
论文作者 | Paul Wimmer,Jens Mehnert and Alexandru Paul Condurache
论文来源 | CVPR2022
文章解读 | William
一、摘要
非结构化的剪枝非常适合在训练和推理时减少卷积神经网络(CNN)的内存占用。标准的非结构化剪枝(Standard unstructured Pruning,SP)通过将滤波器元素设置为零来减少CNN的内存占用,因此需要一个固定的子空间来约束滤波器,如果在训练前或训练中进行修剪,则会导致剧烈的偏差。
为了克服这个问题,引入了空间剪枝(Interspace Pruning,IP),使用底层自适应滤波基底(adaptive filter basis,FB)的线性组合在动态空间中表示。IP和FB的系数均设为零,而未修剪系数和FB联合训练。
在这项工作中,以数学证据来证明IP的优越性能,同时证明了IP在所有测试过的最先进的非结构化修剪方法上优于SP,特别是在具有挑战性的情况下,如修剪ImageNet或修剪到高稀疏度,IP在相同的运行时间和参数成本下大大超过SP。最后,验证了IP的优越性归功于提高的可训练性和卓越的泛化能力
二、主要贡献
1. 结合FB系数对FB进行优化,在由可训练的FB跨越的线性空间中表示和训练卷积核
2. 提出了空间表示滤波器剪枝的理念,可作为提高稀疏系数CNN性能的通用方法
3. 阐述了IP改进的理论证明。
4. 实验表明,在训练期间或预训练模型上应用的SOTA稀疏训练方法和修剪方法上,在相同的运行时间和内存成本下,IP超过SP。此外,IP的优势可通过提高可训练性实现,在较低的稀疏度下也存在更好的泛化。
三、滤波依据和空间剪枝
3.1稀疏字典的启发
稀疏字典学习(Sparse Dictionary Learning,SDL)仅使用s个非零系数来优化字和系数来近似目标。
设置修剪掩码

来定义一个非凸优化问题:

(1)
通常,SDL允许中是任意M。由于FB是基底,故将F限制为平方式。这里的U对应于卷积层中所有扁平滤波器,字典F对应于该层的扁平FB,F和R是FB的系数。对于h层与相关的FB

,存在和。标准量级修剪是SDL的一种特殊情况,F固定形成标准基,因此:

由于是训练稀疏的、随机初始化的CNN,所以总体目标不是模拟给定的密集CNN,而是训练稀疏网络可以更好地泛化。因此,通过等式(1)和(2)来找到修剪系数的适当子集。与SDL相比,深度学习方法用于进一步优化未修剪的系数以及IP情况下的FB。等式(1)和(2)可以测量稀疏层和密集层的能力,分别是IP和SP总体性能的良好指标。
大多数SDL算法交替优化F和R。然而,SP-PaI将基底固定为和修剪掩码supp R。虽然简化了任务,但减少了解决方案空间。IP通过在训练期间调整基底,克服了固定的小解决方案空间。对于IP-PaI,剪枝掩码supp R是启发式的,也是固定的,这仍然导致是次优架构。
定理1.设0<s<m-n,且,设是等式(1)的下确界,是由 求解等式(2)的最小值。当P=1且 ,如果supp R固定,则等式(1)为 supp ,且 为真,且严格不等式适用于,其中:

(3)
定理1表明,动态F比使用标准基可以得到更好的近似。因此FBs的适应性提高了修剪的性能。假设卷积层具有输出和输入信道,内核大小是,是未修剪系数。对于,如果且,方程(3)中的\delta在数值上等于零。因此,对于每个整体的稀疏性,FB的自适应性提高了结果。如果等式(1)的修剪掩码被固定为等式(2)的最小值之一,即从任意修剪的网络开始并添加自适应FB总是改善结果,则这甚至成立。
如图1所示,比较了在CIFAR-10上训练的VGG16的随机初始化剪枝(PaI)的SP和IP。与SP相比,IP极大地提高了结果。这一实验表明,与修剪空间权重相比,修剪自适应FBs的系数时稀疏训练性能更好。即使使用了固定修剪掩码,这仍然适用。

图1 VGG16在CIFAR-10上随机SP-PaI和IP-PaI的表现
3.2空间表示与卷积
对于卷积层,让表示输出通道数,表示输入通道数,内核大小是。为了简化公式,将其限制为具有二次核、无填充、1x1步幅和扩张的二维卷积,以FB公式推广到任意卷积,描述该层的2D卷积

。受上一小节的启发,现在表示层的FB所跨越的空间中的是

。FB系数
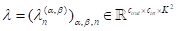
定义的空间表示为:

空间表示的基础转换为:
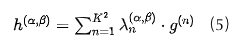
通常,定义在空间表示中。因此,空间系数存储在中。然而,FB系数由向量指定。
通过线性关系,2D的FB卷积,输入特征图可为每个输出通道计算:

(6)
使用损失L的梯度来训练FB系数λ和F。
3.3滤波器基底共享与初始化
对于1×1的卷积核,FB公式在一定程度上相当于空间表示。因此,假设给定具有K>1的Lc卷积层的CNN,并且不将FB公式应用于1×1卷积,分别测试三个版本的FB共享,发现FB共享方案在粒度上有所不同。
对于所有层,粗略方案共享一个全局FB。然而,精细方案为每层都共享一个FB ,因此它使用,中间是有5个FBs的中等方案。对于ResNet,5个卷积块中的每个块共享一个FB。对于VGG16,卷积层{1,2},{3,4},{5,6,7},{8,9,10}和{11,12,13}各自共享一个FB。FBs的数量从细增加到粗。网络中FBs的总数J满足J≤ Lc。因此,网络中所有FB的参数数量由限定。该参数量最多为模型中所有参数的0.01%,所以该共享方案中IP的额外参数成本是可以忽略的。
对于不同的FB共享方案,每个层所跨越的空间的维度不会改变,并且等于使用空间表示。然而,粗共享通过使用和更新相同的空间来关联网络中的所有层。为了实现精细共享,每个层都有自己的空间,该空间更细粒度。对于空间表示,基底是固定的且不引起权重之间的相关性。精细共享使网络更灵活,因此在网络不能再对训练数据进行过度拟合的情况下,结果是高修剪率的最佳结果。
3.4 空间剪枝和成本计算
SP通过叠加修剪掩模进行建模滤波器,这导致稀疏滤波器带有Hadamard乘积。空间中表示的滤波器具有系数,故通过用修剪掩模掩盖FB系数来定义空间修剪通过。结合等式(6),IP产生卷积的稀疏计算:

和数学公式: 的修剪率p定义为:
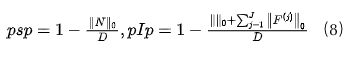
对于SP,表示网络的参数,其包含IP设置中除FBs自身之外的所有参数。因此,∧对于IP和SP具有完全相同的元素数量。修剪率等式(9)是等于零的参数分数。为了在IP和SP之间的进行公平比较,将非零参数的数量与标准密集网络(即没有FBs的密集网络)中的系数总数进行归一化,与卷积层和完全连接层相比,偏差和批量归一化参数的数量很少。此外,在实验中,FBs的所有参数加在一起最多为D的0.01%。因此,我们只修剪完全连接层的权重以及卷积层的空间和FB系数。FBs、偏差和批次标准化参数都经过训练。
计算成本比较。正如前面所叙述的,使用FB共享方案的IP的参数成本仅比SP的参数成本大得可以忽略不计。通过卷积的线性,可以使用空间中滤波器的稀疏性来降低计算成本,见等式(8)。成本通过卷积层理论上所需的浮点运算(FLOP)的数量来衡量,并且与所使用的FB共享方案无关。IP的开销由前向和后向传递中的额外成本组成。为了推断,只有前向传递的额外成本才算数。SP和IP都需要支持稀疏计算的专用软硬件,以实际减少运行时间。
四、实验和讨论
4.1初始化方法剪枝
实验表明,剪枝FB系数可以在相同内存消耗的情况下显著提高top-1测试精度,且适用于所有随机初始化剪枝方法,特别是高修剪率的。
与CIFAR-10相比,IP更能改善ImageNet的结果,而在ImageNet上ResNet18的随机初始化剪枝测试中,SNIP、GraSP和SynFlow三种方法的性能均优于随机初始化剪枝。这表明,这些方法在较小的数据集上表现良好,但在大型数据集(如ImageNet)上的小型网络上表现较差。如前所述,IP的使用显著改善了所有初始化剪枝方法,包括随机初始化剪枝。

图2 初始化剪枝(PaI)的SP和IP在CIFAR-10和ImageNet的SNIP、GraSP、SynFlow和随机PaI的对比
4.2泛化性和可训练性
泛化指正确分类不可见数据的能力。泛化差距是训练精度和测试精度之间的差异。可以通过正则化来提高泛化性,使模型能够使用关于场景的几何先验知识,将模型移回泛化良好的区域,同时也可以通过修剪网络。
表1显示了在CIFAR-10上VGG16的SP-SET和IP-SET的训练和测试精度,以及对于ImageNet上ResNet50的RigL方法。IP修剪网络对所有修剪率p的训练都比SP修剪网络好。对于ImageNet,在CIFAR-10上p = 0.99, IP的泛化差距大于SP。这是由于IP有更好的训练精度,最终导致了测试精度的提高。然而,在模型过拟合的CIFAR-10上,当p = 0.85时,IP的泛化差距小于SP。
表1 不同剪枝方法的泛化性研究
表2进一步表明,在训练过拟合的情况下,IP通常可以提高修剪率的结果(p = 0为密集训练,p = 0时SP为标准密集训练)。假设通过FB共享在CNN中关联过滤器可以正则化训练,从而改善泛化,这方面的指标是通过粗共享将所有滤波器显示出最佳结果,而细共享具有与SP相当的结果。
因此,空间表示也可以用于正则化密集训练,即使是在ImageNet上的ResNet50。经过训练后,密集的空间表示可以转换为标准的空间表示,以减少推理的计算成本。通过优化权值衰减和初始化方案,IP的性能可以进一步提高。
表2 不同的FB共享方案对降低修剪率p的影响

五、结论与未来工作
与修剪空间系数相比,IP显著改善了结果。通过将IP应用于SOTA标准初始化剪枝、LT、DST以及经典修剪方法来实现SOTA结果,从而证明了这一点。定理1证明,IP有着比SP更好的稀疏近似,而且生成的模型比SP具有更高的稀疏性和同等的性能。此外,与FB共享相结合提高了过度拟合CNN的泛化能力,即使是密集训练,这使得训练中的推理和额外梯度计算的计算开销很小。然而,稀疏空间表示比SP更能保持甚至提高基线的性能。
通过将SDL的更高级策略应用于F和λ的联合训练,可以增强IP。IP适应结构化修剪是保持网络准确性同时减少任意软硬件推理时间的一种选择, IP与低秩张量的近似相结合也降低了计算成本。因此,FB不限于表示卷积核,而是可以表示任意向量,如矩阵的列或小块。这使得IP的理念可用于MLP或自注意力模块。
ABOUT
关于我们
深蓝学院是专注于人工智能的在线教育平台,已有数万名伙伴在深蓝学院平台学习,很多都来自于国内外知名院校,比如清华、北大等。