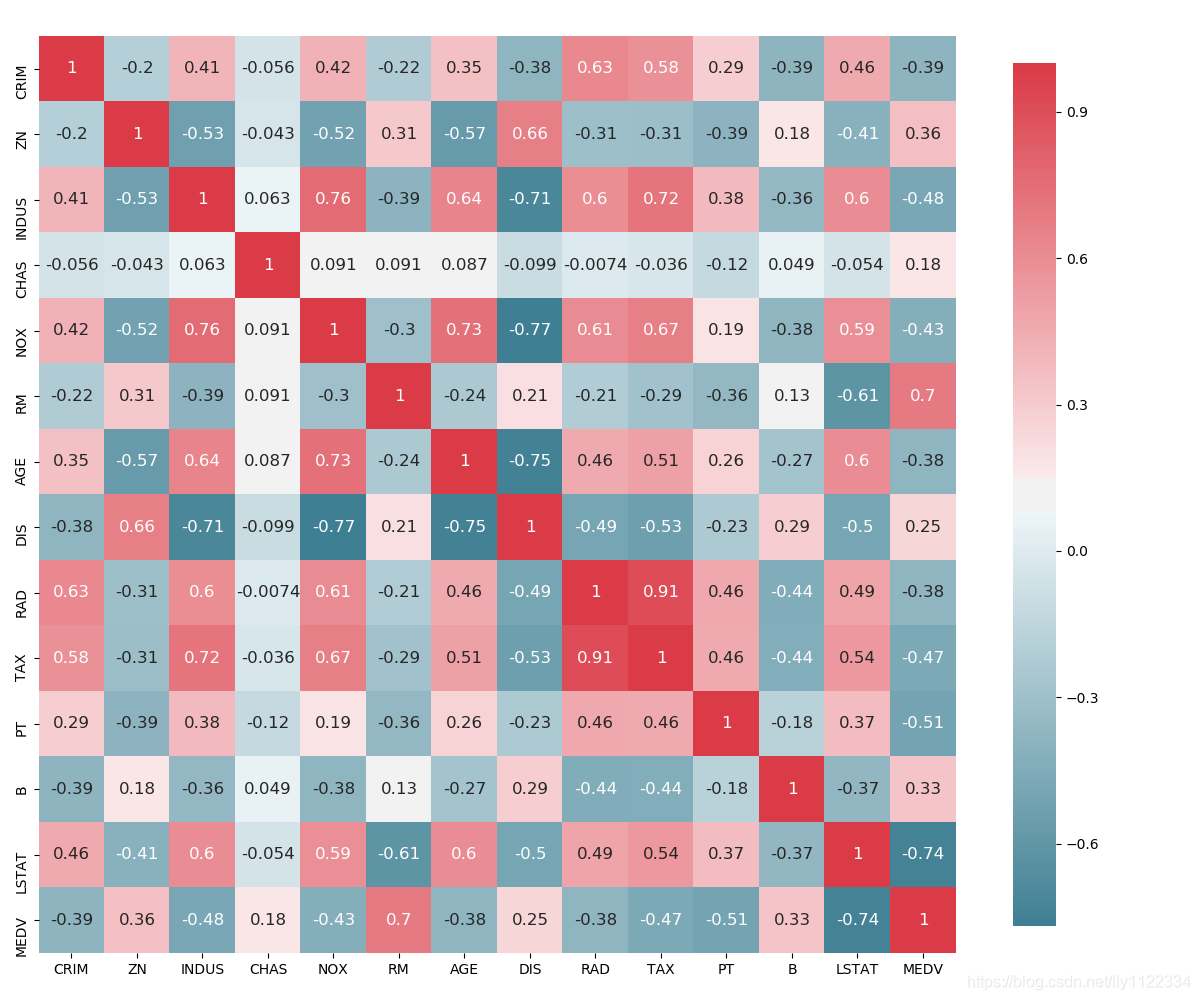
# 画图看特征间的线性相关性
_, ax = plt.subplots(figsize=(12, 10)) # 分辨率1200×1000
corr = df.corr(method='pearson') # 使用皮尔逊系数计算列与列的相关性
cmap = sns.diverging_palette(220, 10, as_cmap=True) # 在两种HUSL颜色之间制作不同的调色板。图的正负色彩范围为220、10,结果为真则返回matplotlib的colormap对象
_ = sns.heatmap(
corr, # 使用Pandas DataFrame数据,索引/列信息用于标记列和行
cmap=cmap, # 数据值到颜色空间的映射
square=True, # 每个单元格都是正方形
cbar_kws={'shrink': .9}, # `fig.colorbar`的关键字参数
ax=ax, # 绘制图的轴
annot=True, # 在单元格中标注数据值
annot_kws={'fontsize': 12}) # 热图,将矩形数据绘制为颜色编码矩阵
plt.show()
X_train, X_test, y_train, y_test = train_test_split(df[['RM', 'LSTAT', 'PTRATIO']], df[['target']], test_size=0.3,
random_state=0) # 创建训练集和测试集,测试集占0.3,随机种子0
X_train = MinMaxScaler().fit_transform(X_train) # 归一化,缩放到0-1
y_train = MinMaxScaler().fit_transform(y_train)
X_test = MinMaxScaler().fit_transform(X_test)
Y_test = MinMaxScaler().fit_transform(y_test)
m = len(X_train) # 训练集数
n = 3 # 特征数
n_hidden = 20 # 隐藏层数
batch_size = 200 # 每批训练批量大小
eta = 0.01 # 学习率
max_epoch = 1000 # 最大迭代数
# 定义模型
def multilayer_perceptron(x):
fc1 = layers.fully_connected(x, n_hidden, activation_fn=tf.nn.relu, scope='fc1') # 单隐藏层,激活函数为ReLU
out = layers.fully_connected(fc1, 1, activation_fn=tf.sigmoid, scope='out') # 输出层,激活函授为Sigmoid
return out
def accuracy(a, b):
correct_prediction = tf.square(a - b)
return tf.reduce_mean(tf.cast(correct_prediction, "float"))
x = tf.placeholder(tf.float32, name='X', shape=[m, n]) # 占位符
y = tf.placeholder(tf.float32, name='Y')
y_hat = multilayer_perceptron(x)
mse = accuracy(y, y_hat) # 均方差
train = tf.train.AdamOptimizer(learning_rate=eta).minimize(mse) # 优化器使用Adam优化算法
# 训练
init = tf.global_variables_initializer()
with tf.Session() as sess:
sess.run(init)
writer = tf.summary.FileWriter('graphs', sess.graph) # 将摘要与图形写入graphs目录
for i in range(max_epoch):
_, l, p = sess.run([train, mse, y_hat], feed_dict={x: X_train, y: y_train})
if i % 100 == 0:
print('Epoch {0}: Loss {1}'.format(i, l))
print("Training Done")
print("Optimization Finished!")
# 评估
print("Mean Squared Error (Train data):", mse.eval({x: X_train, y: y_train}))
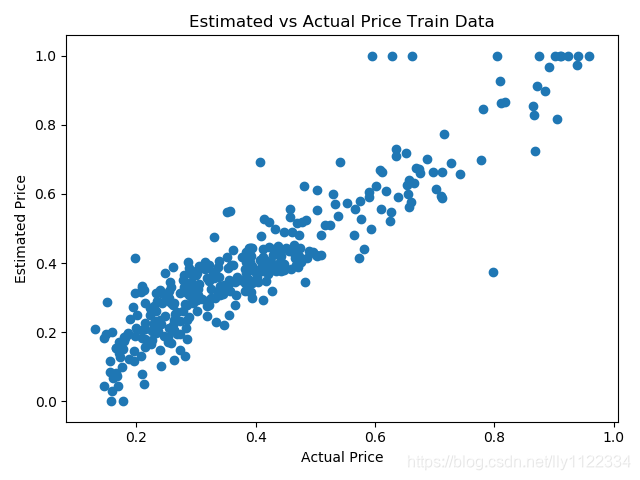
plt.scatter(p, y_train)
plt.ylabel('Estimated Price')
plt.xlabel('Actual Price')
plt.title('Estimated vs Actual Price Train Data')
plt.show()
writer.close()
二、结果
Mean Squared Error (Train data): 0.006424182