为了进一步提高LMS算法的稳定性,在LMS基础上提出了块处理LMS(Block LMS)。LMS算法是每来一个采样点就调整一次滤波器权值,也就是每来一个样点,就更新一次权重,这样子就导致了权重的更新频率过快,从而导致收敛速度慢且不稳定;而BLMS算法是每K采样点才对滤波器的权值更新一次,类似于神经网络的batch_szie,收集一组数据(L个样点),计算误差的均值,再进行更新,也就是每来L个样点,权重更新一次。
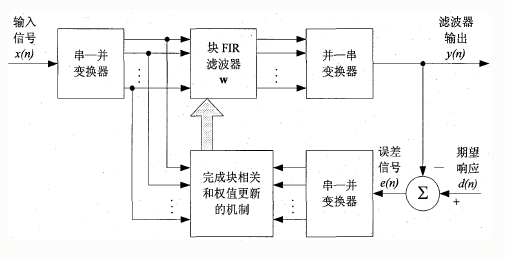
分块自适应滤波器的原理图
输入数据序列经过串一并变换器被分成若干个长度为L的数据块。然后将这些数据块一次一块的送入长度为M的滤波器中,在收集到每一块数据样值后,进行滤波器抽头权值的更新,使得滤波器的自适应过程一块一块地进行,而不是像时域传统自适应滤波算法那样一个值一个值地进行。
具体算法如下:
累积L个采样点之后,我们再更新一次滤波器系数
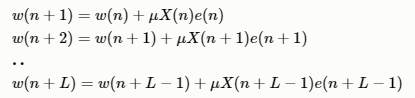
上式全部相加,中间的式子可以左右相消,就可以得出Block LMS滤波器权重的更新公式:

其中,μ为步长因子,为了推导方便,我们通常令L=N,更新一次block LMS相当于LMS更新了L倍。我们用一个新的时间索引k来代表Block LMS系数的更新,其中kL=n,上式可以写为:
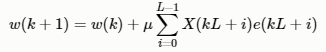
另一种公式写法:

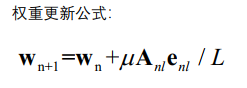
- 优点:运算量就比LMS的运算量要小的多
- 缺点:收敛速度却与LMS算法相同
MATLAB代码如下:
% 参考:https://github.com/Morales97/ASP_P2/blob/4a6a17f6fe/algorithms/block_lms.m
function [e, y, w] = myBlock_LMS(d,x,mu, M,L)
% 输入:
% d - 麦克风语音
% x - 远端语音
% mu - 步长
% M - 滤波器阶数
% L - 块大小
%
% Outputs:
% e - 输出误差,近端语音估计
% y - 输出系数,远端回声估计
% w - 滤波器参数
d_length = length(d);
K = floor(d_length / L); % 块的数量,确保整数
y = zeros(d_length, 1);
w = zeros(M,K+1);
e = zeros(d_length,1);
x_ = [zeros(M-1,1); x];
% 根据"块"进行循环
for k=1:K
block_sum = 0;
% 求一个块的和sum
for i = 1 + L*(k-1):L*k
X = x_(i:i+M-1);
y(i) = w(:,k)' * X; % 滤波器输出
e(i) = d(i) - y(i);
block_sum = block_sum + X * e(i); % 权重更新
end
w(:,k+1) = w(:,k) + mu * block_sum;
end
% 将指针移动一步,使第n行对应于时间n
w=w(:,2:K+1);
end
参考链接: